上海期智研究院PI,上海交通大学计算机科学与工程系教授。
2016年12月毕业于德州大学奥斯汀分校电子与计算机工程系并获得博士学位。2010年7月毕业于上海交通大学,获得学士学位。博士期间主攻方向为GPU处理器的体系结构优化,目前主持一项自然科学基金青年基金(2017年)和多项合作课题,入选2018年微软亚洲研究院青年学者铸星计划。
个人荣誉
获得2020年阿里巴巴达摩院青橙奖
PACT“20”最佳论文提名奖
计算机体系结构:下一代计算机系统的软硬件设计
大语言模型软硬件协同设计:降低大语言模型的计算和存储需求
成果4:基于数学自适应数值类型的大模型低比特量化(2025年度)
冷静文团队提出了一种面向大模型的新型数学自适应数值类型(M-ANT),显著提升细粒度组量化在推理过程中的性能与灵活性。团队深入分析大模型中不同组间分布差异较大的现象,发现现有的自适应数据类型难以满足小粒度组内的分布变化。为此,团队设计了M-ANT编码范式及解码-计算融合机制,并开发出组级数据类型自动分配框架以及实时量化机制。通过构建专用PE硬件单元与脉动阵列集成,该系统统一支持权重量化与KV cache量化。在多种大模型任务上,系统平均加速达到2.99倍,最高可达4.46倍,同时能耗降低最高达4.10倍,优于现有最先进的加速器方案。
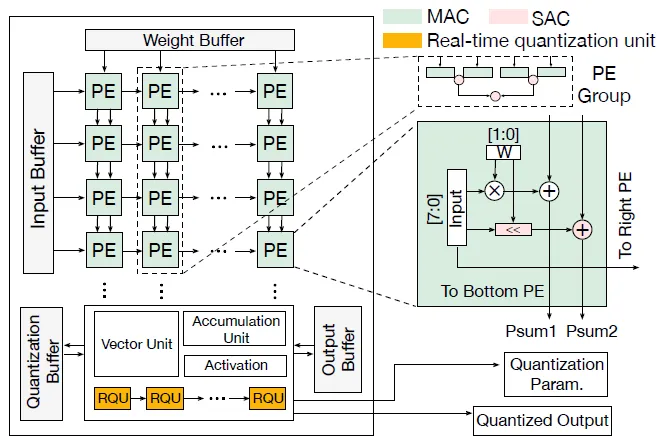
图. 支持M-ANT解码与实时量化的硬件架构
------------------------------------------------------------------------------------------------------------------------------
成果3:向量量化大模型的高性能推理算子代码生成 VQ-LLM(2025年度)
随着大语言模型的快速发展,算法研究者逐渐开始探索向量量化(Vector Quantization,VQ)的应用。VQ方法虽能大幅压缩模型权重和KV缓存(内存占用降低至1/8),但由于编码本访问效率低与计算数据流不协调,实际推理延迟反而可能高于FP16基线。冷静文团队提出向量量化(Vector Quantization)大模型的高性能算子生成系统,成功地将向量量化的大模型推理性能提高到工程可用的水平,在提供与传统量化方式相似的加速比的同时,显著提高量化质量。团队细致分析目前向量量化推理的瓶颈,发现其编码本在存储和计算层面为高性能算子生成带来了较大的挑战。为此团队提出了一套向量量化编码本感知的代码生成框架,由编码本缓存和编码本中心计算引擎组成。在多种大模型的算子上,系统显著降低50%的延迟,相比现有开源实现有百倍提升。
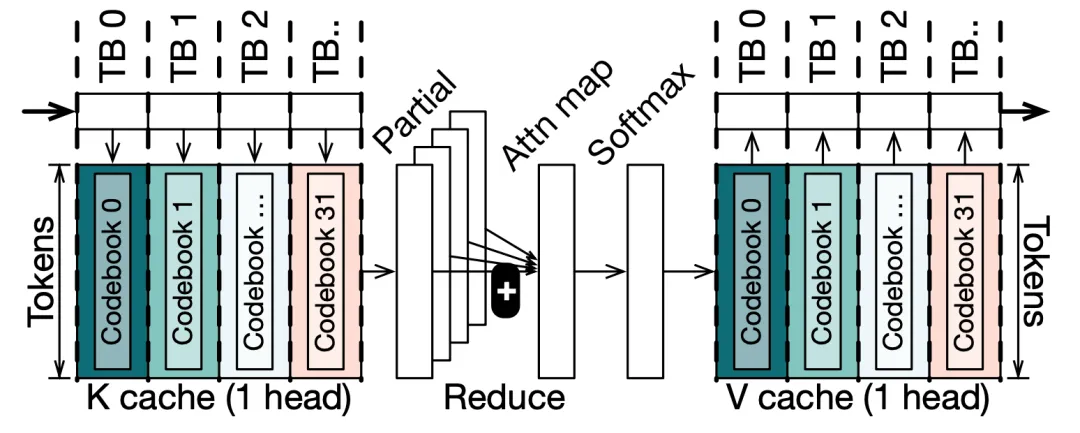
图. 基于CQ配置的注意力机制(解码)计算中以码本为核心的数据流示例
------------------------------------------------------------------------------------------------------------------------------
成果2:基于数据流优化的大模型高效支撑技术研究
随着ChatGPT等生成式大模型的迅速发展,以及其在诸多生产任务上的应用,产生了许多不同的模型变种和在不同细分领域的专用模型,这促使为大模型训练及推理提供支撑的软件框架需要不断地向更灵活、更高效的方向发展。为此,冷静文团队在针对大模型支撑框架,基于其执行数据流的组件化扩展设计方法开展了一系列研究。首先,为降低大模型数据流中算子中的计算和存储需求,我们对其进行了横向扩展,引入了三个核心组件,包括低位宽算子组件、稀疏算子组件和近似检索算子组件。为了方便开发者使用这些算子,我们进一步在数据流计算图级别做了横向扩展,引入了面向神经网络数据流分析优化的插桩接口组件、低位宽模型加速组件、以及稀疏模型加速组件。除了横向扩展现有支撑框架的能力之外,大模型与图计算的融合以及高并发大模型计算等场景的出现也使得我们必须对大模型支撑框架的能力进行纵向扩展。为此,我们也在数据流算子级和数据流计算图级分别扩展了现有大模型支撑框架的能力。总之,随着大模型的发展,我们需要更加灵活和高效的框架。通过对框架进行组件化扩展,并提供平台,使研究者和开发者能够针对特定问题定制和优化其解决方案。
基于这一系统和研究理念,团队系统性的研究了基于数据流和底层算子的各种优化组件,并在2023年发表了5篇顶会论文,申请了10项专利,开源了相关研究成果(https://github.com/SJTU-ReArch-Group)。
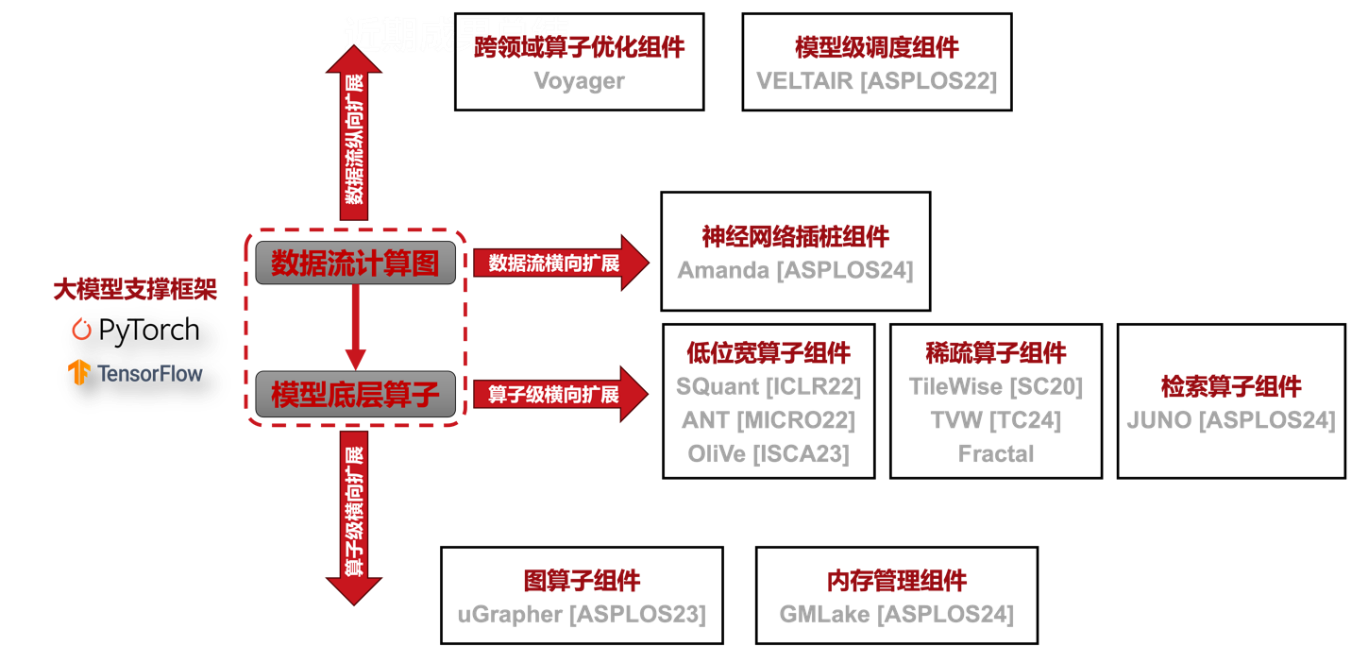
图. 针对大模型的高效支撑框架
------------------------------------------------------------------------------------------------------------------------------
成果1:基于数据流分析的深度学习软硬件协同新范式
以ChatGPT为代表的近期研究表明深度学习模型的通用性随着其模型规模不断增长,这使得其算力需求以每3个月翻倍的速度不断增长。然而,处理器架构遵循摩尔定律,仅能提供2年翻倍的性能增长,远远落后于算力需求。因此,冷静文团队进行了面向深度学习的“算法-软件-硬件”新型处理范式研究。针对现有TensorFlow、PyTorch等编程框架的代码跨模型移植性低的问题,团队借鉴了程序分析中的插桩系统设计,提出了面向神经网络数据流图的插桩系统Amanda,使用了op(一种多输入多输出的函数抽象)作为跨框架与执行模式的统一抽象,从而在底层机制层面保证了数据流分析代码的可移植性,极大地便利了数据流分析程序的开发。基于这一系统和研究理念,团队系统性的研究了神经网络可解释性、性能精度、可观察性等关键问题,发表了10篇顶会论文,申请了10项专利,开源了8项相关研究成果(https://github.com/SJTU-ReArch-Group)。
在上述研究成果中,基于数据流分析所研制的面向大语言模型的低位宽量化技术发表于2022年体系结构顶级会议MICRO,并获得当年年度最佳论文(IEEE Micro Top Picks)的优胜奖;该研究成果也获得了华为公司颁发的火花奖,已启动与其的学术合作项目,有望落地于其下一代AI芯片。研究院PI冷静文也于2020年获得阿里巴巴达摩院所颁发的青橙奖,已经获得2022年自然科学基金委的优青项目资助。
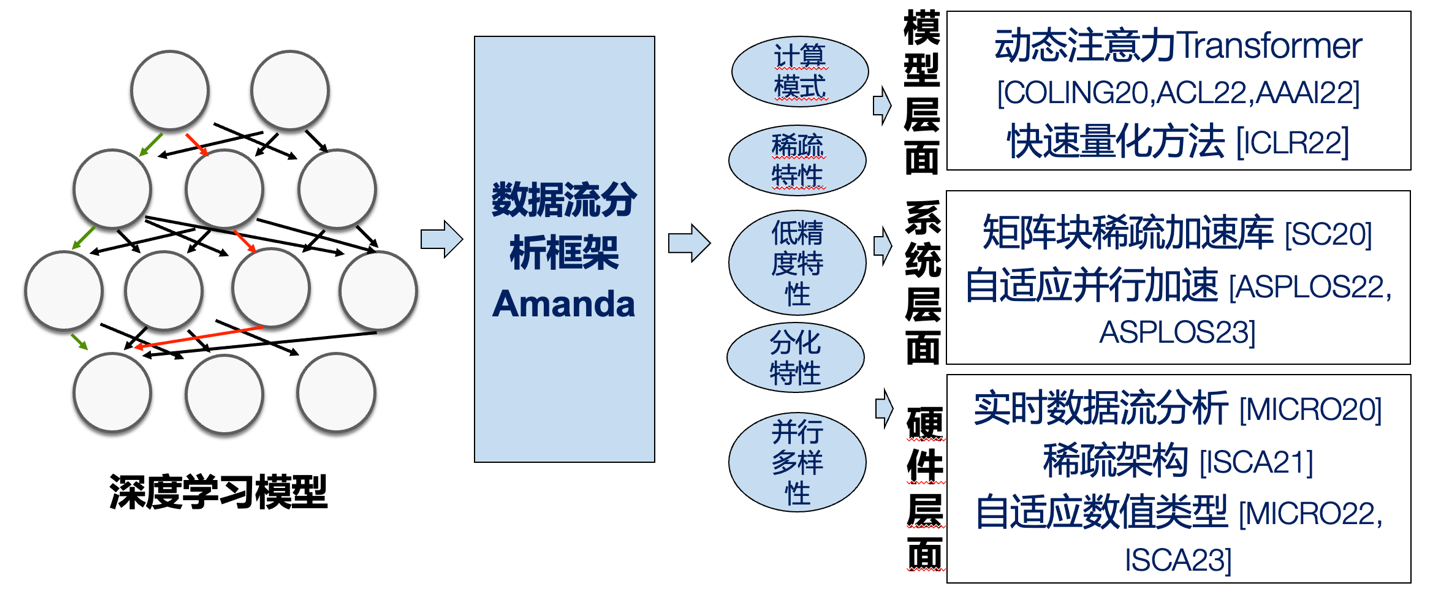
Figure 1利用数据流分析,充分发掘深度模型的计算特性,指导硬件、系统、模型的设计


1. Cong Guo, Yuxian Qiu, Jingwen Leng, Xiaotian Gao, Chen Zhang, Yunxin Liu, Fan Yang, Yuhao Zhu, Minyi Guo,SQuant: On-the-Fly Data-Free Quantization via Diagonal Hessian Approximation,2022 International Conference on Learning Representations (ICLR),2022
2. Guan Yue, Zhengyi Li, Jingwen Leng, Zhouhan Lin, and Minyi Guo,Transkimmer: Transformer Learns to Layer-wise Skim,2022 Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics(CCF-A),2022
3. Yue Guan, Zhengyi Li, Jingwen Leng, Zhouhan Lin, Minyi Guo, Yuhao Zhu,Block-Skim: Efficient Question Answering for Transformer,2022 The Thirty-Sixth AAAI Conference on Artificial Intelligence(CCF-A),2022
4. Zihan Liu, Jingwen Leng, Zhihui Zhang, Quan Chen, Chao Li, Minyi Guo,VELTAIR: Towards High-Performance Multi-Tenant Deep Learning Services via Adaptive Compilation and Scheduling,2022 Conference on Architectural Support for Programming Languages and Operating Systems(CCF-A),2022
5. Cong Guo, Yuxian Qiu, Jingwen Leng, Chen Zhang, Ying Cao, Quanlu Zhang, Yunxin Liu, Fan Yang, Minyi Guo,Nesting Forward Automatic Differentiation for Memory-Efficient Deep Neural Network Training,2022 IEEE 40th International Conference on Computer Design
6. Cong Guo, Chen Zhang, Jingwen Leng, Zihan Liu, Fan Yang, Yunxin Liu, Minyi Guo, Yuhao Zhu,Ant: Exploiting adaptive numerical data type for low-bit deep neural network quantization,2022 IEEE/ACM International Symposium on Microarchitecture
7. Weihao Cui, Han Zhao, Quan Chen, Ningxin Zheng, Jingwen Leng, Jieru Zhao, Zhuo Song, Tao Ma, Yong Yang, Chao Li, Minyi Guo,Enable Simultaneous DNN Services Based on Deterministic Operator Overlap and Precise Latency Prediction,2021 Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis
8. Yangjie Zhou, Mengtian Yang, Cong Guo, Jingwen Leng, Yun Liang, Quan Chen, Minyi Guo, Yuhao Zhu,Characterizing and Demystifying the Implicit Convolution Algorithm on Commercial Matrix-Multiplication Accelerators,2021 IEEE International Symposium on Workload Characterization (IISWC)
9. 周杨杰;冷静文;杨孟天;过敏意,图像数据处理方法、装置、计算机设备和存储介质,2021年专利
10. 冷静文,朱禺皓,郭聪,姚斌,过敏意,可重构的单指令多数据脉动阵列结构、处理器及电子终端,2021年专利
11. Cong Guo, Bo Yang Hsueh, Jingwen Leng, Yuxian Qiu, Yue Guan, Zehuan Wang, Xiaoying Jia, Xipeng Li, Minyi Guo, Yuhao Zhu,Accelerating Sparse DNN Models without Hardware-Support via Tile-Wise Sparsity,2020 Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis
12. Yue Guan, Jingwen Leng, Chao Li, Quan Chen, Minyi Guo,How Far Does BERT Look At: Distance-based Clustering and Analysis of BERT’s Attention,2020 Proceedings of the 28th International Conference on Computational Linguistics
13. Wei Zhang, Ningxin Zheng, Quan Chen, Yong Yang, Zhuo Song, Tao Ma, Jingwen Leng, Minyi Guo,Precise Capacity Planning and Fair Scheduling based on Low-level Statistics for Public Clouds. International Conference on Parallel Processing,2020 49th International Conference on Parallel Processing
14. Zihan Liu, Jingwen Leng, Guandong Lu, Minyi Guo, Quan Chen, Chao Li,一种资源配置方法、介质及服务端,2020年专利
15. Zihan Liu, Jingwen Leng, Guandong Lu, Minyi Guo, Quan Chen, Chao Li,神经网络的编译方法、系统、计算机存储介质及编译设备,2020年专利




.jpg)

