
2024-09-23
上海期智研究院PI、清华大学助理教授弋力团队,近期提出“准物理模拟器” (QuasiSim) 来解决复杂灵巧手操作问题,成功地使灵巧的手能够在高保真模拟环境中跟踪复杂多样的操作。此外,团队基于多模态大语言模型的无动作捕捉数据的人体动作生成,以及针对具身交互设计的三维多模态大模型ShapeLLM,为机器人操作和人机协作等领域研究提供了新思路。相关3项成果收录在今年的计算机视觉领域的顶级学术会议之一ECCV 2024。

Innovation Highlights
1. 通过引入参数化准物理模拟器和物理课程来探索灵巧手操作转移问题。成功地使灵巧手能够在高保真模拟环境中跟踪复杂多样的操作,将成功率比最佳性能基线提高了 11% 以上。
2. 弋力团队首次提出在没有任何动作数据的情况下,利用多模态大模型基于自然语言指令作为用户控制信号,探索了开放式人体动作生成,适用于任何动作任务和环境。
3. 团队提出了首个针对具身交互设计的三维多模态大模型ShapeLLM,弥补了现有多模态大模型在处理精确几何信息时的不足,而且通过语言作为通用界面的方式,极大地增强了模型对三维形态、空间感知方面的理解能力。
Achievements Summary
通过准物理模拟器来解决复杂灵巧操作迁移问题—QuasiSim
提升具身智能体与世界交互的能力是实现通用人工智能的重要一步。由于设置真实机器人在真实世界中进行反复试验的成本高昂且存在潜在危险,开发具身算法的标准方法一般是先在物理模拟器中学习,然后通过模拟到真实的技术迁移到真实世界。在大多数情况下,物理模拟器被视为黑匣子,人们已经投入了大量精力来开发这些黑匣子中具身技能的学习和优化方法。尽管取得了长足的进步, 但很少讨论所使用的模拟器是否最合适的问题。
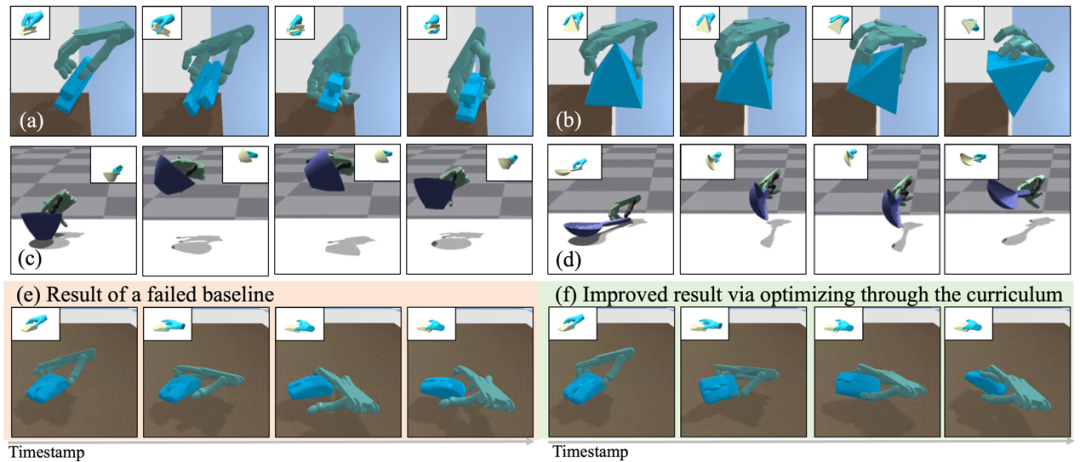
图1. QuasiSim—通过准物理模拟器来解决复杂灵巧操作迁移问题
弋力团队研究了这个问题,并说明了如何在技能习得的同时优化模拟器,可以使机器人操作中一项流行但具有挑战性的任务—灵巧操作迁移受益。QuasiSim提出了一系列参数化的准物理模拟器 (Quasi-Physical Simulators),用于手-物接触丰富的灵巧操作任务。这些模拟器可以定制以增强任务的可优化性,同时也可以定制以近似真实物理。参数化模拟器将铰接式多刚体表示为参数化点集,使用不受约束的参数化弹簧阻尼器对接触进行建模,并通过参数化的残差物理补偿未建模的影响。
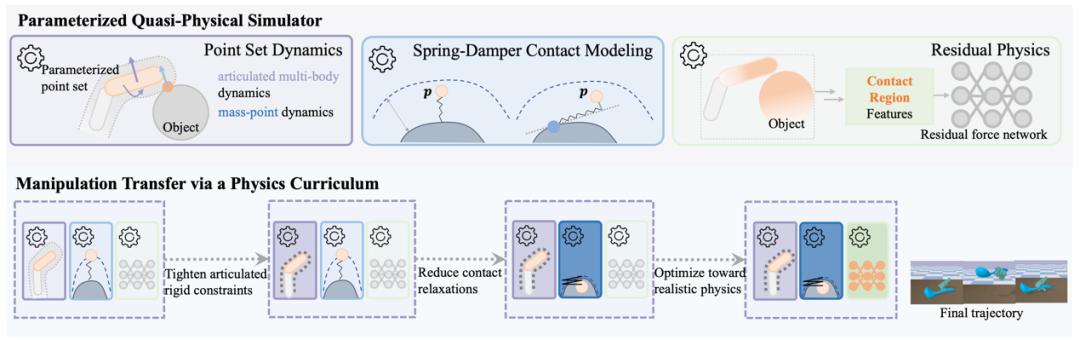
图2. 参数化的准物理模拟器
在优化过程中,模拟器中铰接刚性约束和接触模型刚度都在最开始的阶段被完全放松。它可能无法反映物理真实性,但提供了一个良好的环境,可以轻松解决操作迁移的问题。随后,我们逐渐收紧铰接刚性约束和接触模型。任务解决在这个课程中的每个模拟器中迭代进行。最后,我们优化参数化的模拟器以近似真实的物理。任务优化继续进行,产生能够在具有真实物理的环境中执行操作的灵巧手轨迹。
团队在两个广受欢迎的模拟器,PyBullet和Isaac Gym中验证了该方法的有效性。我们可以跟踪涉及非平凡物体运动(例如大旋转)和复杂工具使用(例如使用勺子来回搅水)的复杂操作。该方法在数量和质量上都成功超越了之前表现最佳的方法,成功率比之前表现最佳的方法高出 11% 以上。
QuasiSim有潜力加速机器人灵巧操作技能的发展。相关成果收录于2024 ECCV中。本论文一作为上海期智研究院实习生、清华大学博士生刘雪怡,通讯作者为弋力助理教授。共同作者为清华大学博士生吕康博,清华大学本科生张洁琼,上海期智研究院PI、清华大学助理教授杜韬。
基于多模态大语言模型的无动作捕捉数据的人体动作生成—FreeMotion
在人体动作生成任务中,基于学习的办法往往受限于小体量的动作捕捉(motion capture)数据集,导致没有较好的泛化能力,在面对新的任务和场景时,性能下降较为明显。一种潜在的解决该问题的方法是大幅度增加动作捕捉数据集的体量,然而,收集动作捕捉数据的困难性和昂贵性使得这几乎不可能。与此同时,利用互联网规模的图像和文本数据训练的多模态大模型已经展现出惊人的世界知识和推理能力,适用于各种下游任务。利用这些多模态大模型可能有助于人体动作生成。FreeMotion首次在没有任何动作数据的情况下,利用多模态大模型基于自然语言指令作为用户控制信号,探索了开放式人体动作生成,适用于任何动作任务和环境。令人鼓舞的结果展示了利用多模态大模型进行无动作数据人体动作生成的价值,并为未来的研究铺平了道路。
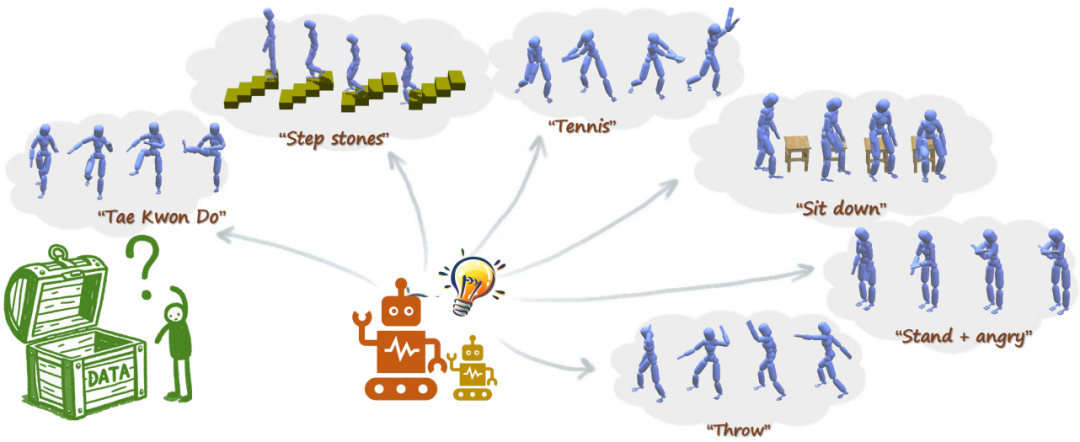
图3. FreeMotion—基于MLLMs的开放式人体动作生成
FreeMotion框架可分为以下阶段:
1)通过利用多模态大模型作为关键帧设计师和动画师进行关键帧序列生成;
2)通过插值和动作跟踪在关键帧之间填充动作。
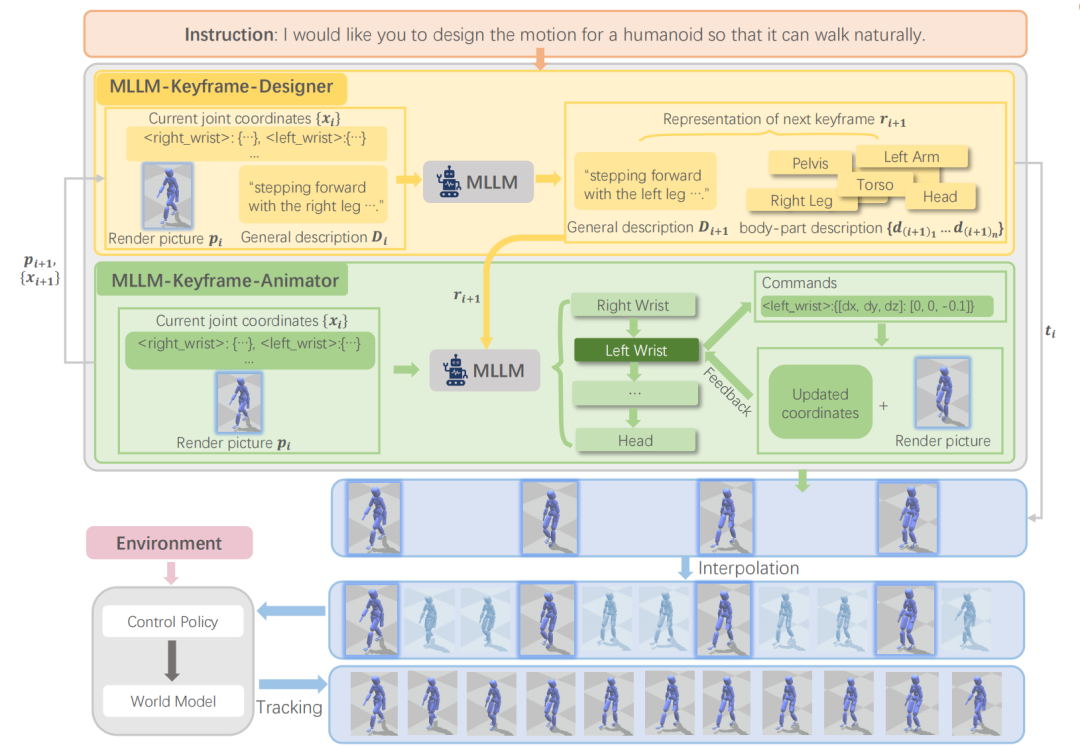
图4. FreeMotion 概览
在第一阶段中,基于用户指令提出的动作要求,FreeMotion希望多模态大模型能够首先将其转换为一系列人体姿势,每个姿势代表运动中的一个关键帧。这样的任务涉及到动作理解、关键帧推理和人体姿势调整。使用多模态大模型同时输出准确关键帧序列是具有挑战性的,因此FreeMotion采用了两个不同的GPT-4V代理,每个代理扮演不同的角色。一个充当关键帧设计师,旨在将输入的动作指令转换为相对低层次的关键帧序列描述。另一个充当关键帧动画师,负责通过视觉反馈调整人体姿势,使其与设计师生成的关键帧描述相匹配。
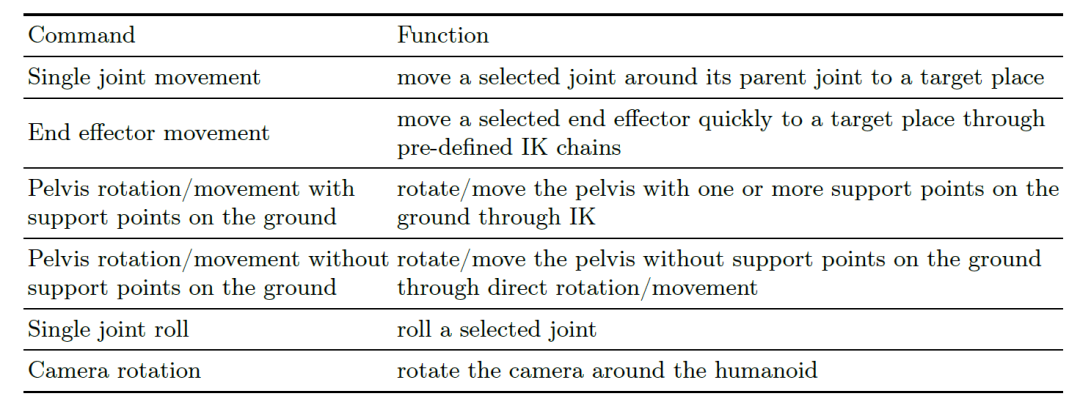
图5. 指令集—将姿势调整规范化为一组命令
第二阶段负责将第一阶段生成的动作帧填补成为连续的动画片段,然而,简单的线性插值有可能违背物理规则。使用动作跟踪方法可以解决物理上不可靠的状态转换。因此,FreeMotion首先将第一阶段生成的动作帧插值为连续的初步片段,之后使用基于CVAE的控制策略,结合基于MLP的世界模型实现精细的运动跟踪,从而生成连续的,物理可靠的动作片段。FreeMotion在多个下游任务上展现了令人惊喜的能力。
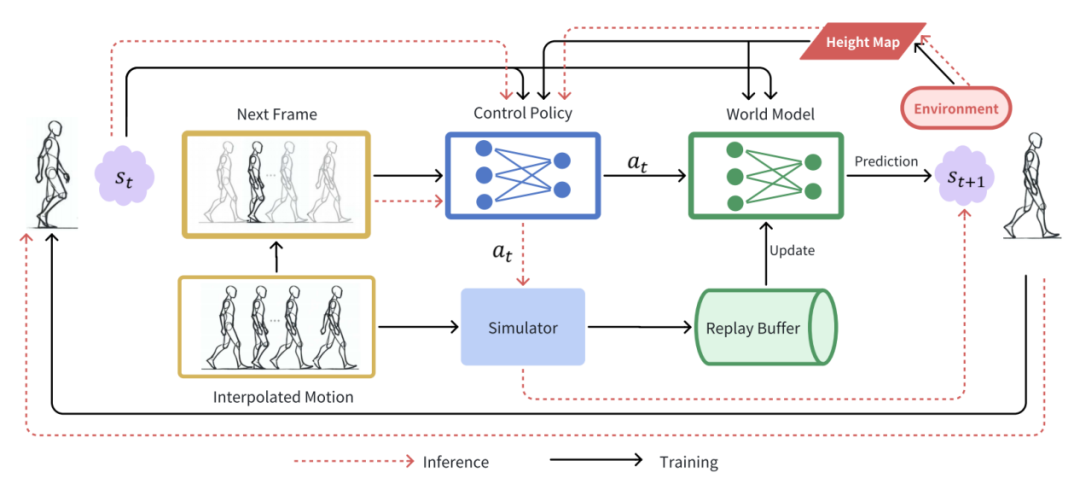
图6. 策略训练和推理
FreeMotion不仅能够为多种下游任务生成逼真的人类运动,而且在没有运动数据的情况下也能实现,为成本高昂或无法进行动作捕捉的情况下收集人类运动数据提供了解决方案。相关成果收录于2024 ECCV中。本论文一作为上海期智研究院实习生、清华大学博士生张智楷,通讯作者为弋力助理教授。共同作者为上海期智研究院实习生、清华大学本科生李忆唐、黄浩峰,上海期智研究院助理研究员林明仙。
ShapeLLM: 用于体现交互的通用3D对象理解
具身智能(Embodied Intelligence)为视觉感知与机器人操作之间构建了关键桥梁。通过诸如CLIP和ChatGPT等强大的基础感知模型,机器人能够轻松识别操作对象的属性和类别,并据此进行详细规划。然而,依赖于二维图像的语义理解,远远无法满足我们对具身交互能力的需求。在机器人操作中,除了回答“这是什么?”之外,我们还需要解决“它在哪里?”这一问题,而这正是空间智能的核心。李飞飞教授曾言:“看是为了做”,强调视觉感知与行动的密切联系。
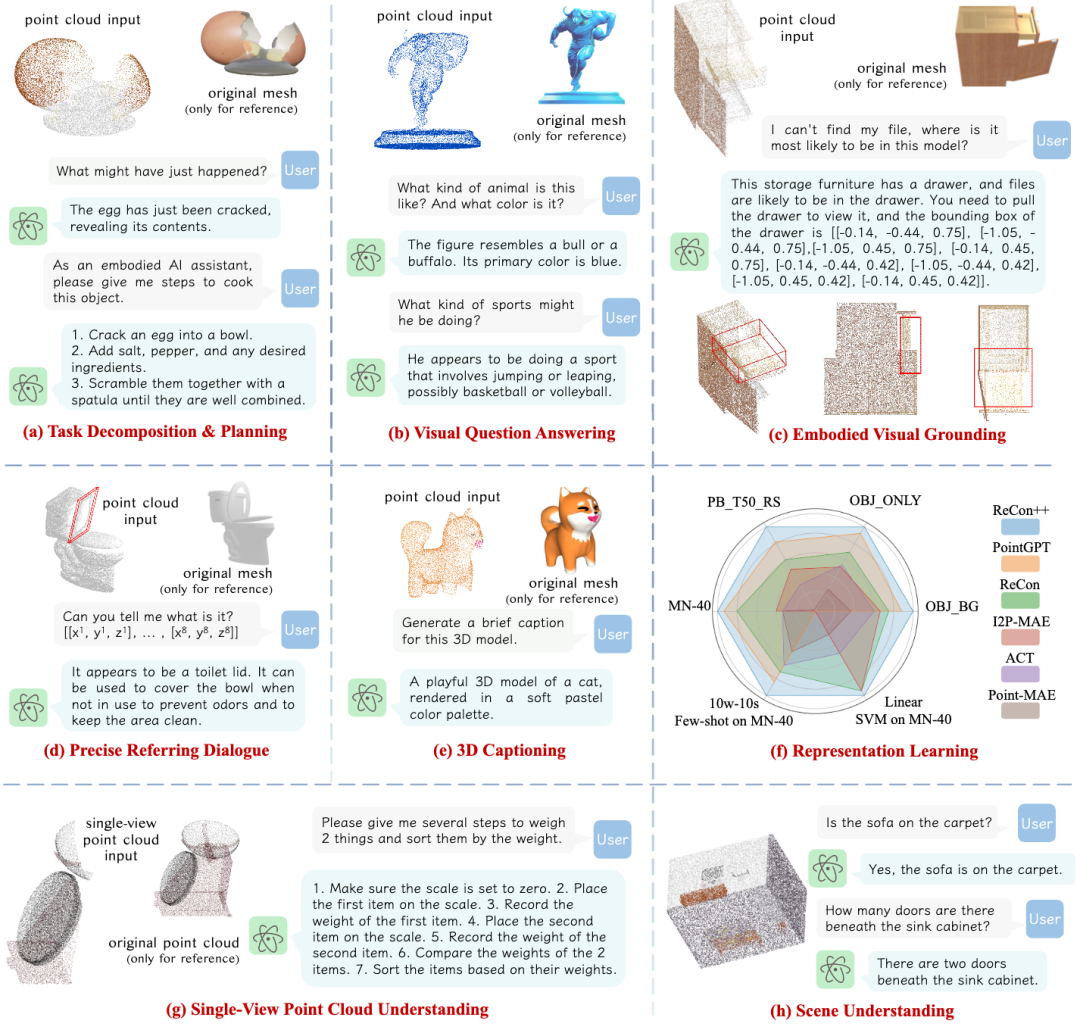
图7. ShapeLLM和ReCon++示意图
因此,为了提升机器人在复杂环境中的自主操作能力,我们的模型在以下三方面实现了重要创新:
1. 3D点云作为输入:我们提出了强大的点云编码器ReCon++,支持单视图点云输入。与传统的二维图像输入相比,三维点云能够为机器人提供更加丰富的空间信息,使其能够更好地理解物体的几何形态与空间布局。
2. 多尺度特征映射:我们采用了多尺度特征映射技术,涵盖从高维语义理解、任务规划到细粒度的局部空间定位。这种多层次的特征提取使机器人能够在宏观和微观层面上同时处理复杂任务,不仅具备全局任务规划能力,还能够精确识别和操作物体的局部特征。
3. 物体affordance part的6自由度(6DoF)姿态作为训练目标:我们将物体的可操作性部件(Affordance Part)的6自由度姿态作为关键训练目标,并通过指令微调学习(instruction tuning),激发大型预训练模型的通用泛化理解能力。通过这种方式,机器人能够更加灵活地应对多种任务场景,并展现出卓越的操作泛化能力。
ShapeLLM不仅为机器人提供了更强的感知能力和空间理解能力,还使其在面对多样化的任务需求时,能够更为自主地做出决策和动作规划,从而大大提升了机器人在实际应用中的执行效能。
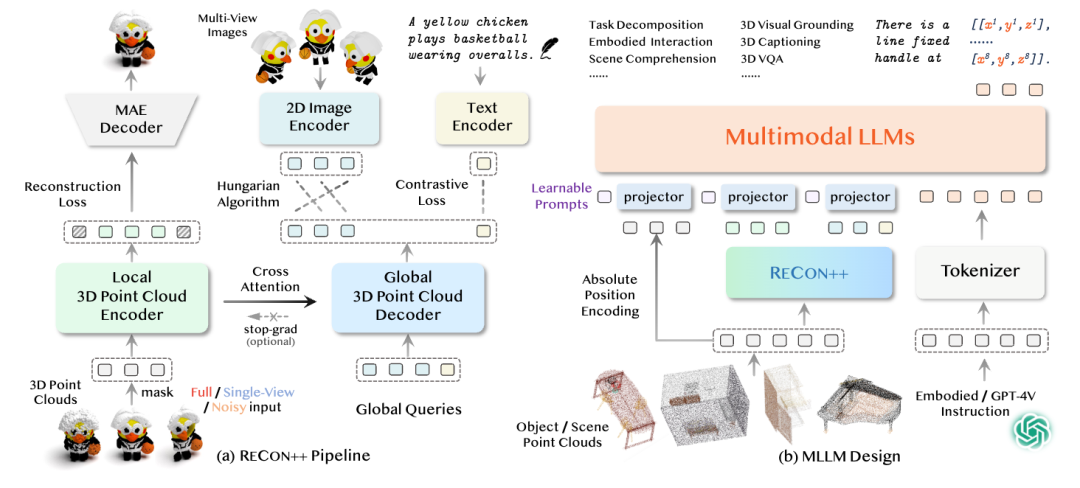
图8. ShapeLLM框架概述
此外,我们还提供了一个通用的三维具身交互、空间智能评测数据集3D MM-Vet,通过精心手工筛选、构造的59个三维模型和212对问答数据,涵盖了通用识别、知识与语言生成、空间智能和具身交互四个层次的任务。通过这一基准,研究人员可以更准确地评估和比较不同模型的性能,进而推动具身交互和空间感知技术的发展。

图9. ShapeLLM能执行精确空间位置的具身交互
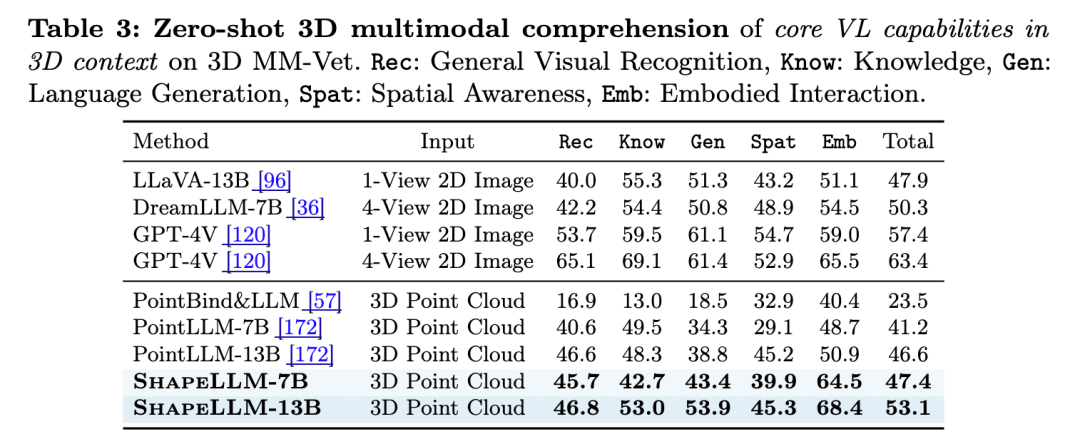
图10. 3D MM-Vet中通用3D理解和具身交互能力评估结果
ShapeLLM为机器人提供了更强的感知能力和空间理解能力,3D MM-Vet为三维视觉-语言模型提供了一个标准化的评测平台,相关研究为未来的研究提供了新的方向和思路。该成果收录于2024 ECCV中。本论文一作为西安交通大学硕士生齐泽坤,项目组织者为西安交通大学硕士生董润沛,通讯作者为清华大学弋力助理教授、马恺声副教授。
更多信息请阅读论文:
1. QuasiSim: Quasi-Physical Simulators for Dexterous Manipulations Transfer, Xueyi Liu, Kangbo Lyu, Jieqiong Zhang, Tao Du, Li Yi†, https://meowuu7.github.io/QuasiSim/, ECCV 2024.
2. FreeMotion: MoCap-Free Human Motion Synthesis with Multimodal Large Language Models, Zhikai Zhang, Yitang Li, Haofeng Huang, Mingxian Lin, Li Yi†, https://zzk273.github.io/freemotion/, ECCV 2024.
3. ShapeLLM: Universal 3D Object Understanding for Embodied Interaction,Zekun Qi, Runpei Dong, Shaochen Zhang, Haoran Geng, Chunrui Han, Zheng Ge, Li Yi† and Kaisheng Ma†,https://qizekun.github.io/shapellm/, ECCV 2024







