上海期智研究院PI,清华大学交叉信息研究院助理教授。
博士毕业于美国卡内基梅隆大学计算机系,曾任Snowflake博士后研究员。本科毕业于美国威斯康星大学麦迪逊分校。主要研究方向是云数据库系统、索引/过滤器数据结构、列存数据格式等。
个人荣誉
2022 ACM SIGMOD中国新星奖
2021年SIGMOD吉姆·格雷博士论文奖(SIGMOD Jim Gray Doctoral Dissertation Award)
2021 世界人工智能大会 WAIC 云帆奖
2021年国家自然科学基金海外优青项目
2020 Communications of the ACM (CACM) Research Highlight
2018 SIGMOD Best Paper Award
云数据库系统:运用首创的“成本智能”概念,设计全新的云原生数据库系统架构
索引/过滤器数据结构:设计性能优秀且内存消耗小的索引和过滤器来加速数据库查询
列存数据格式:设计下一代开源列式存储格式 (聚焦机器学习类负载和GPU解码性能)
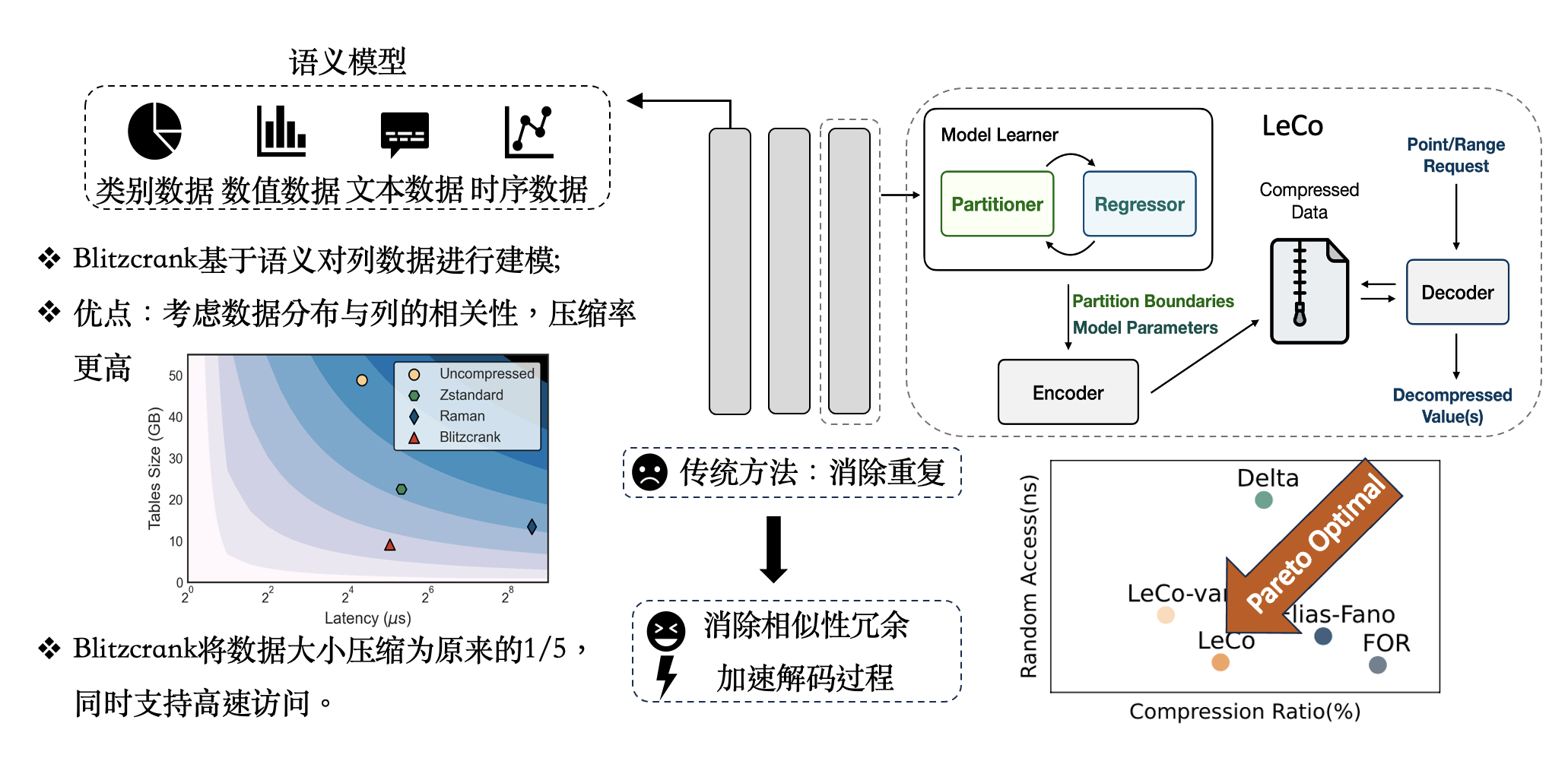
成果6:LeCo—基于机器学习的轻量级数据压缩(2024年度)
当今海量数据的产生与对查询极高的响应时间要求,让大数据压缩技术面临着全新的挑战。轻量级数据压缩是一项使列存储在分析查询中表现出优越的性能的关键技术。大量的已有工作都基于字典编码展开,而少有系统地利用列中的序列相关性进行压缩的工作。
相对于传统的消除数据重复的思路,张焕晨团队从一个全新的角度建模数据压缩问题,首次提出了Learned Compression(LeCo)数据压缩框架,一个利用机器学习自动消除相似性冗余以实现出色压缩比和解压性能的框架。LeCo将现有算法融入框架中,使得压缩率突破信息熵下界,同时加速解码过程以提升后续计算的效率。
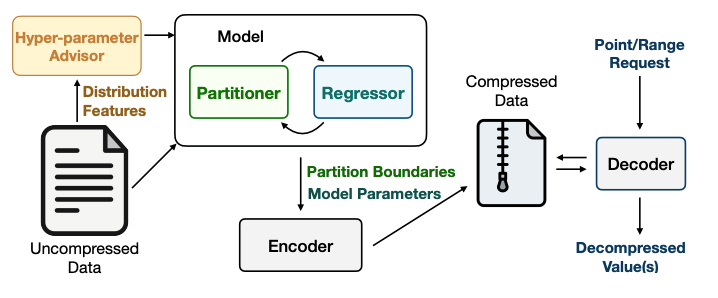
图1. LeCo框架 - 各模块及其交互概述 LeCo框架的核心创新在于: (1)使用机器学习来识别和利用数据中的序列相关性,这是之前研究中未被系统性利用的领域。 (2)提出了一种通用方法,将现有的算法如Frame-of-Reference (FOR)、Delta编码和Run-Length编码(RLE)作为特殊情况纳入其框架。 (3)通过形状编码技术,将序列划分和回归模型结合,以实现高效的压缩。 (4)包含一个超参数顾问,用于选择最佳的回归模型类型和压缩比。
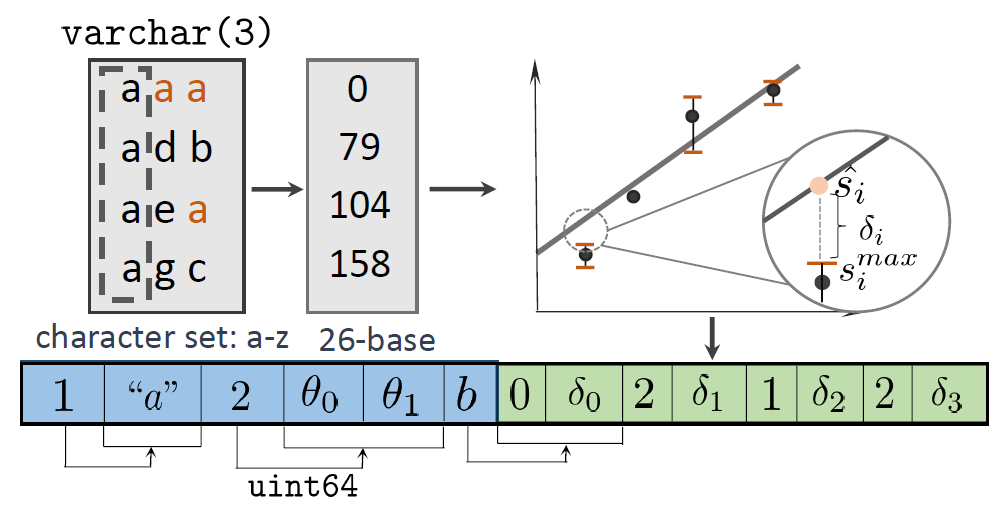
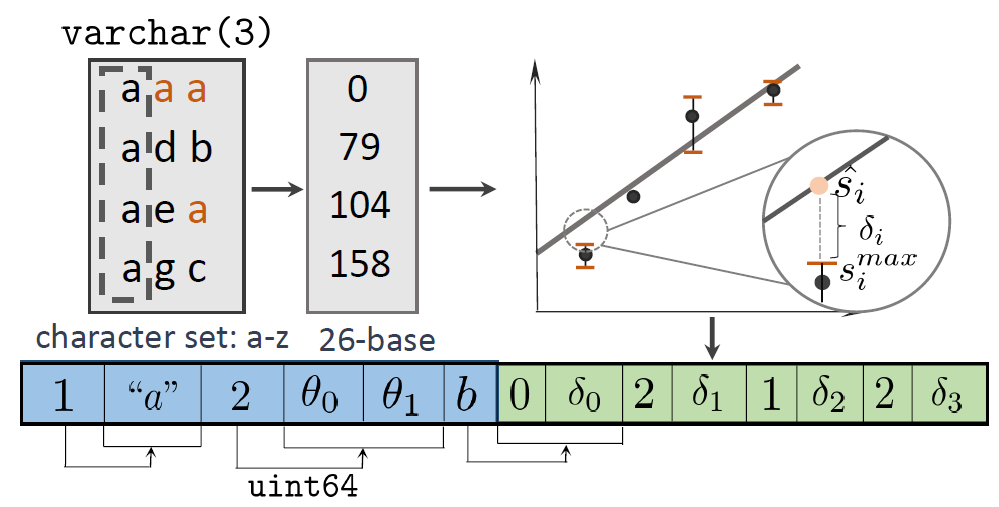
图2. LeCo字符串压缩 - 包括算法和存储格式修改的示例
在实验测试的十二个数据集上,LeCo在压缩比和随机访问速度上比现有解决方案实现了Pareto改进。将LeCo集成到广泛使用的系统中时,在列式执行引擎Arrow+Parquet上有5.2倍的查询加速,而在RocksDB中的吞吐量增加了16%。
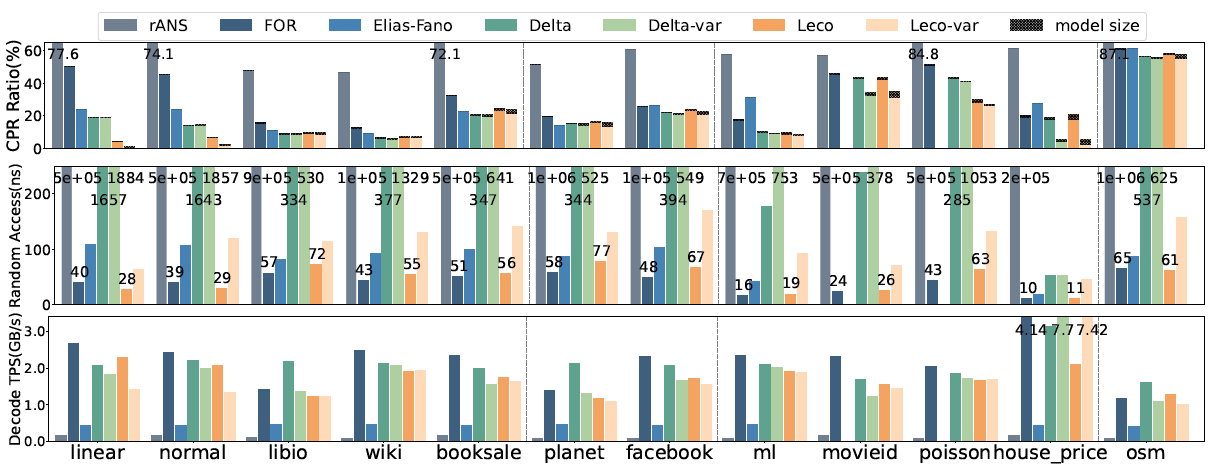
图3. 压缩微基准测试 针对现实系统中的混合事物分析场景,提出了系统性压缩的工具链。在列存的基础上,提出解决方案LeCo,用数据挖掘和模式识别技术将单列数据的分布信息凝缩在模型中,并存储错误修正码以实现无损压缩。在多个真实系统测试中,该压缩方案凭借突出的压缩率与轻量级解压操作提升查询速度、缓解内存瓶颈,在Parquet读取和Hash join算子中有着高至12倍和96倍的速度提升。 图4. 性能-空间的权衡 LeCo框架的应用价值体现在能够为现代数据分析系统提供更高的性能和存储效率,同时保持了良好的兼容性和易用性。LeCo在不同的工作负载和数据集上都展现出了卓越的性能,证明了其在实际应用中的潜力。本论文一作为上海期智研究院实习生、清华大学交叉信息学院博士生刘奕好。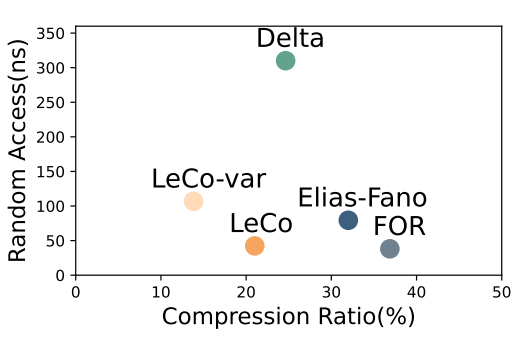
论文信息:LeCo: Lightweight Compression Via Learning Serial Correlations, Yihao Liu, Xinyu Zeng, Huanchen Zhang*, SIGMOD 2024.
------------------------------------------------------------------------------------------------------------------------------
成果5:通过形状编码构建LSM-Tree全局范围过滤器—GRF(2024年度)
LSM-Tree是一种非常常见的键值对数据存储引擎。LSM-Tree在磁盘上维护多个排序数组,牺牲了部分查询性能来换取高效的写入性能。随着数据量的扩大以及排序数组个数的增加,查询这些过滤器的时间逐渐变成了性能瓶颈。过往工作通过建立全局过滤器,减少过滤器查询次数的方式来降低这一瓶颈。但是过往的全局过滤器往往无法加速范围查询,同时在并发查询的场景下会产生正确性的问题。
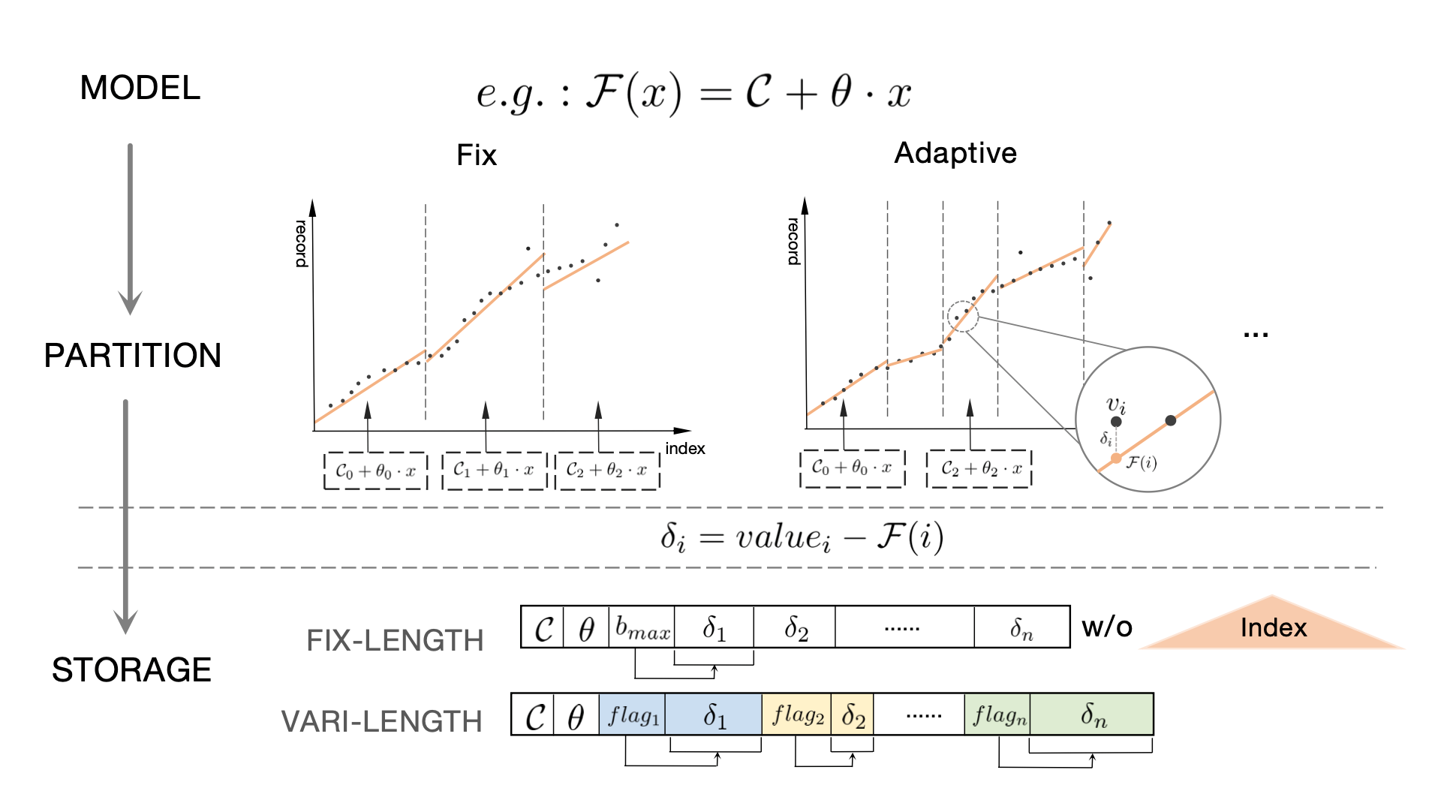
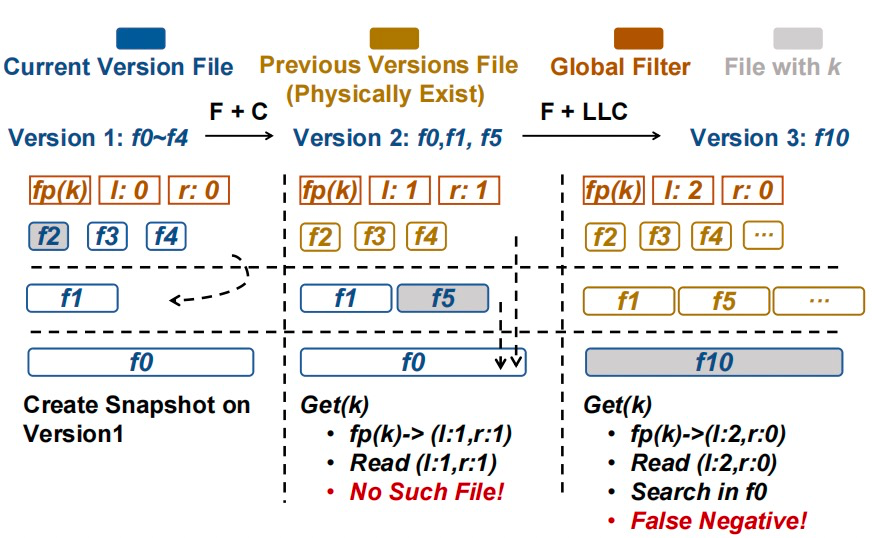
图1. 全局过滤器的多版本并发控制(MVCC)问题
张焕晨团队提出了一种全局范围过滤器结构(GRF)来减少查询过滤器的时间开销。在不产生额外内存开销的情况下将全局过滤器支持了范围查询,通过形状编码来保证查询结果在并发场景下的正确性。
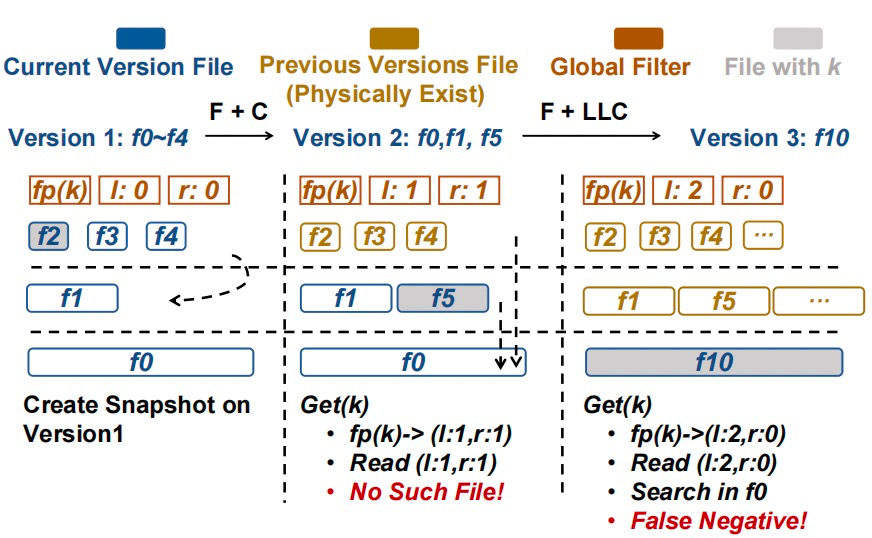
图2. GRF概览
GRF的优点具体包括:
(1)可以同时加速点查询和范围查询。
(2)使用形状编码技术来存储每个键在LSM-Tree中的分布情况。与传统的过滤器相比,形状编码能够更有效地表示键的未来位置,从而减少每次压缩操作时所需的更新。
(3)通过支持MVCC增强了并发查询的能力,解决了并发读写场景下查询结果不正确的问题。
(4)该数据结构的维护代价很低,在LSM-Tree合并多个排序数组的时候不需要额外处理,由此提高了LSM-Tree的写性能。
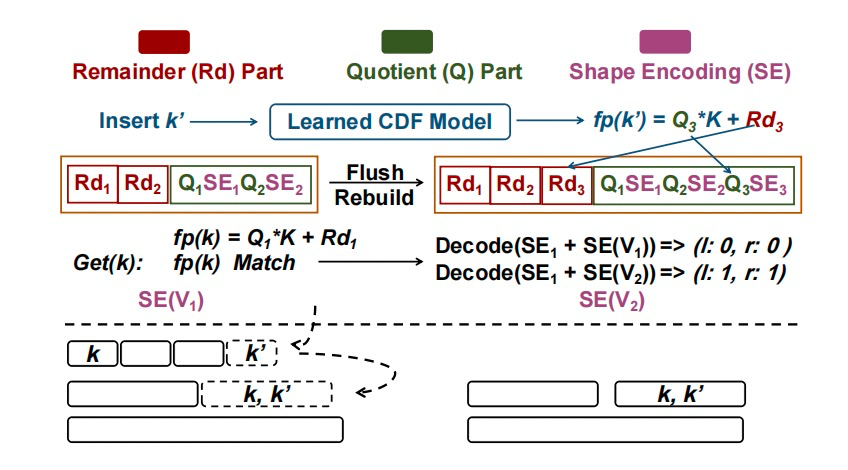
图3. 在具有形状编码的快照中搜索键
该工作提出的GRF在提高数据库系统性能,尤其是在需要处理大量写入和查询的现代应用场景中,具有显著的应用价值。本论文一作为上海期智研究院实习生、清华大学交叉信息学院博士生王恒睿。
论文信息:GRF:A Global Range Filter for LSM-Trees with Shape Encoding, Hengrui Wang, Te Guo, Junzhao Yang, Huanchen Zhang*, SIGMOD 202
------------------------------------------------------------------------------------------------------------------------------
成果4:使内存中的学习型索引在磁盘上高效(2024年度)
近年来,学习型索引已成为数据库管理系统的研究热点。然而,目前最先进的学习型索引主要针对内存场景设计,与基于磁盘的数据库管理系统并不完全匹配。为解决这一问题,张焕晨团队提出了一套通用的转换和优化准则(SGACRU),并将其应用于现有的内存型学习型索引。这一通用转换方法能够有效将内存中的学习型索引转化为适用于磁盘场景的索引,同时获得比之前更快的查询速度和更少的内存占用。
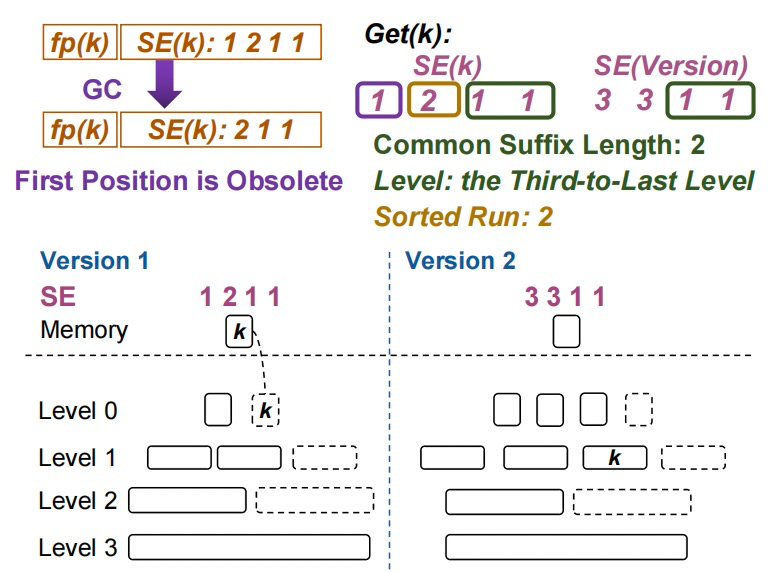
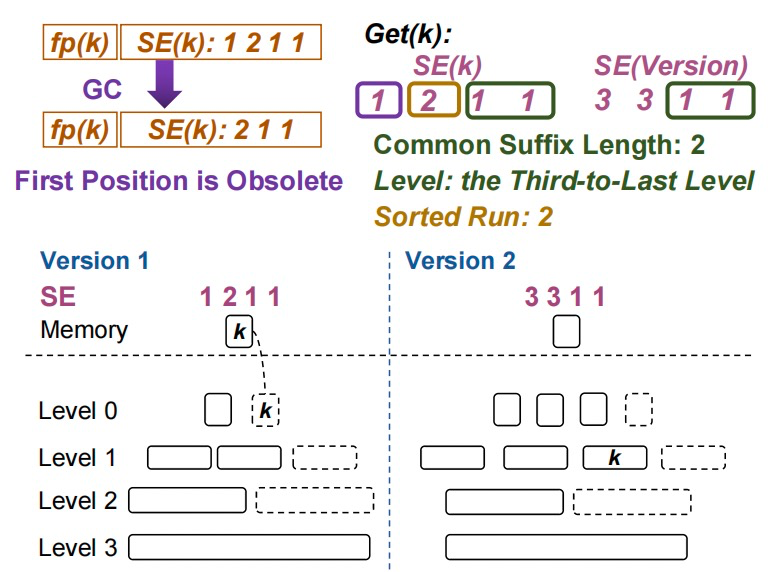
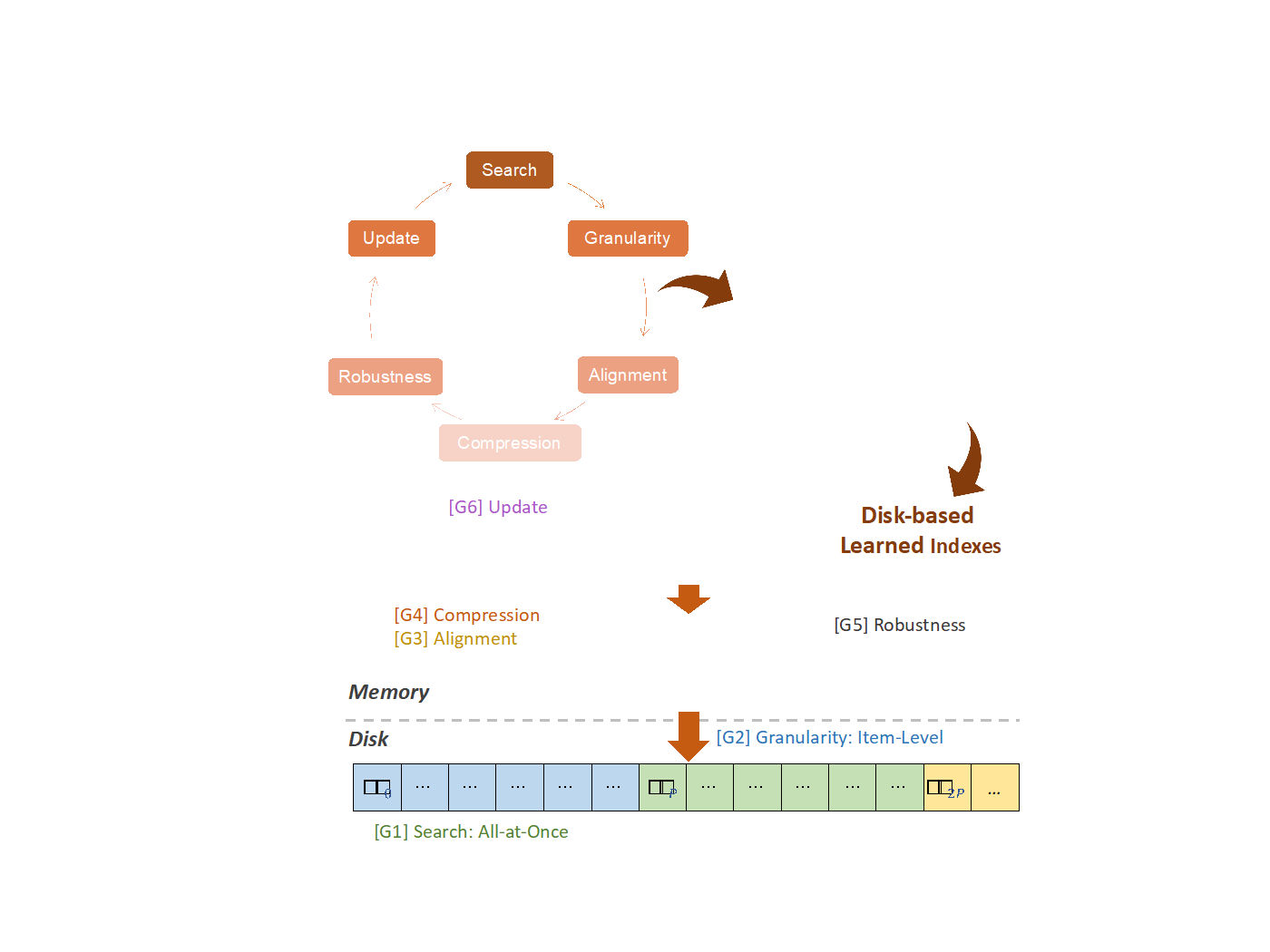
图1. SGACRU架构
SGACRU准则包括:
G1: (Search) 根据磁盘和工作负载特征,在“最后一英里”搜索期间确定叶页获取策略。
G2: (Granularity) 确定学习模型的预测粒度(例如,项与页)。
G3: (Alignment) 利用页面对齐扩展索引训练的错误界限,以减少模型数量,同时保持相同的预期I/O页面。
G4: (Compression) 通过压缩模型参数减少内存使用,接受与主导I/O时间相比微不足道的CPU开销增加。
G5: (Robustness) 对于CDF难以学习的数据集,回退到高效压缩的区域映射索引。
G6: (Update) 使用混合索引进行高效更新。
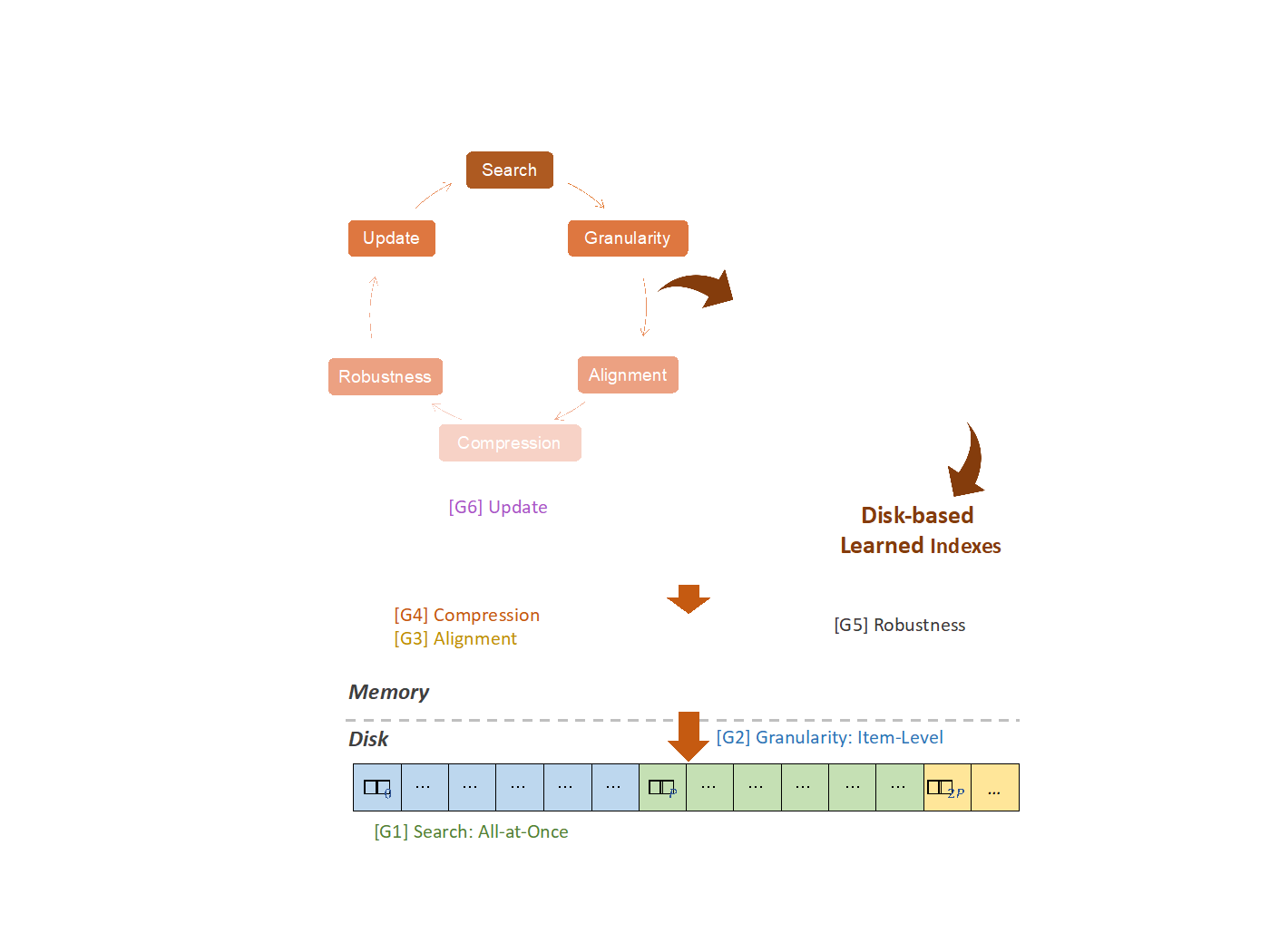
图2. CPU时间与I/O时间对比
这一套通用的转换和优化准则在提升索引结构的速度、空间利用、鲁棒性、智能化水平等方面具有显著优势,同时减轻了研究人员设计磁盘场景下学习型索引的负担。具体包括:
(1)结合磁盘特性和学习型索引的特点,提出了内存和磁盘交互、模型预测的粒度两方面的优化策略,以加速基于磁盘的学习型索引的响应速度。
(2)总结了多种学习型索引的构建算法,并提出通用的优化,可以显著减少索引的内存占用,同时保持高效的查询性能。
(3)从功能性和鲁棒性的角度分别提供相应的优化策略,有助于研究人员更好地理解和高效使用学习型索引。
(4)这一通用转换方法可应用于现有的内存中的学习型索引,使研究人员无需为磁盘场景重新设计索引结构,从而有效提高了开发效率。
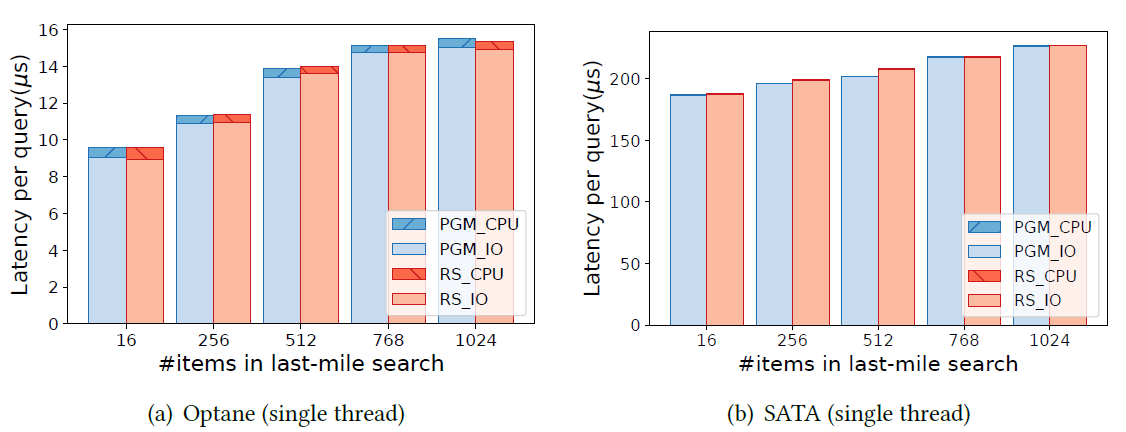
图3. 在Facebook数据集上与FILM的吞吐量和空间成本比较
该工作提升了学习索引在磁盘上的性能和效率,推动了人工智能与数据库融合的学习型索引的发展,具有重要的理论和应用价值。本论文一作为上海期智研究院实习生、清华大学交叉信息学院博士生张缴怡。
论文信息:Making In-Memory Learned Indexes Efficient on Disk, Jiaoyi Zhang, Kai Su, Huanchen Zhang*, SIGMOD 2024
------------------------------------------------------------------------------------------------------------------------------
成果3:迈向成本智能的云数据库(2023年度)
几十年来,数据库的研究一直专注于优化固定资源下的系统性能。随着越来越多的数据库应用迁移到公有云,我们认为在解决数据库优化问题时,数据库的运行成本应该和性能一起成为“一等公民”。张焕晨团队联合美国最具实力的云数据库服务公司Snowflake,首创了“成本智能”的概念,并为此设计了全新的云原生数据库系统架构。我们重点研究了云原生数据库实现成本智能的两个关键挑战:高效的资源自动部署以及成本导向的数据库自动调优。我们在论文中指出了当今云数据库在解决这两项挑战时仍欠缺的组件。这些新组件中的每一个都代表了一个该领域急需研究的方向。论文已在数据库系统核心会议CIDR发表,并获得广泛关注。依据该论文为蓝图的全新系统正在清华和上海期智研究院紧张开发中,有望成为学术界首个开源的云原生数据仓库。
研究领域:云数据库系统
研究论文:Huanchen Zhang, Yihao Liu, and Jiaqi Yan. “Cost-Intelligent Data Analytics in the Cloud”. Proceedings of the 2024 Conference on Innovative Data Systems Research (CIDR), January 2024.
论文链接:https://www.cidrdb.org/cidr2024/papers/p78-zhang.pdf
------------------------------------------------------------------------------------------------------------------------------
成果2:列式存储格式的深入实证剖析(2023年度)
列式存储是现代数据分析系统的核心组件之一。许多数据库管理系统都广泛使用 Apache Parquet 和 Apache ORC 等开源存储格式,以促进跨平台数据共享。这些存储格式大多是在2010年代初为 Hadoop 生态系统开发的,然而过去的十几年间,硬件的性能和数据库的负载都发生了显着变化。张焕晨团队联合美国卡内基梅隆大学通过大量实验,深入研究了当今最广泛使用的开源列式存储格式的内部结构,梳理总结了其使用的各项压缩、编码、索引、以及元数据管理技术的优缺点。我们还对越来越重要的机器学习型负载(如高维向量搜索)以及现有格式在GPU上的解码性能做了全面的测试。结果显示现有列存格式在此类负载中性能低效。这项研究为下一代通用列式存储格式的提出与开发做了重要的准备工作。我们的论文在数据库顶会VLDB发表,并一度登上Hacker News Trending Top 3.
研究领域:列式存储
研究论文:Xinyu Zeng, Yulong Hui, Jiahong Shen, Andrew Pavlo, Wes McKinney, and Huanchen Zhang.“An Empirical Evaluation of Columnar Storage Formats”. Proceedings of the VLDB Endowment (VLDB 2023), 17.2: 148-161.
论文链接:https://www.vldb.org/pvldb/vol17/p148-zeng.pdf
------------------------------------------------------------------------------------------------------------------------------
成果1:大数据压缩(2023年度)
数据压缩在大数据处理中起到节省存储成本和加速查询等至关重要的作用。当今海量数据的产生与对查询极高的响应时间要求,让大数据压缩技术面临着全新的挑战。相对于传统的消除数据重复的思路,张焕晨团队从一个全新的角度建模数据压缩问题,结合机器学习技术深度消除数据中的相似性冗余,使得压缩率突破信息熵下界,同时加速解码过程以提升后续计算的效率。针对现实系统中的混合事物分析场景,提出了系统性压缩的工具链。在列存的基础上,提出解决方案LeCo,用数据挖掘和模式识别技术将单列数据的分布信息凝缩在模型中,并存储错误修正码以实现无损压缩。在多个真实系统测试中,该压缩方案凭借突出的压缩率与轻量级解压操作提升查询速度、缓解内存瓶颈,在Parquet读取和Hash join算子中有着高至12倍和96倍的速度提升。同时,在行式存储场景中,张焕晨团队提出Blitzcrank方法。它对大数据语义进行建模,使用贝叶斯网络描述数据依赖和相似性关系,最高可达到20倍的压缩比。张焕晨团队对于数据压缩的上述尝试解决了现有系统的性能瓶颈,并且让该领域看到从消除数据相似性冗余入手实现压缩仍大有可为,为AI大数据处理提供了更坚实的存储基础。
10. GRF:A Global Range Filter for LSM-Trees with Shape Encoding, Hengrui Wang, Te Guo, Junzhao Yang, Huanchen Zhang*, SIGMOD 2024.
9. LeCo: Lightweight Compression Via Learning Serial Correlations, Yihao Liu, Xinyu Zeng, Huanchen Zhang*, SIGMOD 2024.
8. Making In-Memory Learned Indexes Efficient on Disk, Jiaoyi Zhang, Kai Su, Huanchen Zhang*, SIGMOD 2024.
7. SALI: A Scalable Adaptive Learned Index Framework based on Probability Models, Jiake Ge, Huanchen Zhang, Boyu Shi, Yuanhui Luo, Yunda Guo, Yunpeng Chai, Yuxing Chen, and Anqun Pan*, SIGMOD 2024.
6. PimPam: Efficient Graph Pattern Matching on Real Processing-in-Memory Hardware, Shuangyu Cai, Boyu Tian, Huanchen Zhang, and Mingyu Gao*, SIGMOD 2024.
5. Chen, Zheng, Feng Zhang, Jiawei Guan, Jidong Zhai, Xipeng Shen, Huanchen Zhang, Wentong Shu, and Xiaoyong Du,CompressGraph: Efficient Parallel Graph Analytics with Rule-Based Compression,To Appear in Proceedings of the 2023 International Conference on Management of Data (SIGMOD). 2023.
4. Wang, Ke, Guanqun Yang, Yiwei Li, Huanchen Zhang, and Mingyu Gao,When Tree Meets Hash: Reducing Random Reads for Index Structures on Persistent Memories,To Appear in Proceedings of the 2023 International Conference on Management of Data (SIGMOD). 2023.
3. Cha, Hokeun, Xiangpeng Hao, Tianzheng Wang, Huanchen Zhang, Aditya Akella, and Xiangyao Yu,Blink-hash: An Adaptive Hybrid Index for In Memory Time Series Databases,To Appear in Proceedings of the VLDBEndowment 16. 2023
2. Anneser, Christoph, Andreas Kipf, Huanchen Zhang, Thomas Neumann, and Alfons Kemper,Adaptive Hybrid Indexes,2022 In Proceedings of the 2022 International Conference on Management of Data (SIGMOD)
1. Knorr, Eric R., Baptiste Lemaire, Andrew Lim, Siqiang Luo, Huanchen Zhang, Stratos Idreos, and Michael Mitzenmacher,Proteus: A Self-Designing Range Filter,2022 In Proceedings of the 2022 International Conference on Management of Data (SIGMOD)