高逸涵
我们的最终目的是设计一个数据库管理系统来辅助对大规模的关系型数据集的统计分析:系统核心是一个关系型数据库,但支持对其内容的自动统计推断:更具体地说,我们希望能够推断出数据集中缺失或不可获得信息的最可能的属性值(或分布信息)。这一推理过程的依据为用户所给定的所有推理上下文以及一些手动指定的标签(用于声明推理意图)。
我们可以列出了一些可能的该系统应实现的理想特性:
1. 简单性:系统应该允许用户以最少的工作量声明推理任务,并且应该对用户的专业技能做最少的假设。
2. 交互性:如果用户拥有足够的专业技能,系统应该允许用户以最少的操作来识别和纠正推理过程中的错误。
3. 资源控制:系统应该在使用合理数量的计算资源的情况下进行推理,并在资源消耗和推理精度之间实现平滑的权衡,并允许用户对资源分配有一定程度的控制。
4. 可解释性:系统应该对其推理结果提供解释,以便用户可以理解这种推理是如何完成的。
我们的目标是增强现有的关系型数据库管理系统的AI相关功能:系统应对自身进行配置以完成基本的人类推理,并自动识别可能的结果的统计推测。本质上,我们希望“自动化”人类推理,并用它来丰富和增强现有的关系数据集。值得注意的是,类似这样的系统本质上需要支持两种不同类型的工作负载:
1. 事务性工作负载:推理任务是预先配置的,但数据库的内容是动态的,其特点是大量的小事务修改了小的属性子集。系统应在必要时执行推理以保持推理结果最新。
2. 分析型工作负载:数据集是静态的,很少变化,但推理意图由数据分析师动态声明,以交互式的方式对数据集进行分析以发现数据集的潜在价值。
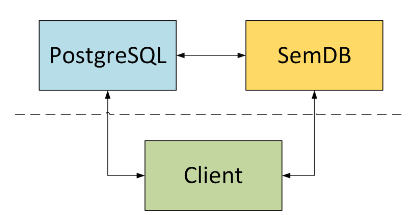
就目前的技术趋势而言,这两种类型的工作负载很可能需要由不同的内部引擎来处理,本课题目前主要考虑事务性工作负载的场景。系统的实现依托于开源数据库PostgreSQL,并附带有图形界面的客户端,整个系统框图如下图所示: