
2024-10-23

Innovation Highlights
1. 赵行团队提出了一种全新的人形机器人Parkour学习框架,通过端到端的基于视觉的全身控制策略,实现了无需运动先验的多技能Parkour,如跳高、跃障、爬低等。该框架创新性地使用了分形噪声来训练机器人,简化了奖励函数设计,并采用了两阶段强化学习方法和多GPU加速策略,实现了从模拟到真实世界的零样本迁移。
2. 赵行团队提出使用不确定性导向的决策Transformer (Decision Transformer) 来将离线强化学习应用于自动驾驶的运动规划。通过条件互信息来估算驾驶过程中状态转移的不确定性,并根据估计的不确定性对驾驶动作序列进行切分,将受到环境随机性影响的全局收益替换为确定的每段局部收益,从而解决决策Transformer在随机收益作为条件学习下失效的问题。
Achievements Summary
人形机器人跑酷

自从四足机器人的高动态强化学习让四足机器人的运动能力和通过性远超传统轮式机器人,人形机器人虽然有各种各样的硬件被设计制造了出来,但是运动控制算法大多局限在平地或者平缓的小台阶范围。这因为之前的强化学习算法大多依赖一个预先设定好的平地行走的动作参考,或者手动设计平地行走的关键运动学参数。这些方法逼迫双足机器人在任何需要移动的时候都必须抬脚,并且需要设计新的参考动作才能完成更加复杂的移动通过任务。赵行团队提出让人形机器人的移动,可以像最简单的训练机器狗一样,并且可以结合机载视觉系统,让人形机器人通过极度复杂,甚至不连续的地形。
团队创新借鉴了四足机器人上常用的分型噪声生成粗糙的地形,加上基础的强化学习奖励函数,让人形机器人能够自主产生稳定性走的步态,从而省去了设计针对某种机器人型号的动作参考的巨大工作量,让人形机器人的移动算法回归简单的实现方式。

图1. 用Perlin Noise在不同地形上产生粗糙的表面,用scan dot作为expert policy对环境感知的方法
此外,团队还验证了人形机器人在移动操作中的可能性。即使本次工作的神经网络是训练用于同时控制上肢和下肢,在复写上肢动作后,下肢仍然能够成功的保持平衡,并且根据遥操作指令准确执行上肢动作。为进行复杂的地形移动同时上肢进行操作的需求提供了可行性参考。
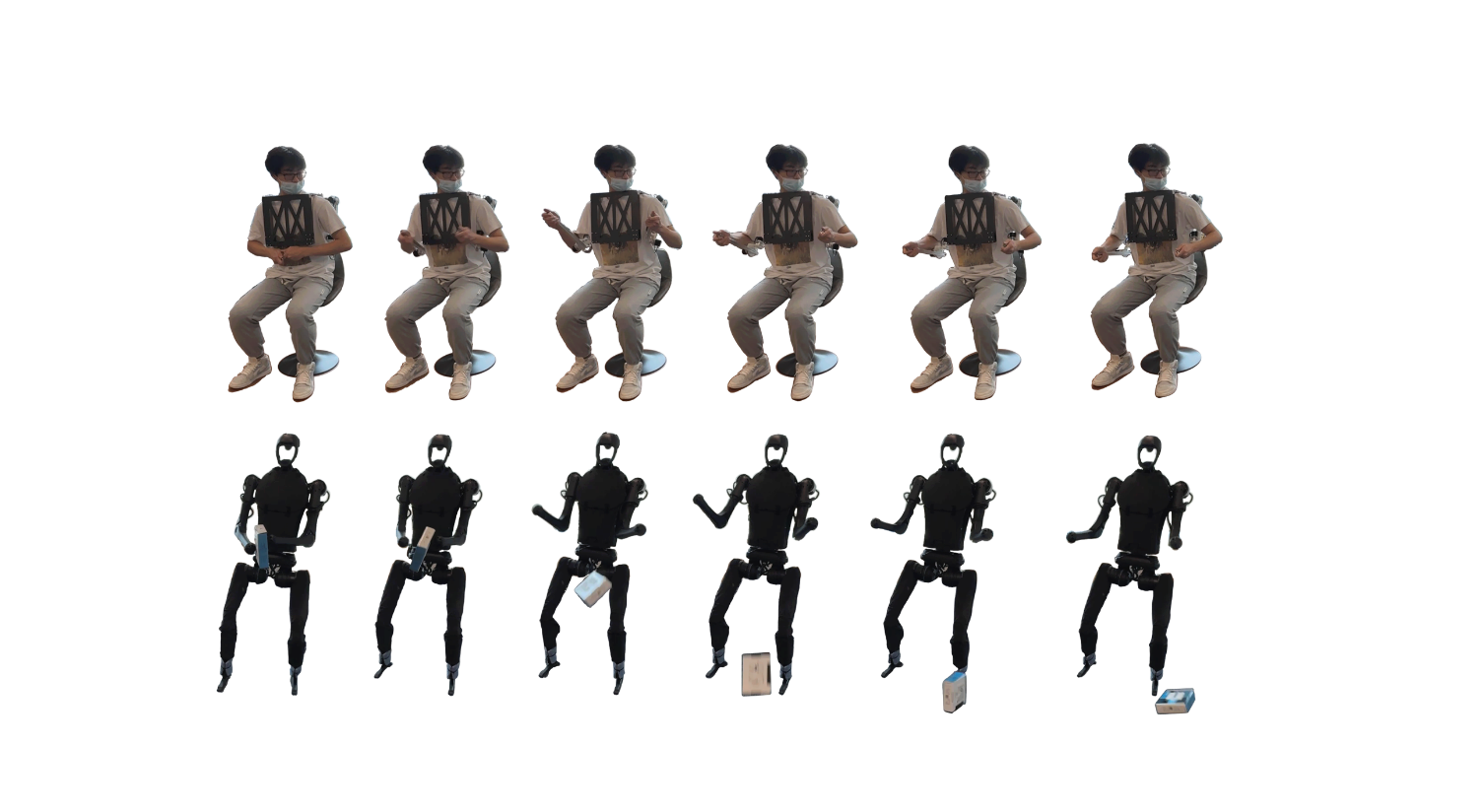
图2. 使用远程操作设置覆盖跑酷策略的动作
该研究推动了人形机器人在敏捷性、自主性和多任务能力方面的发展,为未来人形机器人在搜索救援、娱乐表演甚至日常生活中的应用奠定了基础。本论文一作为研究院实习生、清华大学交叉信息院博士生庄子文,通讯作者为清华大学交叉信息院助理教授赵行。共同作者为研究院实习生、上海科技大学本科生姚屾喆。
论文信息:
Humanoid Parkour Learning, Ziwen Zhuang, Shenzhe Yao, Hang Zhao†, https://openreview.net/forum?id=fs7ia3FqUM, CoRL 2024.
针对随机驾驶环境的不确定性导向决策Transformer
虽然学界广泛认为强化学习在自动驾驶运动规划任务中有着巨大的潜力,但由于真车交互的安全性问题,通常难以保障能够学习到模型所需求的边缘场景,这就导致了强化学习通常只能在驾驶仿真器中进行交互学习。一种可能的解决方案是利用离线强化学习从离线收集的真车驾驶数据中进行学习,而决策Transformer正是一个代表性的离线强化学习方案。Transformer能够有效地对驾驶过程的长序列进行学习,但也会受到环境随机性影响,学习到的动作可能会因为环境变化而无法达到训练时预期的收益。因此,如果能找到一种方案解决决策Transformer的确定性收益依赖,就可能将离线强化学习广泛应用于自动驾驶任务当中。
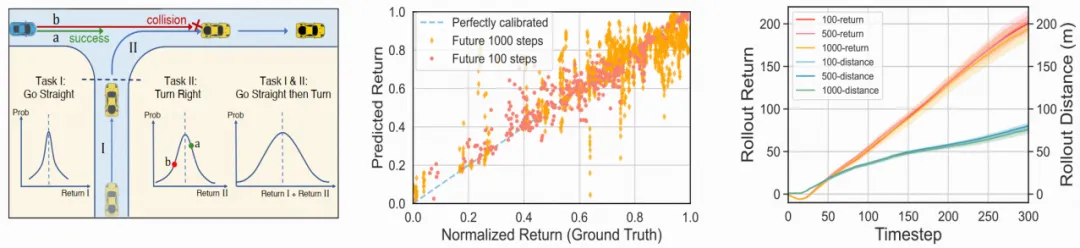
图3(左)切分驾驶任务后收益不确定性降低
(中)不确定性随驾驶步长累计
(右)优化未来不同步长的最优驾驶动作近似完全一致
赵行团队基于自动驾驶场景下“不确定性累计”和“时序局部性”性质,提出使用条件互信息来估计驾驶过程中的状态转移不确定性,进而依据估计结果切分序列,将受到环境随机性影响的全局收益替换为确定的每段局部收益。具体来说,不同于原决策Transformer直接将整段驾驶序列作为输入学习,模型会在估计状态转移不确定处切分输入序列,并将条件收益保留为至切分点的确定性奖励总和,从而保证从训练集中学习的动作可以稳定泛化至测试集取得相近收益。
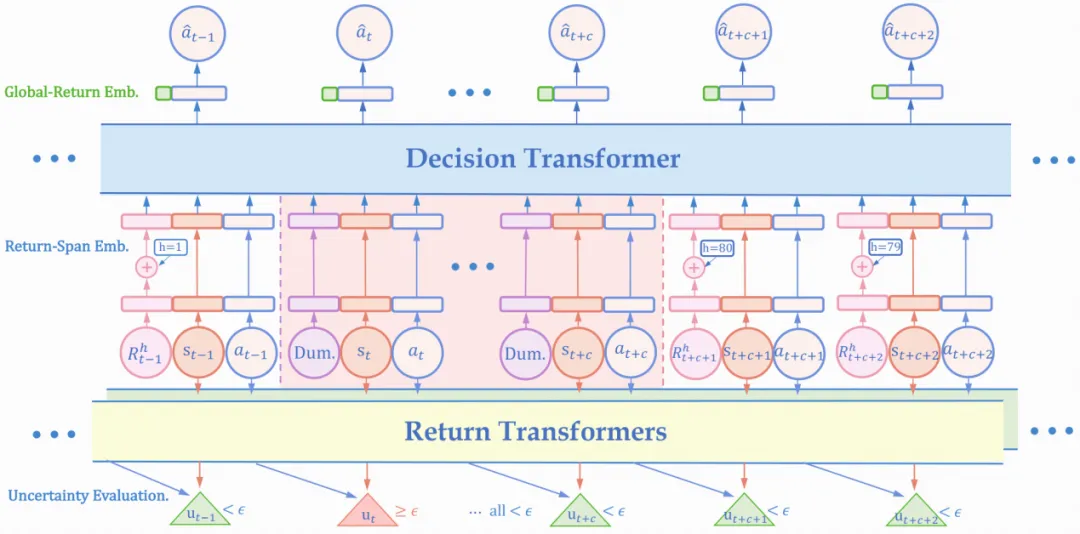
图4. 不确定性导向的决策Transformer训练框架
赵行团队首先从CARLA仿真器的多种城镇地图/天气组合中收集30h的驾驶数据。之后首先使用两接收不同状态输入(相差一个时间步)的Transformer训练估计收益分布,用二者之间的分布差距作为不确定性度量切分之前提取得到的数据集进行决策Transformer训练。然后在测试环境中,模型仍会对实时接收到的环境状态不确定性进行估计和序列划分,再使用训练好的决策Transformer进行动作规划。
在仅使用离线收集数据、不进行任何交互的情况下,模型在CARLA仿真器的新场景中取得了比SOTA离线强化学习模型更高6.5%的驾驶得分,并在多个边缘测试场景中作出了更鲁棒的动作规划。值得注意的是,模型的不确定性估计展现出了较强的可解释性,例如图6中自车在刚开始跟车时由于不确定前车行为导致不确定性上升,在适应之后不确定性快速下降。总的来说,该工作为离线强化学习在自动驾驶任务中的广泛应用提供了新的方案。
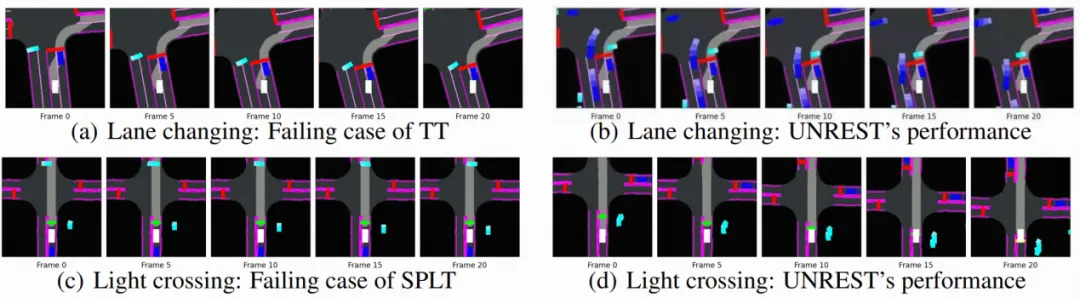
图5. 在不同边缘场景下模型(右)
相较Baseline(左)的表现
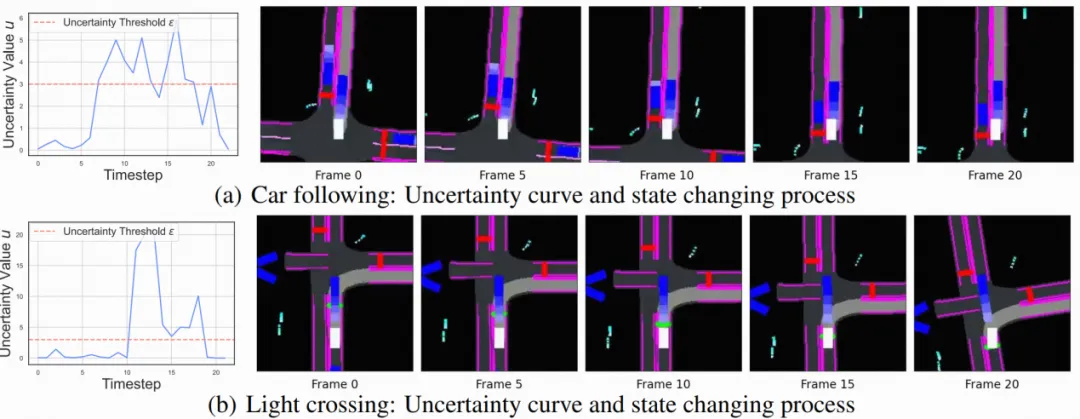
图6. 模型不确定性估计所展现出的可解释性
不确定性导向的决策Transformer为离线强化学习在自动驾驶运动规划中的应用提供了全新的思路。相关成果收录于CoRL2024(Oral)中。本论文一作为上海期智研究院实习生、清华大学博士生李泽楠,通讯作者为清华大学助理教授赵行。共同作者为上海期智研究院实习生聂帆,研究员孙桥,和轻舟智航大方。
论文信息:
Uncertainty-Aware Decision Transformer for Stochastic Driving Environments, Zenan Li, Fan Nie, Qiao Sun, Fang Da, and Hang Zhao†, https://arxiv.org/abs/2309.16397, CoRL 2024.










