
2024-10-15
上海期智研究院PI、清华大学助理教授许华哲团队,提出了一种新的机器人操控框架Robo-ABC,使机器人能够泛化地理解和操作在训练时未见过的类别的物体。此外,团队利用视频扩散模型的生成能力,提出了一种从专家视频中提取密集奖励信号的新框架。相关2项成果收录在今年的计算机视觉领域的顶级学术会议之一ECCV 2024。


Innovation Highlights
1. 团队提出一种新的机器人操控框架Robo-ABC,利用人类视频中的交互经验,通过语义对应来帮助机器人在面对新物体时,能够通过检索与已知物体在视觉或语义上相似的物体,来推断新物体的可供性。
2. 团队提出了一种从专家视频中提取密集奖励信号的新框架—Diffusion Reward,通过利用视频扩散模型的生成能力,为视觉RL任务提供了一种有效的奖励学习框架,并展示了其在复杂任务中的潜力。
Achievements Summary
Robo-ABC: 通过语义对应实现跨类别的可供性泛化,用于机器人操控
Robo-ABC 是一种新的机器人操控框架,旨在使机器人能够泛化地理解和操作在训练时未见过的类别的物体。该框架的核心思想是利用人类视频中的交互经验,通过语义对应(semantic correspondence)来帮助机器人在面对新物体时,能够通过检索与已知物体在视觉或语义上相似的物体,来推断新物体的可供性(即物体可被如何操作的特性)。团队首先从人类与物体互动的视频中提取可供性信息,并将这些信息存储在可供性记忆中。当机器人面对一个新物体时,它会从记忆中检索与新物体在视觉和语义上相似的物体。然后,利用扩散模型的语义对应能力,将检索到的物体的接触点映射到新物体上。这个过程使得机器人能够在没有手动标注、额外训练、部件分割、预编码知识或视角限制的情况下,零样本地泛化到跨类别物体的操控。
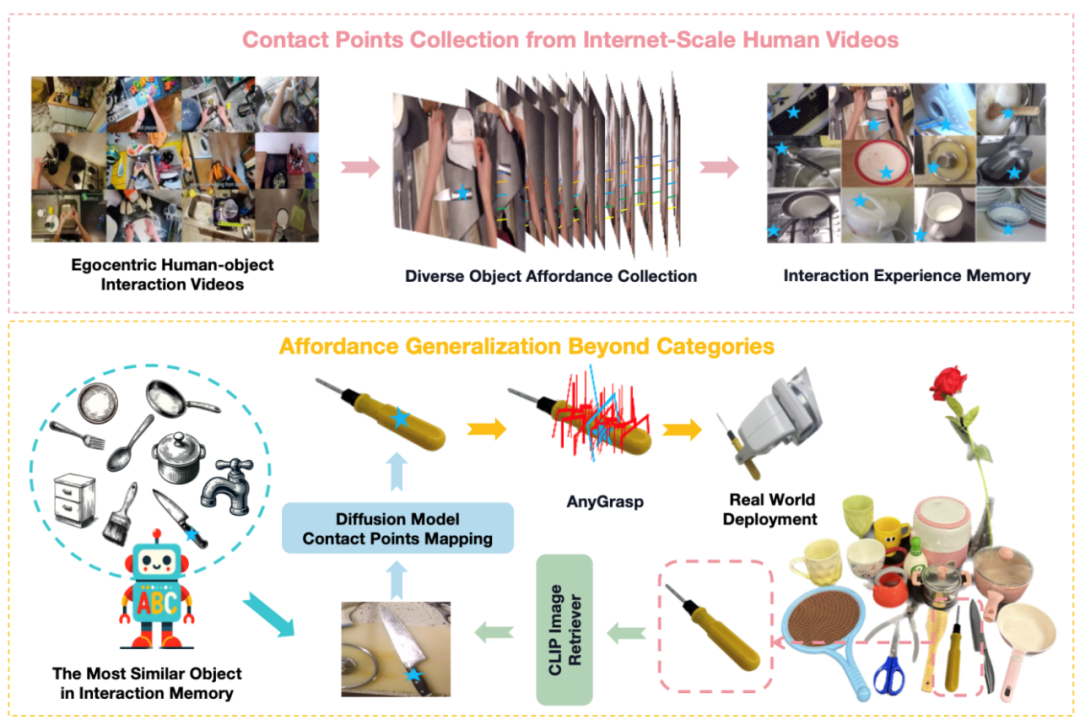
图1. Robo-ABC流程图
团队发现了Robo-ABC在泛化性上有优异的性能。在真实世界实验中,Robo-ABC在跨类别物体抓取任务中达到85.7%的成功率,显著提高了机器人在开放世界中处理新视图和跨类别设置的抓取准确性。
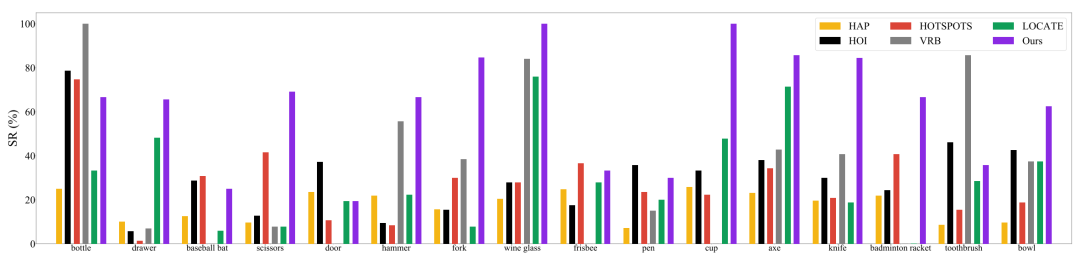
图2. Robo-ABC的优异性能

图3. Robo-ABC可泛化至多种不同类型的物体
该研究解决了机器人在面对新类别物体时如何有效抓取的挑战,对推动机器人在非结构化环境中的自主操作具有重要价值。本论文一作为上海期智研究院助理研究员鞠沅辰,上海期智研究院实习生、清华大学博士生胡开哲,通讯作者为许华哲助理教授。
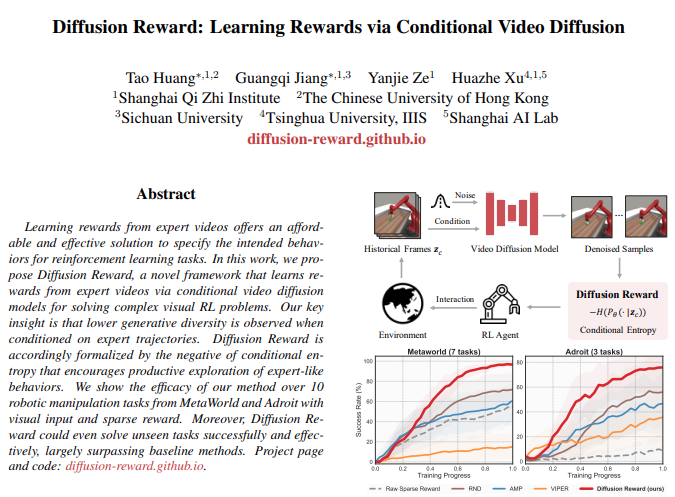
通过条件视频扩散模型学习专家视频的奖励函数
团队提出了Diffusion Reward新框架,它通过条件视频扩散模型从专家视频中学习奖励函数,以解决复杂的视觉强化学习 (RL) 问题。Diffusion Reward通过估计条件熵的负值来鼓励RL智能体探索类似专家的行为。具体来说,研究者们首先使用专家视频训练一个视频扩散模型,然后利用该模型预测的分布的熵来估计条件熵,将其作为奖励信号。这个奖励信号结合了新颖性寻求奖励和稀疏的环境奖励,以形成用于高效RL的密集奖励。为了加速奖励推断,研究者们还采用了向量量化编码来压缩高维观测。通过在MetaWorld和Adroit的10个视觉机器人操控任务上的实验,我们验证了他们框架的有效性,展示了其在相同训练步骤下比最佳基线方法分别提高了38%和35%的性能。此外,预训练的奖励模型能够在未见任务上实现合理的零样本泛化性能。
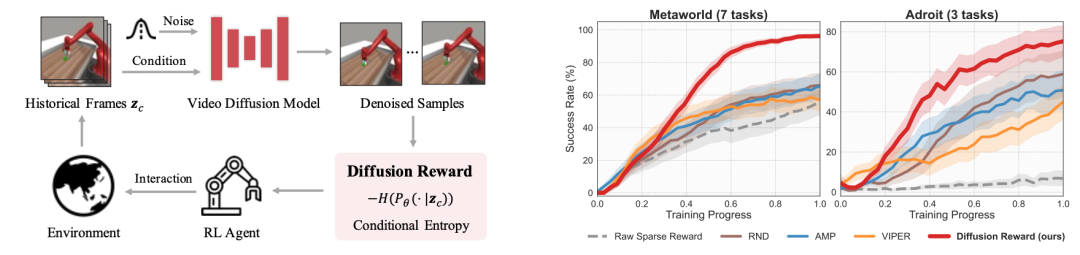
图4. Diffusion Reward流程图 (左) 和性能曲线 (右)
团队发现了Robo-ABC在泛化性上有优异的性能。相较于前人的方法,有了显著的提升。
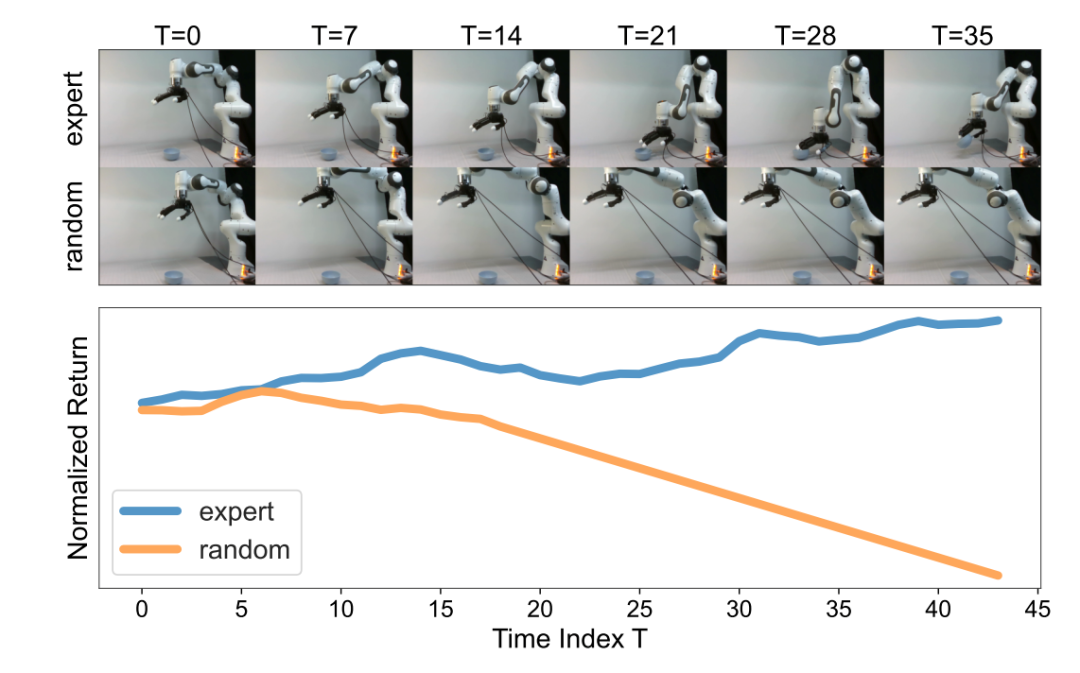
图5. Diffusion Reward 在真实机器人上
准确区分专家数据和随机数据
该工作提出了一种从专家视频中提取密集奖励信号的新方法,通过利用视频扩散模型的生成能力,为视觉RL任务提供了一种有效的奖励学习框架,并展示了其在复杂任务中的潜力。论文共同第一作者为期智研究院实习生黄涛、蒋光启,通讯作者为许华哲助理教授。
更多信息请阅读论文:
1. Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation, Yuanchen Ju*, Kaizhe Hu*, Guowei Zhang, Gu Zhang, Mingrun Jiang, Huazhe Xu†, ECCV 2024.
2. Diffusion Reward: Learning Rewards via Conditional Video Diffusion, Tao Huang*, Guangqi Jiang*, Yanjie Ze, Huazhe Xu†, ECCV 2024.







