
2024-10-12

Innovation Highlights
1. 高阳团队提出CoPa框架 (General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models),利用基础模型内嵌的常识知识,通过空间约束实现机器人的通用操控能力。CoPa通过创新地应用视觉-语言大模型,能够在无需额外训练的情况下,根据自然语言指令和场景观测生成一系列精确的六自由度末端执行器姿态,从而应对开放世界的操控任务。
2. 高阳团队提出“多智能体机械狗环境” (Multi-agent Quadruped Environment) 来促进机械狗在复杂环境中的协作能力,成功地使机械狗能够在可并行模拟的环境里与子环境中的其他机械狗,物体以及自行驱动的智能体交互。此外,团队基于分层强化学习以及预训练机械狗的底层控制策略,直接地解决了多智能体机械狗环境所提出的部分任务。
Achievements Summary
基于基础大模型生成物体部件间空间约束的机器人通用操作框架—CoPa
在机器人技术领域,适应复杂环境的操作能力是关键挑战之一。然而,操作任务中的每个低层控制指令的实现往往依赖于特定任务上的学习方法或人为定义的规则,因此需要大量的数据收集工作或人力付出,并且难以泛化到不同场景和任务。与此同时,在互联网规模数据上训练得到的基础大模型被证实隐含着对世界的广泛常识知识。研究者发现其在机器人操作的高层任务规划中的应用是十分有效的。而其在低层控制中的应用尚待研究。

图1. CoPa—利用基础大模型实现机器人通用操作
高阳团队研究了这个问题,提出了“基于物体部位间约束的通用机器人工具操作框架”。此创新框架可以将大模型内嵌的常识运用到低层的机器人控制当中,通过物体部位间约束生成一系列末端执行器六自由度位姿,从而解决开放世界中的任务与物体操作任务,并且无需复杂的提示词设计和额外的训练。此外,该框架还可以与高层任务规划算法无缝衔接,完成如制作手冲咖啡和布置浪漫餐桌等长周期复杂任务。
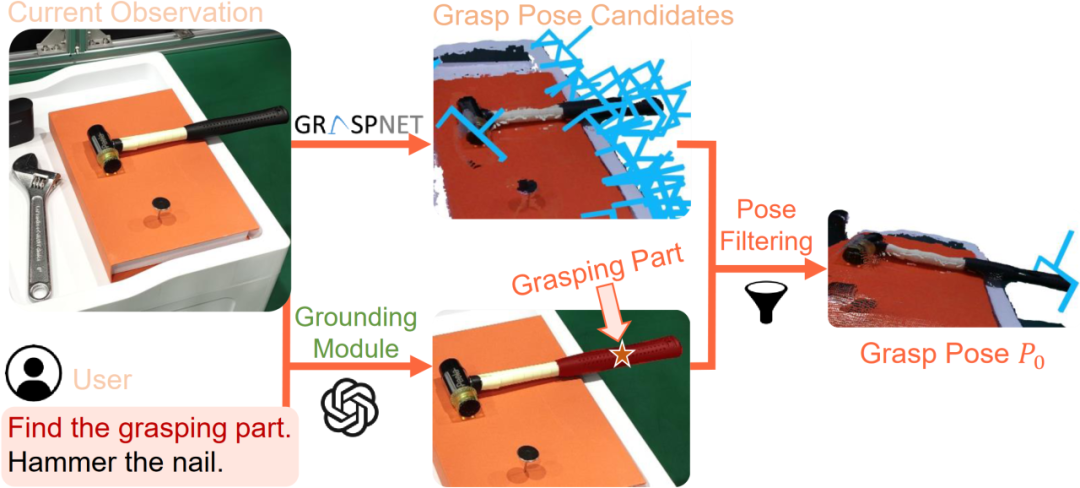
图2. 任务导向抓取阶段示意图

图3. 任务导向运动规划阶段示意图
CoPa将操作任务分成两个阶段:任务导向抓取阶段和抓取后任务导向运动规划阶段。在抓取阶段,抓取物体部位定位模块,利用视觉语言大模型定位待抓取物体部位的掩膜,用以过滤预训练抓取模型生成的候选抓取位姿,得到最终的任务导向抓取位姿。在任务导向运动规划阶段,先使用定位模块定位任务相关的物体部位;然后让视觉语言大模型描述部位间应当满足的空间几何约束;最后使用一个优化问题求解器解得目标位姿序列,使用路径规划算法得到运动轨迹。CoPa使用部位间空间约束作为连接视觉语言大模型和机器人的桥梁,可以很好地利用视觉语言大模型中的知识常识,并且具有精细的物理理解能力,同时又可以利用传统的控制算法,实现精准流畅的操作。
团队在真机实验平台上验证了这个框架的有效性。CoPa在 10 个任务中取得了 63% 的平均成功率,显著高于基准方法 VoxPoser。在消融实验中,通过与 3 个变种的对比,展现了框架中视觉语言大模型、由粗到细的定位设计和空间约束的表示方式的重要性。最后,CoPa还与高层任务规划算法ViLa集成,完成了复杂长周期操作任务。
CoPa为机器人通用操作提出了一种新的可能。本论文共同一作为上海期智研究院实习生、清华大学博士生黄浩栩与林凡淇,通讯作者为高阳助理教授。共同作者为上海期智研究院实习生、清华大学博士生胡英东、王圣杰。
通过多智能体机械狗环境以展现机器人协作能力—MQE
机器人之间的合作能力是将机器人应用在现实生活中必不可少的要求,为了合作完成复杂的任务,或是降低多个机器人之间互相带来的负面作用,都需要机器人能够感知并且主动协作。近年来对于机械狗底层控制的研究在可并行的模拟器以及深度强化学习的帮助下取得了突飞猛进的发展,但由于动作空间的定义问题,在模拟器中往往只会考虑单只机械狗的情况,使得相关研究大多只能局限于机械狗的运动控制问题,与日常生活中的应用仍相去甚远。

图4. 多智能体机械狗环境中12个预定义的任务
高阳团队提出了多智能体机械狗环境(Multi-agent Quadruped Environment),使得对该问题的研究变得可行。多智能体机械狗环境提供了一套模块化设计多机械狗任务的流程,使得在模拟器中加入多只机械狗,拼合提前定义好的地形,加入可以自行驱动的物体易于操作,为多智能体机械狗的研究提供了一个方便的平台。同时,多智能体机械狗环境定义了12个需要多只机械狗协作的任务,以探索不同多智能体强化学习(Multi-Agent Reinforcement Learning)算法在解决中的效果。

图5. 协作成功与失败案例
在尝试解决这些定义好的任务时,团队使用了分层强化学习,将控制多只机械狗完成任务拆成了控制机械狗以及多机械狗协作两个任务。首先训练一个接受连续指令的底层运动控制策略,再基于该策略训练一个发出显性指令的顶层策略,两个策略相结合以实现从顶层到底层对于机械狗的控制,极大地降低了学习难度。
团队在爬跷跷板以及牧羊等任务上验证了分层强化学习的有效性,相较于直接使用深度强化学习实现了从失败到成功的突破。虽然分层强化学习能够快速地解决部分问题,仍然存在对环境感知不足,底层控制策略不适配任务的问题。期待未来能够有更多相关研究。
多智能体机械狗环境有潜力加速机器人协作能力的发展。本论文一作为清华大学本科生熊子言,通讯作者为高阳助理教授。共同作者为北京邮电大学研究生陈波以及博士生导师何召锋,智谱华章研究员黄世宇,第四范式研究员涂威威。
更多信息请阅读论文:
1. CoPa: General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models, Haoxu Huang, Fanqi Lin, Yingdong Hu, Shenjie Wang, Yang Gao†, https://copa-2024.github.io/, IROS 2024.
2. MQE: Unleashing the Power of Interaction with Multi-agent Quadruped Environment, Ziyan Xiong, Bo Chen, Shiyu Huang, Wei-wei Tu, Zhaofeng He, Yang Gao†, https://ziyanx02.github.io/multiagent-quadruped-environment/, IROS 2024.







