
2021-10-22

影视配音是一项技术含量很高的专业技能。专业配音演员的声音演绎往往让人印象深刻。现在,AI也有望自动实现这种能力。近日,研究院PI赵行课题组联合字节跳动业内首次提出了神经网络配音器(Neural Dubber),该论文的第一作者为清华大学交叉信息研究院2021级博士生胡晨旭。这项研究能让AI根据配音脚本,自动生成与画面节奏同步的高质量配音,有望让影视后期效率倍增。

配音(Dubbing)广泛用于电影和视频的后期制作,具体指的是在安静的环境(即录音室)中重新录制演员对话的后期制作过程。 配音常见于两大应用场景:第一个是替换拍摄时录制的对话,如拍摄场景下录制的语音音质不佳,又或者出于某种原因演员只是对了口型,声音需要事后配上; 第二个是对译制片配音,例如,为了便于中国观众欣赏,将其他语言的视频翻译并配音为中文。
这项研究主要关注第一个应用场景,即“自动对话替换(ADR)”。在这一场景下,专业的配音演员观看预先录制的视频中的表演,并用适当的韵律(例如重音、语调和节奏)重新录制每一句台词,使他们的讲话与预先录制的视频同步。
为了实现上述目标,该研究团队定义了一个新的任务,自动视频配音(Automatic Video Dubbing, AVD), 从给定文本和给定视频中合成与该视频时序上同步的语音。
此前,行业内的很多研究是,根据给定语音生成与之同步的说话人的面部视频(Talking Face Generation)。而AVD任务正好相反,是用于生成与视频同步的语音,更加适用于真实的应用场景,因为影视作品拍摄的视频往往质量很高,并不希望再对其进行修改。
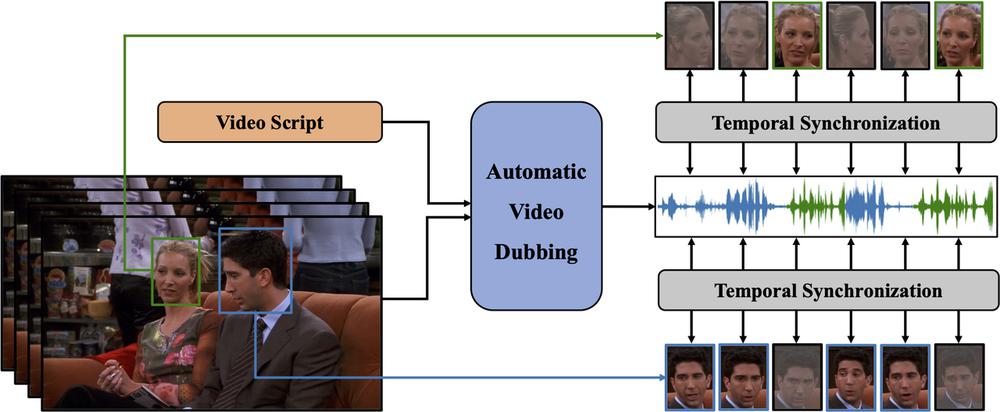
图1:自动视频配音(AVD)任务示意图。 给定文本和视频作为输入,AVD 任务旨在合成与视频在时间上同步的语音。 这是两个人互相交谈的场景。 面部图片是灰色,表示当时此人没有说话。
该研究团队提出的神经网络配音器(Neural Dubber)旨在解决自动视频配音(AVD)任务。这是第一个解决AVD任务的神经网络模型:能够从文本中端到端地并行合成与给定视频同步的高质量语音。 Neural Dubber 是一种多模态文本到语音 (TTS) 模型,它利用视频中的嘴部运动来控制生成语音的韵律,以达到语音和视频同步的目的。此外,该工作还针对多说话人场景开发了基于图像的说话人嵌入 (ISE) 模块,该模块使神经网络配音器能够根据说话人的面部生成具有合理音色的语音。
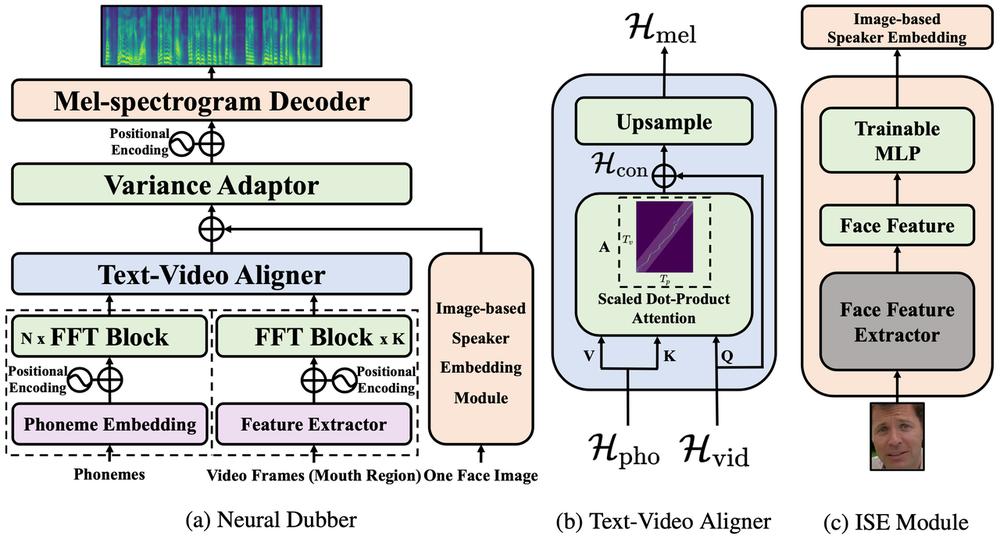
图 2:神经网络配音器(Neural Dubber)的模型结构。
神经网络配音器(Neural Dubber)将AVD任务具体建模成如下形式:给定音素序列和视频帧序列,模型需要预测与视频同步的梅尔频谱序列。神经网络配音器(Neural Dubber)的整体模型结构如图2所示。
在单说话人数据集 Chemistry Lectures 和多说话人数据集 LRS2 上的实验表明,神经网络配音器(Neural Dubber)可以生成与 SOTA 的语音合成模型在音质方面相当的语音。 最重要的是,定性和定量评估都表明,神经网络配音器可以通过视频控制合成语音的韵律,并生成与视频同步的高质量语音。
该成果的研究论文《Neural Dubber: Dubbing for Videos According to Scripts》已被机器学习和计算神经科学领域顶级学术会议NeurIPS 2021接受。该论文的第一作者为清华大学交叉信息研究院2021级博士生胡晨旭,通讯作者为赵行助理教授。其他作者包括加字节跳动的田乔、王玉平、王雨轩博士以及上海期智研究院研究助理黎庭乐。
论文地址:https://arxiv.org/abs/2110.08243
项目主页:https://tsinghua-mars-lab.github.io/NeuralDubber/









