
2024-10-23

Innovation Highlights
1. 高阳团队提出“基于大模型先验知识的强化学习”框架(Reinforcement Learning with Foundation Priors) 来促进具身智能体在操作任务中的学习效率和自主探索能力。该框架通过利用策略、价值和成功奖励等基础模型为智能体提供指导和反馈,成功地使机器人能够在真实环境和仿真环境中更高效地完成复杂的操作任务。
2. 高阳团队提出应用于灵巧手动态抛接物体的高效学习训练框架DexCatch。该方法在45个场景中(多样的手部姿势和物体)实现了73%的成功率,且所学习的策略在未见过的物体上展示了强大的零样本迁移性能。此外,在物体侧向朝手掌外的困难任务中,所有基线算法都无法完成任务,而提出的方法仍然实现了超过60%的成功率。
3. 高阳团队提出使用“通用流”(General Flow)来作为机器人学习的一种基础可供性表征 (Affordance)。该表征通过描述空间中被操作物体上若干3D点的未来走向,将操作者本体与操作技能进行解耦,从而建立起人类技能向机器人技能进行转移的桥梁。通过在人类视频上训练流表征预测模型并部署到实体机器人上,团队实现了从RGBD人类视频中提取可泛化的机器人操作技能,在没有使用任何机器人数据的前提下,于6个场景、18个任务上取得了81%的平均成功率。
4. 高阳团队提出“SGRv2框架”(Semantic-Geometric Representation V2),通过改进视觉和动作表征来提升机器人操作任务中的样本效率。团队引入了关键的归纳偏置——动作局部性,即机器人的动作主要由目标物体及其与局部环境的关系决定。基于此,团队提出了一种编码器-解码器架构,并采用逐点预测和加权平均等策略来生成动作预测。通过在多个仿真基准测试上的广泛评估,团队展示了SGRv2卓越的效果和强大的样本效率。
Achievements Summary
基于大模型先验知识的强化学习:一种通往具身智能体高效率与自主学习的框架
基于大模型先验知识的强化学习(Reinforcement Learning with Foundation Priors, RLFP) 框架为机器人在复杂操作任务中的学习和自主探索能力提供了重要突破。机器人在现实世界中的应用,特别是在操作复杂物体时,往往受到强化学习算法数据需求量大、手动奖励设计繁琐等问题的限制。为了克服这些挑战,团队提出了RLFP框架,通过利用大模型(如策略、价值和成功奖励模型)的先验知识,为强化学习过程提供反馈和指导,从而显著提升了机器人在探索新环境时的效率,并减少了对手动设计奖励函数的依赖。
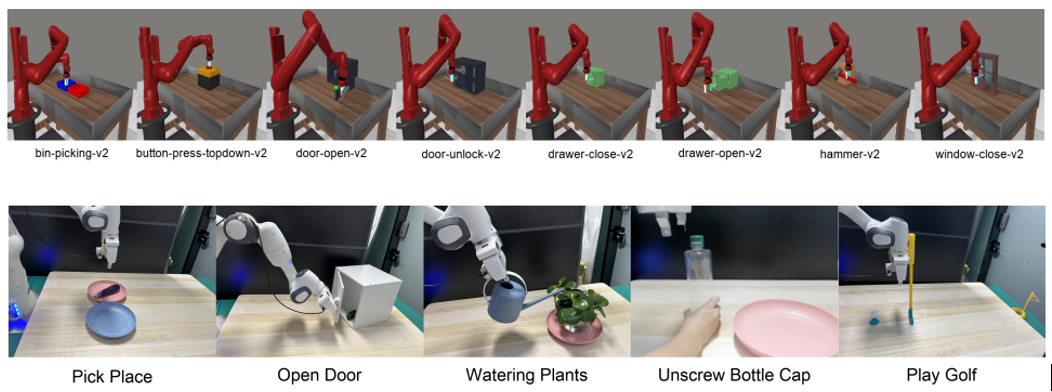
图1. FAC算法的测试环境(含8种模拟场景和5种真实场景)
高阳团队创新性地提出了基础模型引导的Actor-Critic(Foundation-guided Actor-Critic, FAC)算法,旨在自动生成奖励函数,并为机器人提供智能探索路径。该算法通过结合分层强化学习和基础模型的预训练策略,解决了机器人在真实世界中操作任务中常见的样本效率低和手动奖励设计难的问题。

图2. 大模型先验策略知识的失败案例和FAC的成功案例
RLFP框架提出的创新在于通过大模型的先验信息来引导强化学习过程,极大减少了手动工程设计的工作量。FAC算法通过自动生成奖励和引导策略,允许机器人更快适应任务环境,从而减少了传统RL方法中大规模数据采集和繁琐的奖励函数设计。
RLFP框架及FAC算法有效解决了机器人操作任务中数据采集成本高和奖励函数难以设计的问题。传统的强化学习方法往往需要数百万次的环境交互,而RLFP仅需不到1小时的训练时间,便能在仿真和真实环境中取得显著成功。该方法在5个真实机器人任务中的平均成功率达到86%,而在Metaworld模拟器中的8个任务中,RLFP框架在其中7个任务中实现了100%的成功率,大幅超越了基于手动设计奖励的基准方法。
RLFP框架为机器人自主探索和复杂任务操作提供了全新的解决方案,具有重要的实际应用潜力。它不仅加速了强化学习算法在真实世界中的落地,还为未来机器人能够自主学习、应对更多样化任务奠定了基础。该框架对机器人感知能力、底层控制策略及复杂环境中的自适应学习提供了研究新思路,展示了在强化学习与机器人领域的广泛应用前景。
相关成果收录于CoRL2024中并受邀请进行口头报告(Oral)。本论文一作为研究院实习生、清华大学交叉信息院博士生叶葳蕤,通讯作者为交叉信息院高阳助理教授。共同作者为上海研究院实习生张云生、研究员辜先凡,清华大学本科生翁颢洋、王孟晨,研究院实习生、清华大学博士生王圣杰、张彤,加州大学伯克利分校Pieter Abbeel教授。
论文信息:
Reinforcement Learning with Foundation Priors: Let the Embodied Agent Efficiently Learn on Its Own, Weirui Ye, Yunsheng Zhang, Haoyang Weng, Xianfan Gu, Shengjie Wang, Tong Zhang, Mengchen Wang, Pieter Abbeel, Yang Gao†, https://arxiv.org/pdf/2310.02635, CoRL 2024 ( Oral ).
DexCatch: 使用灵巧手学习抛接任意物体
灵巧手的研究旨在匹配人类手部的复杂能力,研究人员利用强化学习技术应用于灵巧手的多项任务,解决了如开门、组装乐高和解魔方等操控任务。尽管抓取-放置行为能满足许多日常任务的需求,但动态投掷-接物有望更高效地完成任务。例如,两台机器人可以通过投掷-接物来高效传递物体,可以扩展工作空间的同时来避免机器人之间的碰撞。然而,精准接住任意物体仍然极具挑战性。首先,高动态的接触会导致物体从手中掉落。之前的无模型强化学习研究在投掷-接物任务中成功率接近0%。其次,不同物体的属性(如质量分布、摩擦力、形状)要求接物行为足够稳健,尤其是需要能适应日常各类物品。为此,之前的方法需学习物体动力学,增加了系统复杂性。第三,面对从随机方向飞来的物体,接物手必须采用不同姿势,尤其在侧面朝向时,物体缺少手掌支撑而容易掉落,而这一挑战更是尚未被研究。
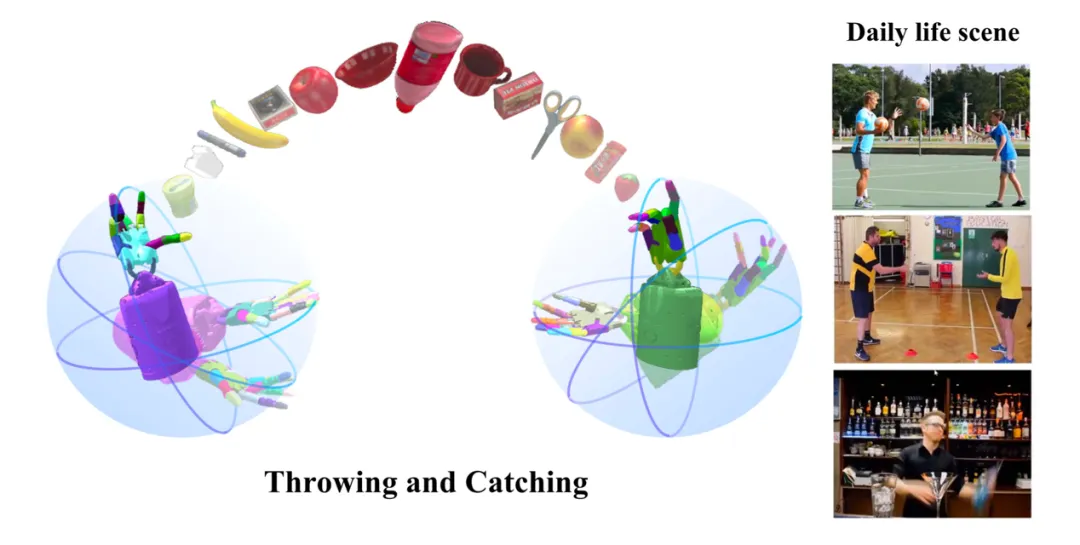
图3. 使用影子手进行投掷和接住物体的泛化任务
为了解决上述三大挑战,团队提出了一个基于强化学习的框架,用于使用灵巧手完成投掷-接物任务。这一简单但高效的框架能够在多种日常物体和不同的投掷-接物场景中(无论手掌朝上还是朝侧)实现出色的性能。DexCatch的核心算法设计包括:
1)提出了一种混合优势估计方法,在传统优势估计中引入了李雅普诺夫稳定性和内在奖励。虽然稳定性的约束主要用于保证控制系统的稳健性,但本项目是首次观察到其可以让策略生成的动态抓取物体的行为更为稳定有效,从而提高了投掷-接物的准确性。
2)通过使用物体点云的压缩特征作为输入,并在训练过程中应用域随机化,提出的方法在处理具有不同属性(如质量分布、摩擦力、形状和初始姿态)的物体时表现出色,即使面对此前未见过的物体也能有效完成抓取。
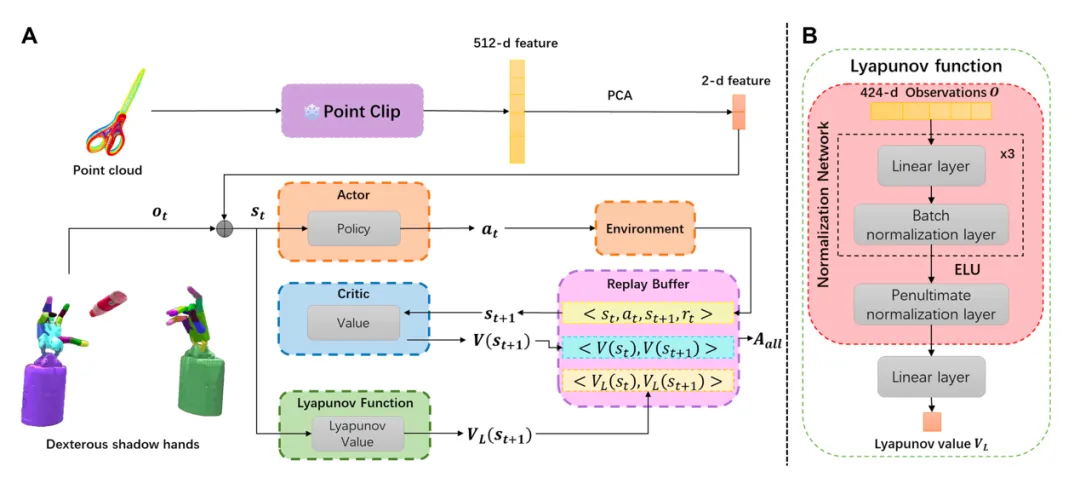
图4. DexCatch网络结构图
为了测试算法的泛化能力,团队使用YCB_Pybullet数据集中的物体进行训练和测试。结果显示,提出的算法在各类手势构型的任务上均优于基线算法,如TRPO,SAC,DDPG 和PPO。同时该方法展示了在灵巧手投掷-接物任务中可以泛化出不同抓取手势的能力,从而能成功操控各种物体。此外,由于对物体点云信息的引入,以及物体质量、惯量和重心位置等进行加噪,该方法在训练和测试物体上都能保持较高的成功率。
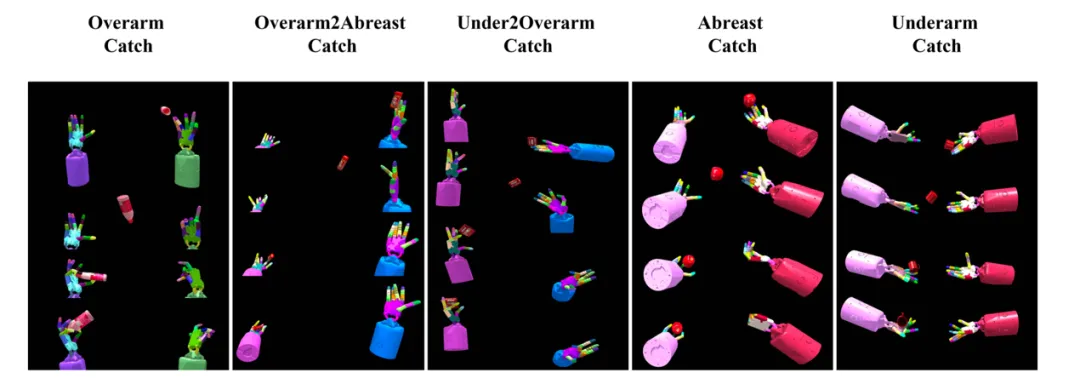
图5.多组仿真实验结果
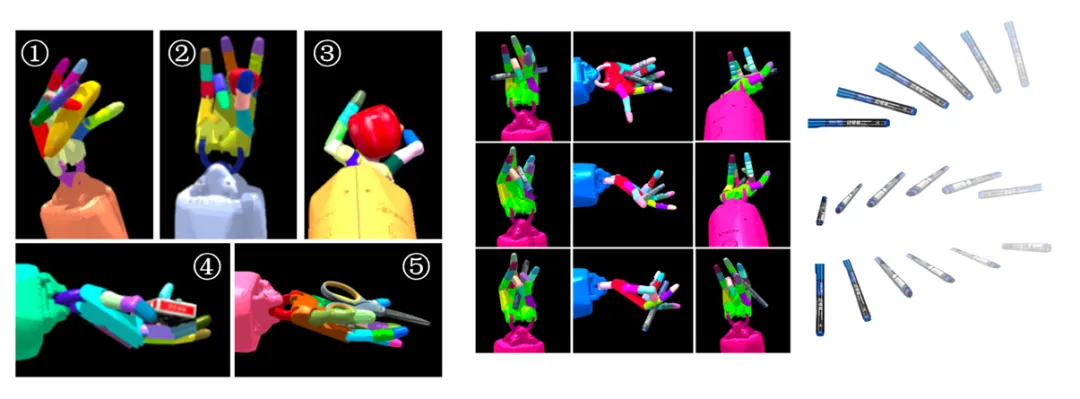
图6.灵巧手抓取手势的泛化结果
DexCatch为灵巧手动态操作物体提出了一种新的可能。本论文一作为清华大学博士生兰沣卜和上海期智研究院实习生、清华大学博士生王圣杰,通讯作者为清华大学张涛教授和高阳助理教授。共同作者为清华大学本科生张赟喆,清华大学硕士生徐皓天,科罗拉多矿业学院博士生Oluwatosin Oseni,清华大学本科生张子叶。
论文信息:
DexCatch: Learning to Catch Arbitrary Objects with Dexterous Hands, Fengbo Lan*, Shengjie Wang*, Yunzhe Zhang, Haotian Xu, Oluwatosin Oseni, Yang Gao†, Tao Zhang†, https://dexcatch.github.io/, CoRL 2024.
通用流作为可扩展机器人学习的基础可供性表征
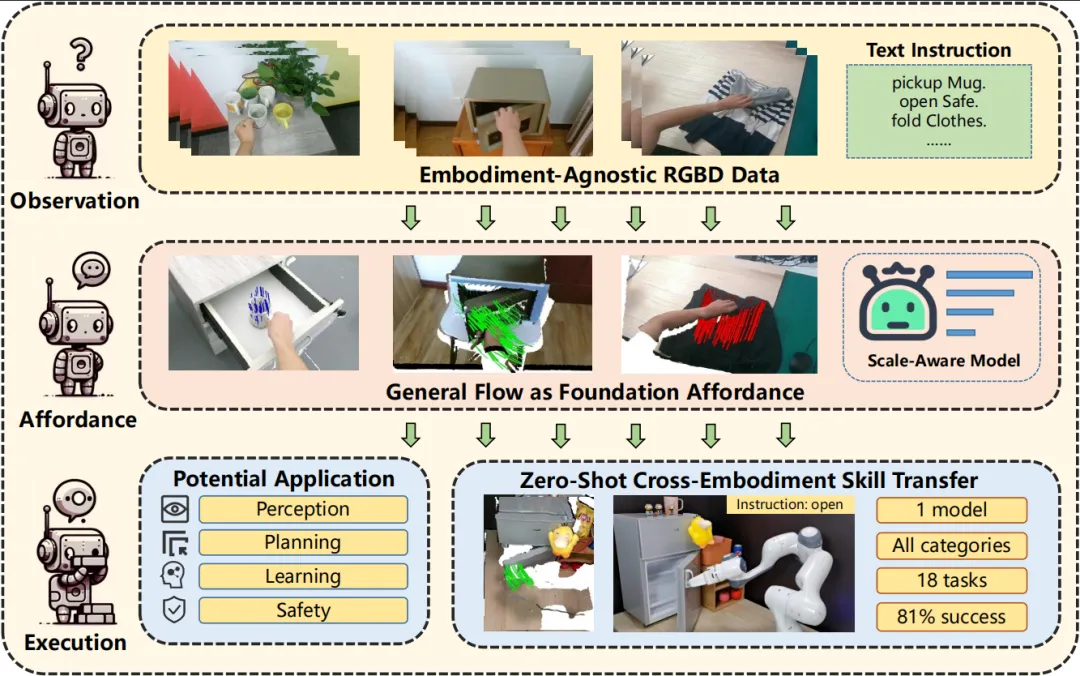
图7. 通用流(General Flow)作为一种基础可供性表征(Affordance)
由于收集机器人操作数据具有很高的时间成本,因此提高机器人操作数据的数量级十分困难,这也导致了现有的机器人模仿学习方法仅具有有限的可扩展性。一种可能的解决方案是引入人类操作视频数据集。人类操作与机器人操作具有较高的相似性,因此学界普遍认为人类操作视频能够为机器人操作提供先验。人类操作视频的收集较为简单,并且已有较大规模的收集量。因此,如果能够找到一种高效的从人类视频数据集中提取机器人技能的方法,就能够极大的提升机器人学习的可扩展性。高阳团队提出使用通用流(General Flow)作为一种基础可供性表征(Affordance),从而建立起从人类操作视频与机器人技能之间的桥梁。具体来说,General Flow描述被操作物体上若干3D点的未来移动轨迹。这一表征与操作者本体无关,但又精确描述了操作技能本身的动作形态,因此能够高效实现人类操作视频向机器人技能的转移。

图8. 通用流作为人类视频向机器人技能转移的中间表征
高阳团队首先使用原有数据标注、分割模型、追踪模型等从HOI4D数据集和自采集数据中提取通用流表征。然后基于PointNeXt点云预测架构,设计了基于尺度的流表征预测模型,并使用之前提取得到的数据集进行训练。然后,团队将流表征预测模型部署到真实机器人上。具体来说,给定场景点云和被操作物体上的若干3D点,机器人首先使用预训练好的预测模型预测通用流表征。然后,机器人移动物体,使得物体尽可能的跟随预测的流表征轨迹。
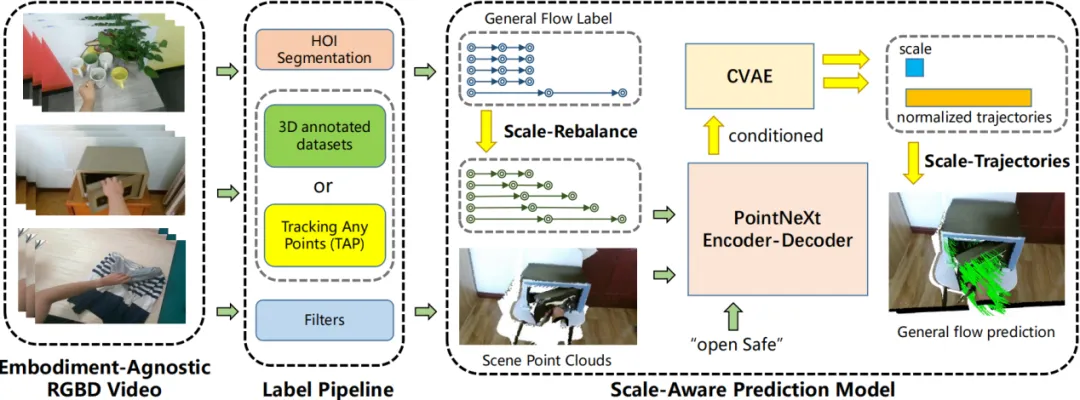
图9. 通用流表征预测模型训练框架
在不使用任何机器人数据的情况下,基于通用流表征预测的方法在6个训练时未见过的场景中的18个物体操作任务上取得了81%的成功率。值得注意的是,被操作物体涉及刚体、结构体和软体,展现了流表征方法的通用性。除此之外,流表征方法展现出了多种优良性质,包括对机器人分割的鲁棒性、对物体形状的泛化性,对抓取方法的普适性,以及对空间关系的感知性。总的来说,该工作为更大规模的从人类视频中学习机器人操作技能提供了新的方法。

图10. 通用流表征方法所展现出的优良性质
通用流表征方法探索了基于人类视频进行可扩展机器人学习的全新思路。本论文一作为清华大学硕士生袁承博,通讯作者为高阳助理教授。共同作者为上海期智研究院实习生、清华大学博士生汶川、张彤。
论文信息:
General Flow as Foundation Affordance for Scalable Robot Learning, Chengbo Yuan, Chuan Wen, Tong Zhang, Yang Gao†, https://general-flow.github.io/, CoRL 2024.
利用局部性提升机器人操作任务中的样本效率
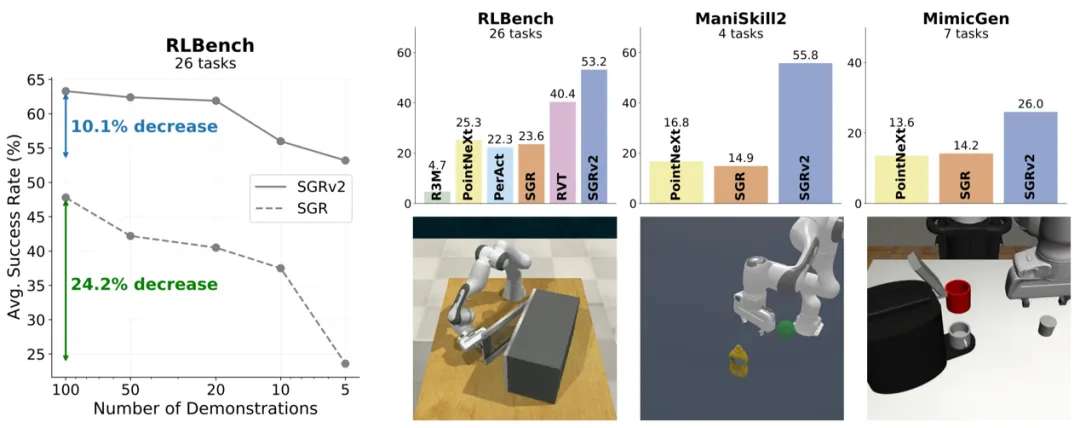
图11. SGRv2的样本效率及模拟结果概览
由于在真实世界中收集机器人数据需要很高的成本,样本效率始终是机器人研究中的一个关键问题。在机器学习领域,引入归纳偏置是提升样本效率的常用策略。在机器人操作中,一个关键的归纳偏置是动作局部性。动作局部性假设,机器人的动作主要由目标物体及其与周围局部环境的关系决定。然而,以往针对机器人操作的表征学习研究并未有效利用这一偏置。这些研究通常利用一个全局表征,以捕捉整个场景的信息,然后直接用于预测机器人的动作。然而,这些方法在样本效率上表现出明显的不足。例如SGR在将演示次数从100次减少到5次后,其成功率会显著降低。
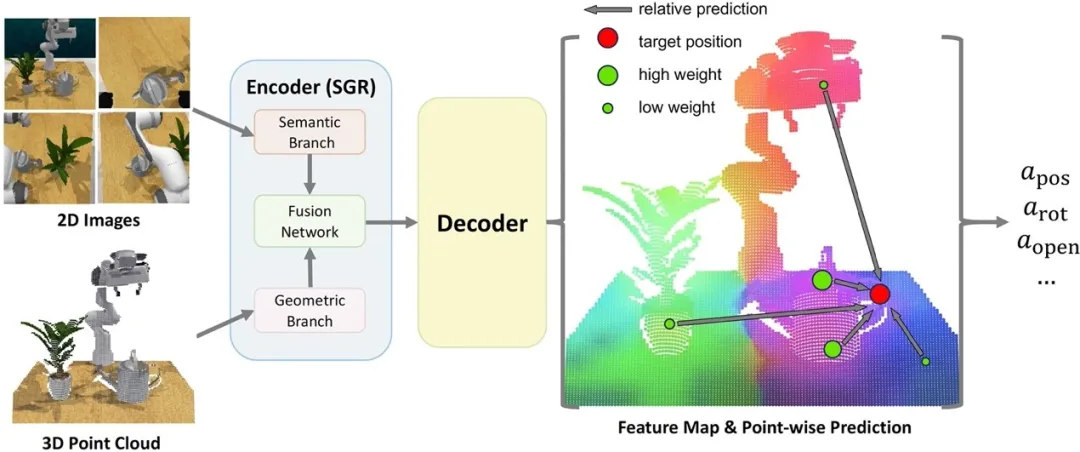
图12. SGRv2网络结构图
为有效利用动作局部性的归纳偏置,高阳团队提出了SGRv2 (Semantic-Geometric Representation v2),一个系统化的视觉动作策略框架。SGRv2以SGR为基础,但在整个框架中融入了动作局部性。SGRv2的核心算法设计包括:首先,与SGR使用的仅编码器架构不同,团队采用了PointNeXt的编码器-解码器架构,该架构可以为每个点生成富含全局和局部信息的特征。其次,基于逐点特征,为每个点预测相对目标位置。通过将相对预测与点自身的坐标相加,得到动作预测的绝对位置。对于其他动作组件,如旋转和夹爪开关状态等,则直接预测绝对值。第三,在获得逐点动作预测后,采用加权平均的方式将这些预测整合为最终的动作预测。最后,为了增强局部特征的学习效率,采用了密集监督策略。
SGRv2表现出卓越的样本效率,并在各种演示规模下始终优于之前的方法。SGRv2在仅使用5次演示时便能取得显著效果,其甚至超过SGR在100次演示下的效果。团队通过行为克隆在RLBench、ManiSkill2和MimicGen三个基准测试上对SGRv2进行了广泛的评估:SGRv2显著超越了SGR和PointNeXt,并且在RLBench任务中持续优于包括R3M、PerAct和RVT在内的基线模型。

图12. 真机实验任务
此外,通过使用Franka Emika Panda机器人进行的真实环境实验,SGRv2展示了其完成复杂长时间任务的能力,进一步验证了其有效性。
SGRv2该框架为提高机器人操作任务中的样本效率提供了新思路,并展现了局部性等归纳偏置在机器人任务上的广阔前景。本论文一作为上海期智研究院实习生、清华大学博士生张彤,通讯作者为高阳助理教授。共同作者为上海期智研究院实习生、清华大学博士生胡英东、游嘉诚。
论文信息:
Leveraging Locality to Boost Sample Efficiency in Robotic Manipulation, Tong Zhang, Yingdong Hu, Jiacheng You, Yang Gao†, https://sgrv2-robot.github.io/, CoRL 2024.







