
2024-07-11
上海期智研究院PI、清华大学助理教授袁洋,近期在聚焦于自监督学习 (Self-Supervised Learning, SSL) 的理论和方法,尤其是在理解不同自监督学习方法的内在机制和提高学习效果方面取得了一系列重要研究成果。将矩阵信息理论应用于自监督学习中,以此来分析和改进学习方法,对自监督学习领域具有重要价值。相关2项成果收录在今年的ICML 2024中。
Innovation Highlights
研究团队提出了一个新的自监督学习方法Matrix-SSL,该方法利用矩阵信息理论对最大熵编码框架进行解释,提出了矩阵均匀性损失和矩阵对齐损失的新概念。实验结果表明,Matrix-SSL在ImageNet数据集上的线性评估设置以及MS-COCO的迁移学习任务中都优于现有的最新方法。
研究团队通过矩阵互信息的视角对两种双分支(Siamese架构)自监督学习方法,即Barlow Twins和Spectral对比学习进行了综合分析,证明了这些方法的损失函数隐含地优化了矩阵互信息和矩阵联合熵。引入了矩阵变分掩码自动编码器Matrix Variational Masked Auto-Encoder (M-MAE),该方法在自监督学习基准测试中表现出显著的性能提升。
Achievements Summary
基于矩阵信息论的自监督学习
自监督学习 (Self-Supervised Learning, SSL) 是一种无需人工标注数据即可学习数据表示的技术。在该领域中,对比学习 (Contrastive Learning) 和非对比学习 (Non-contrastive Learning) 是两种主要方法。袁洋团队与上海交通大学黄维然老师合作提出了一个新的自监督学习方法Matrix-SSL,该方法利用矩阵信息理论对最大熵编码框架进行解释,提出了矩阵均匀性损失和矩阵对齐损失的新概念。
Matrix-SSL方法通过引入矩阵信息理论,将对比学习和非对比学习方法的优势结合并增强。该方法不仅在ImageNet数据集的线性评估设置下表现优异,而且在迁移学习任务中显著提升了性能。例如,在MS-COCO数据集上的对象检测任务中,Matrix-SSL在仅进行400个epoch预训练的情况下,相比于之前的SOTA方法如MoCo v2和BYOL提升了3%。此外,在语言建模领域,通过矩阵交叉熵损失对大语言模型进行微调,在GSM8K数据集上的数学推理任务中,相比于标准交叉熵损失提高了3.1%。

图1. Matrix-SSL 架构设计
通过扩展经典的熵、KL散度和交叉熵概念,研究团队提出矩阵信息理论用于矩阵形式的表示。该研究证明了最大熵编码 (MEC) 损失与矩阵均匀性损失的等价性,并通过矩阵信息论的角度解释最大熵编码方法,提出了矩阵对齐损失,从而提高了自监督学习方法的表现。实验验证表明,Matrix-SSL在多个任务中均表现优越。

图2. ImageNet数据集上的线性评估结果
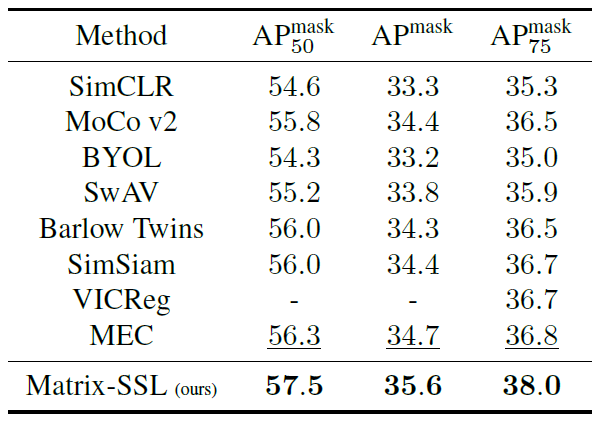
图3. 在实例分割任务上的迁移学习对比
通过这一研究,袁洋研究团队为自监督学习方法提供了新的理论工具,为未来的机器学习算法设计提供了新的方向和思路。相关成果收录于ICML 2024中。本论文一作为清华大学交叉信息研究院博士生张伊凡、杨景钦,清华大学数学系博士生谭智泉。
自监督学习中的信息流
袁洋团队与上海交通大学黄维然老师合作,利用矩阵信息论工具,即矩阵互信息和联合熵,对现有的自监督学习方法中的对比学习 (contrastive learning) 和特征解相关学习 (feature decorrelation-based learning) 进行了深入分析。证明了Barlow Twins和谱对比学习 (spectral contrastive learning) 的损失函数在优化过程中隐式地最大化了矩阵互信息和矩阵联合熵,并揭示了这些量在对比学习和特征去相关学习中的关键作用。
这一见解促使我们进一步探索单分支算法的类别,特别是MAE和U-MAE,其中互信息和联合熵变为熵。在此基础上,我们引入了矩阵变分掩码自动编码器 (Matrix Variational Masked Auto-Encoder, MMAE),该方法利用基于矩阵的熵估计作为正则化器,并将U-MAE作为一种特例。实证评估强调了M-MAE在与现有最先进方法相比时的有效性,包括在ImageNet数据集上线性评估ViT-Base时提高了3.9%,在微调ViT-Large时提高了1%。

图4. 在CIFAR10数据集上矩阵基础互信息(左)&联合熵(右)的可视化
实验证明,M-MAE在自监督学习基准测试中表现出显著的性能提升,例如在ImageNet数据集上进行线性评估时,M-MAE的表现优于MAE和U-MAE,准确率分别为62.4%和66.0%。

图5. 在ImageNet数据集上进行线性评估对比
研究团队通过矩阵信息理论改进自监督学习方法,特别是在图像分类和分割任务上显示出超越监督学习的性能。未来,这种方法有望广泛应用于无监督表示学习、数据压缩、异常检测等领域,推动机器学习模型在更少标注数据的情况下实现更好的泛化能力。相关成果收录于ICML 2024会议中。
更多信息请阅读论文:
1. Matrix Information Theory for Self-Supervised Learning, Yifan Zhang, Zhiquan Tan, Jingqin Yang, Weiran Huang, Yang Yuan, https://arxiv.org/pdf/2305.17326, ICML 2024.
2. Information Flow in Self-Supervised Learning, Zhiquan Tan, Jingqin Yang, Weiran Huang, Yang Yuan, Yifan Zhang, https://arxiv.org/pdf/2309.17281, ICML 2024.







