
2024-05-28
存算一体是一种新型的计算机存储架构。通过将存储单元和计算单元更加紧密地结合,存算一体架构可以有效克服传统冯·诺依曼架构中的存储墙瓶颈,减少分立的计算和存储单元之间大量数据传输的性能和能耗影响。上海期智研究院PI、清华大学助理教授高鸣宇团队,与上海期智研究院PI、上海交通大学副教授蒋力团队,近期在存算一体的硬件架构和软件框架方面合作取得了多项研究成果,包括存算一体架构中的数据通信和负载均衡优化、数据地址交织模式优化,以及真实存算一体平台上的图挖掘算法优化等。相关3项成果相继发表于计算机体系结构、数据库领域的顶级国际会议ISCA 2024(接收率为19.6%)和SIGMOD 2024。
Innovation Highlight
1. 提出了一种新型的硬件-软件协同设计方法NDPBridge,用于增强近DRAM bank处理架构中的跨bank协调能力。NDPBridge通过在DRAM层次结构中引入硬件桥实现了跨bank通信和动态负载平衡。该架构还引入了任务级消息传递模型,优化了数据传输,减少了延迟和拥塞,提高了系统的整体性能。
2. 在UPMEM这一真实存内计算硬件平台上设计了一个高效的图模式匹配算法框架,通过核间任务和数据的高效静态分配,以及核内任务分支间的动态协作,解决了在有限通信条件下2560个内存计算单元上的负载均衡和数据分配问题,高效地利用了UPMEM的算力和带宽。
3. 提出了一种具有统一和共享内存空间的基于DRAM的存算一体(PIM)系统UM-PIM。允许CPU和PIM所需两种不同数据排布的页面共存于同一个内存空间中,进而实现数据的零拷贝。UM-PIM的核心在于内存管理机制与硬件设计。
Achievements Summary
1. 在近 DRAM Bank 处理架构中的跨 Bank 协调支持—NDPBridge
近数据处理架构是一条缓解内存墙问题、降低内存访问开销的重要技术路线。其中,近DRAM bank架构在DRAM bank附近集成计算逻辑,每个bank及其周围的计算逻辑构成独立单元,可以高效并行访问和处理数据。但是,近DRAM bank架构同样面临两点主要挑战。首先,不同的单元互相隔离,无法进行跨单元通信。此外,由于系统由上千个单元组成,单元间的负载均衡也需要得到高效支持。】
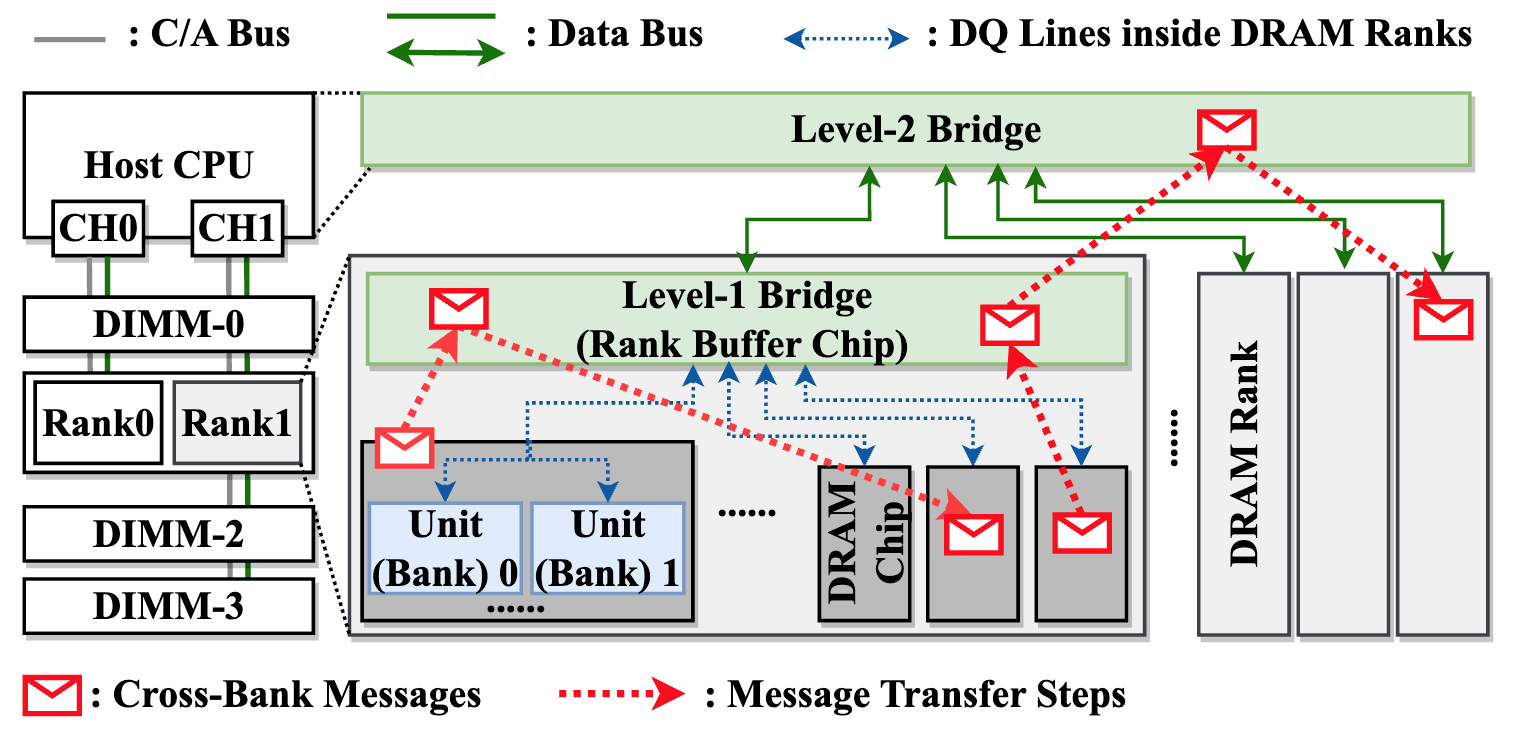
图1. OP-C2B 算法
高鸣宇团队与蒋力团队合作提出一种软硬件协同设计方案NDPBridge,在硬件层面,引入硬件桥,通过复用DRAM内部现有硬件接口和连线资源,在DRAM内部支持了跨bank传输。在软件层面,在上述硬件通讯机制基础上,他们设计了层次化和数据传输感知的调度方案,高效支持了跨单元负载均衡。
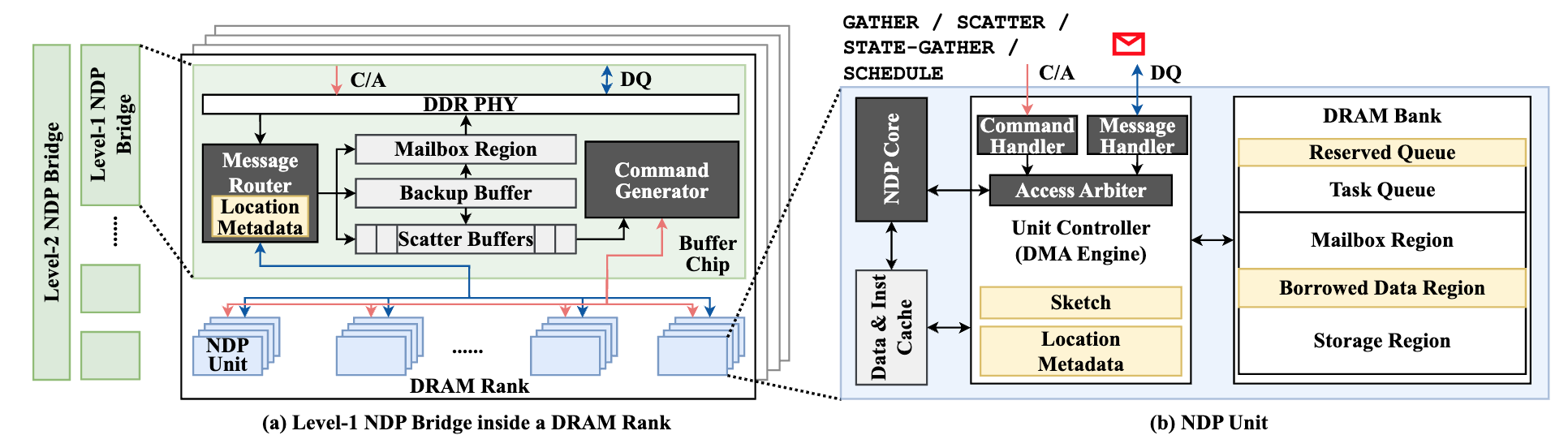
图2. NDPBridge中NDP单元和桥接部分的详细硬件结构
NDPBridge在性能、开销和适用性等方面具有显著优点,具体包括:
1. 相较于现有近DRAM bank处理方案,实现了平均2.23倍、最高2.98倍性能提升。
2. 硬件修改开销较小,对于DRAM内部芯片的尺寸和接口没有修改,且所有的修改均限制在现有的近数据处理产品修改过的硬件模块中。
3. 该架构对软件适配性较好,可应用至多种类型的应用和不同的数据规模。此外,由于该架构实现了自动的跨单元通信优化和负载均衡,大大降低了上层程序员的编程负担。
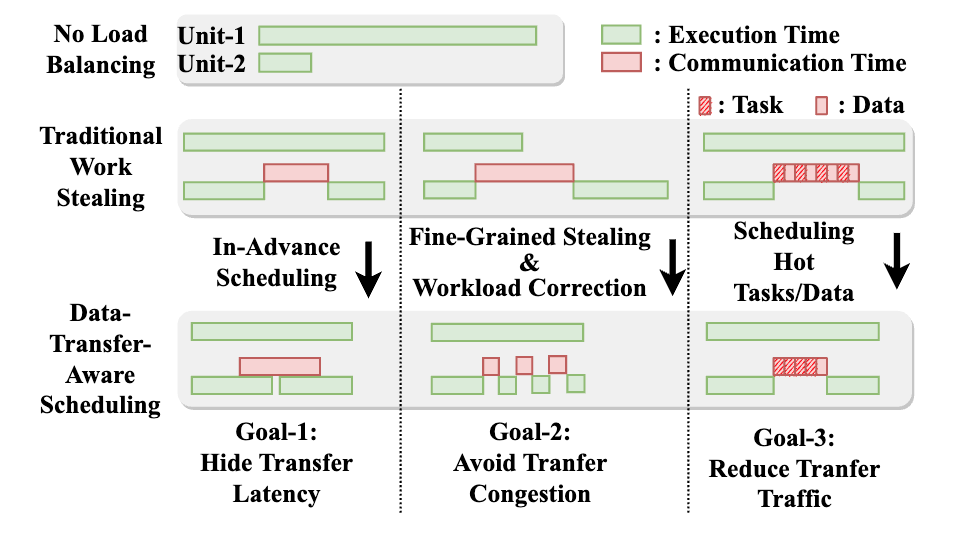
图3. 数据传输感知调度中的三个关键设计考虑因素
NDPBridge的成功实现不仅扩展了近bank NDP系统的应用范围,使其能够处理更复杂的应用场景,还为内存密集型应用提供了一种有效的解决方案,对于推动数据处理架构的发展具有重要意义。相关成果收录于ISCA 2024中。本论文一作为清华大学博士生田博宇。
2. 基于DRAM的PIM,具有统一和共享的内存空间—UM-PIM
PIM技术与传统的CPU架构存在不兼容问题。由于操作系统的页式管理,以及内存交错技术,难以将连续数据有效映射至同一个PIM单元的本地内存。这限制了PIM单元直接访问连续数据大小,使得PIM任务粒度受限,而细粒度任务卸载至PIM将引发显著的CPU-PIM通信开销,进而损害系统整体性能。为实现粗粒度任务卸载,现有商用PIM采用了隔离PIM和CPU的内存空间,以及关闭全局内存交织等极端措施。这些措施引入了额外的数据传输并损害了原本在CPU运行程序的性能。
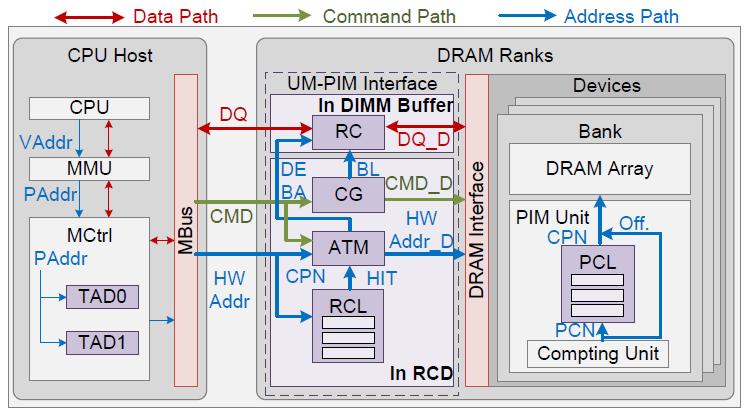
图4. UM-PIM架构和地址映射路径
为此,蒋力团队与高鸣宇团队合作提出了一种具有统一和共享内存空间的DRAM基础的处理内存(PIM)系统UM-PIM。允许CPU和PIM所需两种不同数据排布的页面共存于同一个内存空间中,进而实现零拷贝。
UM-PIM的核心在于内存管理机制与硬件设计。首先,UM-PIM引入双轨内存管理机制,实现CPU页与PIM页的独立页面分配与虚拟地址转换,确保PIM页能够均匀且非交错地映射至PIM本地内存,从而简化数据访问流程,提高访问效率。
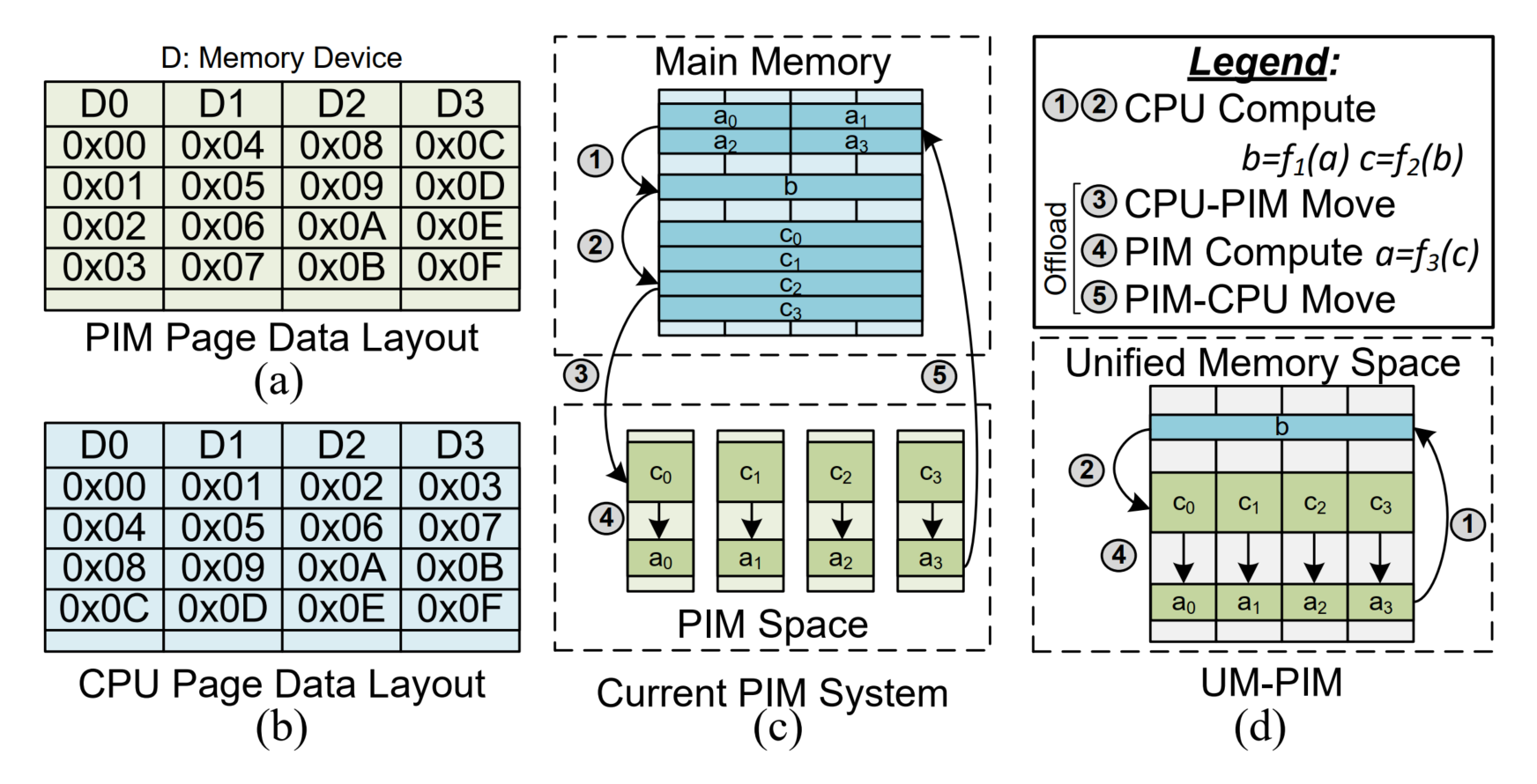
图5. (a) PIM和 (b) CPU页的理想数据布局。(c) 当前PIM系统中的隔离内存空间设计。(d) 本工作中提出的DRAM-based PIM统一共享内存空间设计。
其次,UM-PIM在硬件层面通过在PIM的DIMM一侧设计硬件接口,实现物理到硬件地址的动态映射。这一设计不仅加速数据重新布局过程,还降低CPU与PIM之间的通信开销,有效提升系统性能。
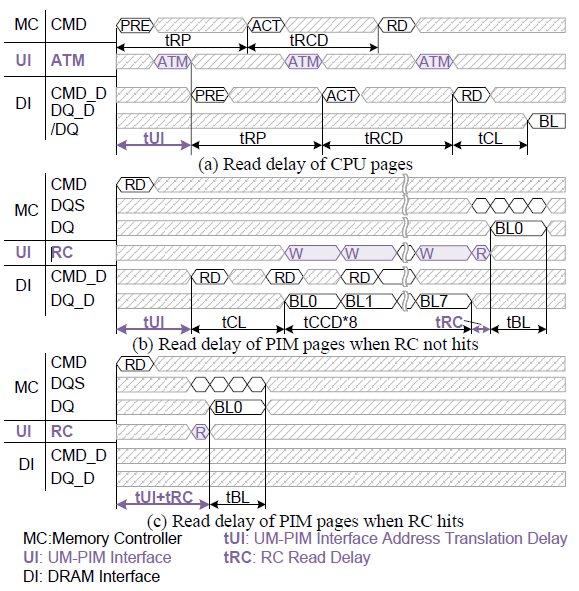
图6. UM-PIM接口的时序
同时,在软硬件协同设计方面,提供了一套API,优化了不同通信模式下CPU对PIM页面的访问,降低了PIM到PIM通信的开销。通过保持CPU页面的地址交错技术,UM-PIM确保了CPU的内存带宽不受影响,同时通过零拷贝技术在PIM任务卸载期间保持了内存带宽。
UM-PIM通过创新的内存管理和硬件支持,为PIM技术的发展和应用提供了一个高效、灵活且与现有技术兼容的新平台。相关成果收录于ISCA 2024中。本论文一作为研究院实习生、上海交通大学博士生赵怿龙。
3. 在真实存内计算硬件上的高效图模式匹配框架—PimPam
内存访问带宽一直以来是图模式匹配算法的一大瓶颈。高鸣宇团队与张焕晨团队合作,首次在UPMEM这一真实存内计算硬件平台上设计了一个高效的图模式匹配算法框架PimPam。通过核间任务和数据的静态分配,以及核内分支的动态协作,解决了在有限通信条件下2560个内存计算单元上的负载均衡和数据分配问题,高效地利用了UPMEM的算力和带宽。
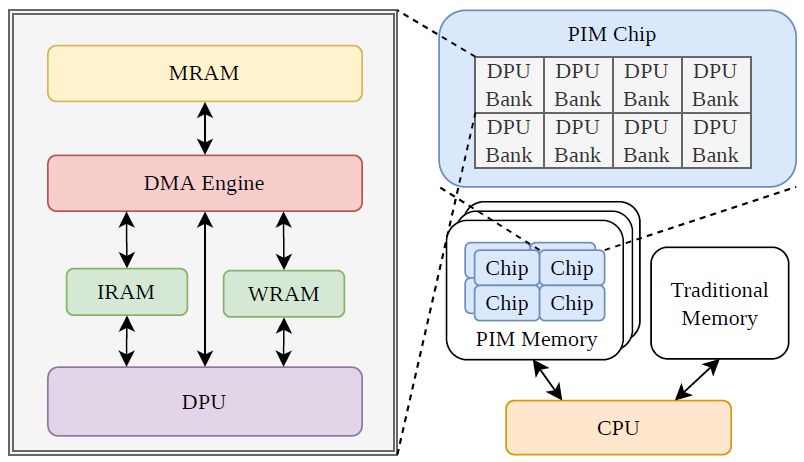
图7. UPMEM硬件架构
在大数据时代,图是对数据内在关联性的有效刻画,也是许多领域研究对象的高度抽象,例如社交网络、生物数据等都可以抽象为图。图模式匹配则是分析和提取图内信息的有效手段之一,有着广泛的应用。基于传统CPU的图模式匹配效率往往受到内存带宽的限制,近年来兴起的存内计算架构提供的高带宽和低访问时延有效解决了这一问题,但其有限的内存容量和通信限制也对研究者提出了新的挑战。
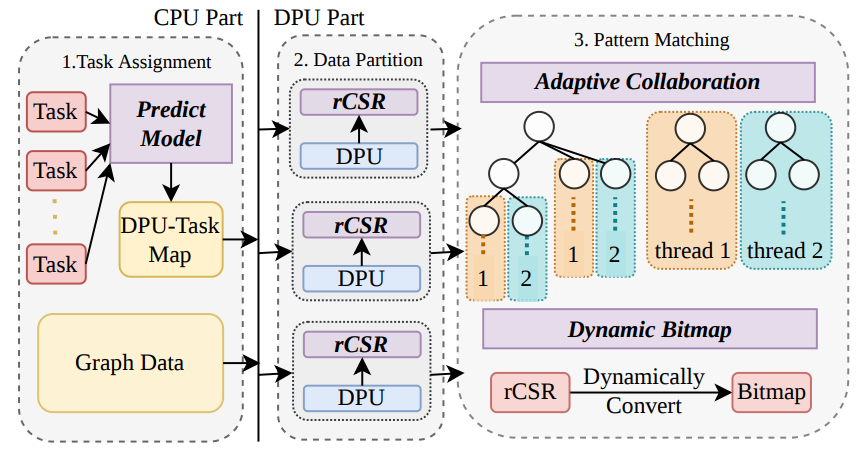
图8. PimPam概述
团队提出了首个基于真实存内计算硬件的高效图模式匹配框架PimPam。PimPam基于UPMEM这一架构,通过优化技术,PimPam充分利用了UPMEM提供的大量计算单元和丰富的内存带宽,这对于传统系统来说是一大挑战。相比传统的实现做了四个创新,以解决诸如负载均衡、数据分配和计算效率等问题:
1)PimPam提出了一个高效的模型来预测每个任务的工作量,从而实现任务的均匀分配。
2)PimPam设计了一种新的数据格式,更加紧凑地表示每个子图,有效地利用了每个计算单元有限的内存容量。
3)每个计算单元内部使用了一种自适应的协作算法,根据数据特点动态调整线程的协作方式,避免了并行度退化问题。
4)PimPam会动态地构建和销毁子邻接矩阵的位图表示,在有限内存限制下进一步加速特定模式的匹配速度。
该框架是图模式匹配首次在真实存内计算硬件上的实现,不仅推动了图数据处理领域的技术进步,也为未来利用PIM硬件进行大规模数据处理提供了新的可能性和方向。相关成果收录于SIGMOD 2024。本论文一作为清华大学姚班本科生蔡双羽。
更多信息请阅读论文:
1. NDPBridge: Enabling Cross-Bank Coordination in Near-DRAM-Bank Processing Architectures, Boyu Tian, Yiwei Li, Li Jiang, Shuangyu Cai, and Mingyu Gao, ISCA 2024.
2. UM-PIM: DRAM-based PIM with Uniform & Shared Memory Space, Yilong Zhao, Mingyu Gao, Fangxin Liu, Yiwei Hu, Zongwu Wang, Han Lin, Ji Li, He Xian, Hanlin Dong, Tao Yang, Naifeng Jing, Xiaoyao Liang, Li Jiang,ISCA 2024.
3. PimPam: Efficient Graph Pattern Matching on Real Processing-in-Memory Hardware, Shuangyu Cai, Boyu Tian, Huanchen Zhang, and Mingyu Gao, SIGMOD 2024.







