
2024-07-10
上海期智研究院PI、清华大学助理教授吴翼团队,近期在大语言模型对齐、大模型策略智能体框架、自适应梯度策略优化等方面取得了一系列重要研究成果。对大模型与人类偏好对齐,及强化学习领域复杂决策制定具有重要价值。相关3项成果收录在今年的ICML 2024中,其中关于使用PPO算法进行大模型对齐训练的论文被大会选为口头报告 (Oral,录取率1.6%) 。
Innovation Highlights
1. 团队通过理论分析和实验验证,探讨了在人类偏好对齐大型语言模型 (LLMs) 领域,直接偏好优化 (DPO) 与近端策略优化 (PPO) 两种强化学习方法的优劣。解决了学术界关于DPO是否真正优于PPO的争议,并提出了如何更好地使用两种对齐算法。在困难的代码竞赛题中,通过改进后的PPO算法,采用更小的开原模型,超越了Google的AlphaCode模型,取得了新的SOTA结果。
2. 团队提出了一种将大模型和强化学习结合的策略智能体框架,克服大模型智能体决策动作分布中的固有偏好,构建具有强决策能力的语言智能体。得到的策略语言智能体在狼人杀这一语言博弈游戏中胜率显著优于其他AI智能体,并在人机实验中达到了人类玩家的水平。
3. 团队提出了一种自适应梯度策略优化方法 (AGPO) ,解决可微分仿真器非平滑性导致的策略优化问题。我们的方法将Q函数视为未来回报的代理,通过分析批量梯度方差,自主选择更稳定的Q函数计算梯度以避免非平滑的仿真梯度对策略优化的干扰。
Achievements Summary
关于LLM对齐算法的DPO和PPO的综合研究
近年来,大型语言模型 (LLMs) 通过在大量文本数据集上进行预训练,获得了广泛的语言模式和知识。为了更好地在各个领域利用LLM的丰富知识,一个关键挑战是如何在各式各样的下游任务中将LLM的输出和人类的偏好进行对齐。在之前的工作中,学术界和工业界广泛采用基于奖励模型的Proximal Policy Optimization (PPO) 算法和直接偏好优化 (Direct Preference Optimization,DPO) 算法。但是从没有人系统性地研究过两种算法的优劣和如何更好地利用这它们进行LLM的对齐。
吴翼团队系统性地研究了DPO,PPO等对齐算法在各种模型规模,各种任务上的优劣势。首先从理论上分析了DPO方法存在的固有缺陷,如对分布偏移敏感,可能导致学习到的策略偏向于分布之外的响应。并总结出了在实践中如何更好地利用DPO算法。通过在对话任务和代码生成任务上的实验,团队验证了提升DPO算法在LLM输出分布和偏好数据分布相差比较大时,DPO的表现会明显下降,并据此提出DPO算法在实际应用中缩小分布差距的一些方法,比如在偏好数据集上进行额外的SFT,或者进行迭代式的训练,这些方法均取得了显著成效。

图1. PPO算法在大模型安全性评测上的表现
(对应原文Table 2)
同时,团队也提出了提升PPO算法表现的几大重要因素,即PPO训练中批大小 (Batch Size) 需要比较大;同时Advantage Normalization有助于保证训练的稳定性;最后,训练中对参考模型 (reference model) 进行缓慢更新也有助于提升LLM在下游任务的表现。

图2. 不同任务上PPO算法效果的消融研究

图3. 在Apps测试集上的结果

图4. 在CodeContests数据集上的通过率
最终,吴翼团队在困难的代码竞赛任务验证了算法改进的效果,并取得了SOTA的结果。该研究不仅推动了LLM对齐技术的发展,也为可信AI的研究设立了新的标杆。相关成果收录于ICML 2024中,并将进行Oral口头报告(录取率1.6%)。本论文一作为上海期智研究院实习生、清华大学交叉信息研究院博士生徐树声。
在狼人杀中实现策略性游戏的强化学习语言智能体
随着大模型的发展,大模型智能体在许多场景中展现出了巨大的潜力。然而,在复杂决策任务中,纯大模型智能体的动作分布中往往表现出固有偏好,从而导致智能体无法作出最优决策。以简单的石头剪刀布为例,其最优策略为以1/3的概率随机选择一个动作,而基于GPT-4的智能体在分析出最优策略的情况下仍有0.67的概率选择选择出石头,这样的固有偏好导致纯大模型智能体在复杂博弈任务中能力不足,难以作出最优决策。

图5. 纯大模型智能体决策动作分布中的固有偏好
吴翼团队与汪玉团队合作提出一种将大模型与强化学习结合的策略智能体框架,以狼人杀这一语言博弈游戏为测试环境构建具有强决策能力的语言智能体。该框架由3个模块组成:模块1使用大模型整理关键信息,并推理隐藏信息辅助后续决策;模块2使用大模型生成多个不同的候选动作,避免单一动作导致的固有偏好;模块3使用强化学习优化动作集合上的概率分布,提高智能体的决策能力。通过将大模型和强化学习结合,实现具有强决策能力的语言智能体。

图6. 策略语言智能体框架
该框架实现的策略语言智能体在狼人杀这一测试环境中展现了远超纯大模型智能体的决策水平。在特定场景的案例分析中,策略语言智能体成功克服了动作分布中的固有偏好,掌握了最优策略;在与现有AI智能体的对抗中,策略语言智能体胜率显著高于其他智能体;在与人类玩家的人机实验中,策略语言智能体的胜率达到了和人类玩家相近的水平,并涌现了多样的策略性游戏行为。

图7. 狼人首夜动作分布,策略语言智能体成功克服固有偏好
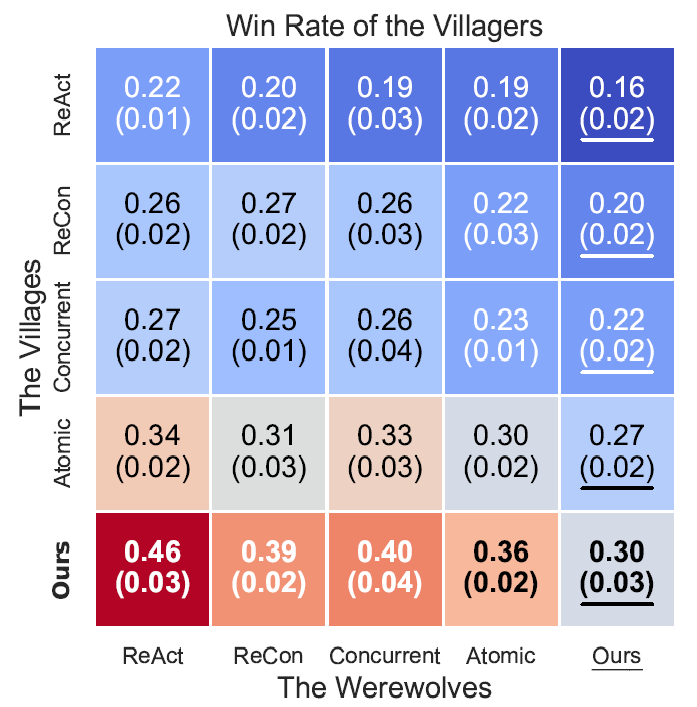
图8. AI智能体对抗胜率矩阵,策略语言智能体显著优于其他智能体
通过将大模型和强化学习结合,策略语言智能体克服了纯大模型智能体动作分布中的固有偏好,强化了在复杂博弈任务中的决策能力,使大模型智能体能在更广泛的场景中得到应用。相关成功收录于ICML 2024中。本论文一作为清华大学交叉信息研究院博士生徐泽来。
自适应梯度策略优化:增强非平滑可微分仿真器中的策略学习
随着仿真技术的进步,可微分仿真器在策略学习中展现出巨大的潜力,通过直接利用仿真梯度优化策略模型,可以显著加速策略优化过程并增强策略模型的性能。然而,在动力学仿真中出现非平滑过渡时,直接使用仿真梯度进行策略优化并不能有效实现策略学习。这类非平滑场景常见于机器人仿真中丰富接触的情况下,限制了该方法的广泛应用。

图9. AGPO算法的计算流图
针对这个问题,吴翼课题组提出了一种自适应梯度优化方法 (AGPO) 。该方法引入了Q函数作为未来回报的代理,通过分析批量梯度的方差,发现Q函数梯度相比于仿真梯度和策略梯度具有更高的稳定性,能够在各种非平滑情况下保证稳定的策略优化效果。

图10. 对三种梯度估计器优化空间的比较:纯仿真梯度(SG)、仿真梯度和策略梯度的混合 (SG+PG) 、以及仿真梯度和Q函数梯度的混合 (SG+QG) 。
基于此,AGPO算法自适应地计算Q函数梯度和仿真梯度的混合比例,利用更稳定的Q函数梯度以绕过非平滑的仿真梯度干扰,实现高效的策略学习。实验结果表明,AGPO在性能上优于纯RL基线和现有的基于仿真梯度的策略优化方法。在理论方面,我们证明了AGPO的收敛性及其对梯度方差和偏差的依赖性。此外,AGPO具有较低的方差上限,即使在时间跨度长且动力学非平滑的情况下,方差也不会显著增加。

图11. QG (左) 和1步SG (右) 用于计算α的详细计算图
该研究有效解决了非平滑可微分仿真中策略学习的问题。AGPO通过智能混合模拟梯度(SG) 和Q函数梯度 (QG),在保持算法稳定性的同时显著提升了学习效率。这一进步对于机器人控制、计算机动画和其他需要复杂决策制定的领域具有重要的应用价值,预示着在仿真基础学习和决策制定方面的重要突破。相关成果收录于ICML 2024中。本论文一作为清华大学交叉信息研究院博士生高枫。
更多信息请阅读论文:
1. Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study, Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, Yi Wu, https://openreview.net/pdf?id=6XH8R7YrSk, Oral, ICML 2024.
2. Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game, Zelai Xu, Chao Yu, Fei Fang, Yu Wang, Yi Wu, https://arxiv.org/pdf/2310.18940, ICML 2024.
3. Adaptive-Gradient Policy Optimization: Enhancing Policy Learning in Non-Smooth Differentiable Simulations,Feng Gao*, Liangzhi Shi*, Shenao Zhang, Zhaoran Wang, Yi Wu,https://openreview.net/pdf?id=S9DV6ZP4eE, ICML 2024.







