2024-01-15

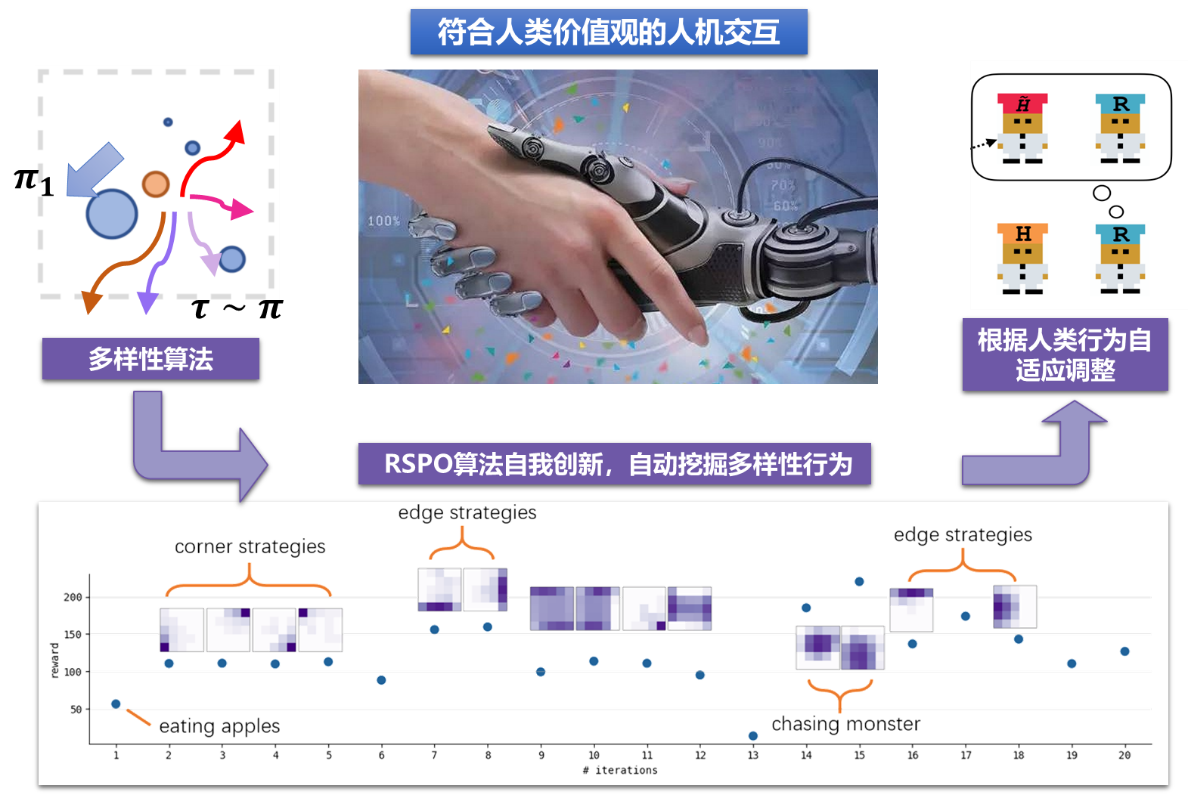
传统智能决策算法均基于最优性假设,即:在设定目标下求解最优策略并执行最优动作。然而最优性假设却并适用于需要与人类交互的协作场景。其根本问题是,人类的行为几乎从来不是最优的。因此人工智能必须认识到人类行为的多样性,并根据人类行为自适应调整决策,来帮助人类完成其目标。吴翼团队在领域内首次提出了多样性学习框架,从经典最优决策假设更进一步,要求智能体不光要解决问题,更要自我探索与创新,用尽量多不同的合理的拟人行为解决问题——即“不光要赢,还要赢的精彩”。基于多样性决策框架,吴翼团队还提出了多个多样性强化学习算法,并开源了多智能体决策代码库MAPPO。目前团队开发的多样性学习框架,是领域内首个能够在机器人控制、星际争霸、多人足球游戏等多个复杂任务场景中,都能自动探索出多样性策略行为的算法框架。同时,基于多样性策略为进行自我博弈训练,实现在miniRTS,overcooked等多个复杂人机合作场景中SOTA的表现,并且在真人测试中大幅超越目前领域内最好的泛化性强化学习算法,首次实现了在复杂游戏中与真人的智能协作,朝着让人工智能真正走进千家万户的最终目标,迈出了坚实的一步。团队系列成果发表于机器学习顶级会议ICLR2022、ICML2022、NeurIPS2022等,其中发表于NeurIPS2022的开源算法库MAPPO至今已经获得超过250次引用,受到领域内广泛关注。