上海期智研究院PI,清华大学交叉信息研究院助理教授。
博士毕业于美国加州大学伯克利分校,博后曾就职于美国斯坦福大学。研究聚焦具身人工智能的理论、算法与应用,具体方向包括深度强化学习与机器人学等。他曾荣获机器人顶级会议 CoRL'23 最佳系统论文奖,并在 IJRR、RSS、NeurIPS 等顶级期刊/会议上发表论文五十余篇,其代表性成果被 MIT Technology Review 等媒体广泛报道。他还担任IJCAI23'24'25, IJCAI'24'25, ICRA'24'25, and ICLR'25 等会议领域主席/副主编。
具身智能与机器人学:机器人泛化灵巧操作和控制
强化学习:可泛化和高效率的强化学习算法
模仿学习:高效可泛化的模仿学习算法
成果19:对于机器人学习的4D视觉预训练(2025年度)
许华哲团队提出的是一种面向真实世界机器人学习的新型四维视觉预训练框架(FVP)。近年来,从网络规模数据集中学习到的通用视觉表征在机器人领域取得了巨大成功,显著提升了机器人在操作任务中的数据利用效率。然而,这些预训练表征大多基于二维图像,忽视了现实世界固有的三维特性。由于大规模三维数据的稀缺,目前仍难以直接从网络数据中提取出通用的三维视觉表征。为此,我们致力于探索一种通用的视觉预训练框架,以作为提升各类三维表征能力的替代路径。我们提出的框架名为新型四维视觉预训练框架 FVP(Four-dimensional Visual Pre-training),FVP 将视觉预训练目标建模为“下一帧点云预测”问题,采用扩散模型作为预测模型,并直接在大规模公开数据集上进行预训练。在十二项真实世界操作任务上的实验表明,经过 FVP 预训练的 3D Diffusion Policy(DP3)平均成功率提升了 28%。FVP 预训练的 DP3 在模仿学习方法中达到了当前最先进的性能。此外,我们的方法在多种点云编码器和不同数据集上均展现出良好的适应性和有效性。最后,我们将 FVP 应用于更大的视觉-语言-动作机器人模型 RDT-1B,显著提升了其在多种机器人任务上的表现。
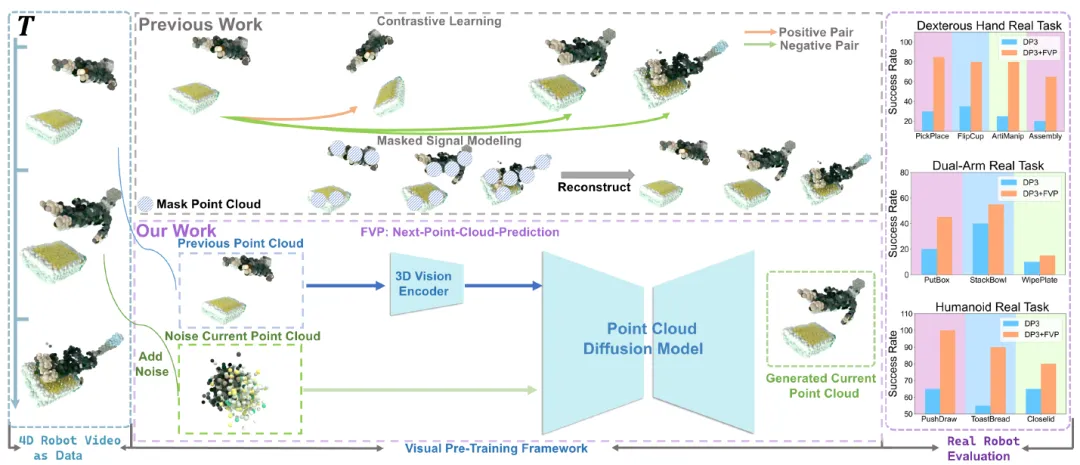
图. FVP: 一种新颖的用于机器人学习的预训练框架
论文信息:
https://arxiv.org/pdf/2508.17230
4D Visual Pre-training for Robot Learning, Chengkai Hou, Yanjie Ze, Yankai Fu, Zeyu Gao, Songbo Hu, Yue Yu, Shanghang Zhang, Huazhe Xu†,ICCV 2025.
------------------------------------------------------------------------------------------------------------------------------
成果18:DTactive:一种具有主动可活动表面的视触觉传感器(2025年度)
许华哲团队提出DTactive, 一种具有主动可活动表面的基于视觉的触觉传感器。该传感器在具有高分辨率触觉三维重建能力的同时,集成了赋予其表面移动性的机械传动机构。团队利用传感器提供的高分辨率触觉图像和传动机构的编码器数据,提出了一种融合神经网络与比例-微分控制的手中物体操作控制框架,以实现手中物体操作的精确角度轨迹控制。实验结果体现了DTactive在手内物体操作任务上的高效性、鲁棒性和精度方面的潜力。

图. 末端配备DTactive触觉技术的双指夹爪实现瓶盖翻转操作
论文信息:
https://arxiv.org/pdf/2409.19920
DTactive: A Vision-Based Tactile Sensor with Active Surface, Jikai Xu*, Lei Wu*, Changyi Lin, Ding Zhao, Huazhe Xu†,IROS 2025.
------------------------------------------------------------------------------------------------------------------------------
成果17:基于阻抗跟踪的足式机器人力适应控制(2025年度)
许华哲团队提出强化学习运动控制框架FACET。常见的强化学习运动控制策略以位置或速度跟踪为主要奖励函数进行训练,缺乏对受力情况的考虑,得到的控制策略无法控制刚度与柔顺度,受外力时可能表现出过度刚性或未定义的行为,不利于在复杂环境中安全运行。受阻抗/导纳控制启发,FACET将模拟质点-弹簧-阻尼系统作为训练目标,使得用户或高层策略可以调控机器人在任务空间的刚度与柔顺度。同时,通过设计时间平滑的奖励函数与教师-学生训练策略,无需准确感知外力与机器人本体的速度,大大降低了部署时的需求。最终得到的策略更安全可控。该框架也可直接推广到更复杂的机器人构型。
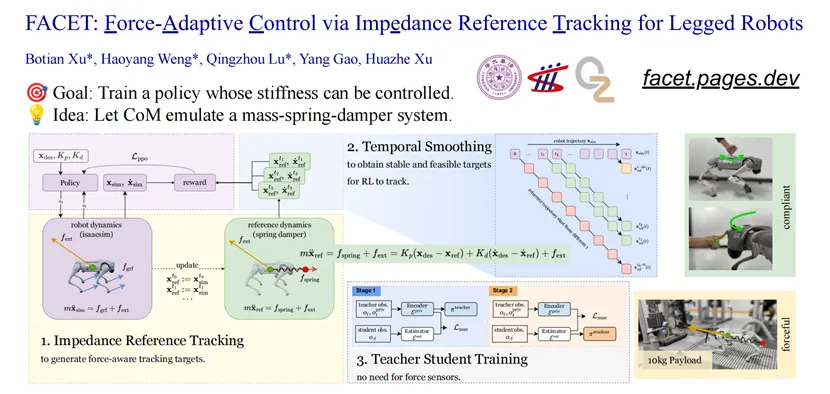
图. FACET框架
论文信息:
https://doi.org/10.48550/arXiv.2505.06883
FACET: Force-Adaptive Control via ImpedanceReference Tracking for Legged Robots, Botian Xu∗, HaoyangWeng∗, Qingzhou Lu∗, Yang Gao, Huazhe Xu†,CoRL 2025,Oral.
------------------------------------------------------------------------------------------------------------------------------
成果16:通过熵引导的演示数据加速以加快视觉运动策略—DemoSpeedup(2025年度)
许华哲团队提出DemoSpeedup:通过熵引导的演示加速方法来加速视觉运动策略执行。DemoSpeedup 从在源数据上训练任意生成策略(如扩散策略),将该策略对数据中的动作熵进行逐帧估计。较低的动作熵意味着策略的输出较为一致,这表明了当前帧对高精度动作的需求;相反,较高熵的帧对应更加随意的动作,对任务成功并不关键,因此可以更安全地加速。因此,DemoSpeedup根据估计的熵值对源演示数据进行分段,并在动作熵值引导下采样以不同比率加速数据。通过加速后的示范数据训练的策略,执行速度提升高达3倍,同时维持了与源数据上训练策略相当的成功率。

图. DemoSpeedup能够基于缓慢的演示数据提升视觉运动策略的执行速度
论文信息:
https://doi.org/10.48550/arXiv.2506.05064
DemoSpeedup: Accelerating Visuomotor Policies via Entropy-Guided Demonstration Acceleration, Lingxiao Guo, Zhengrong Xue, Zijing Xu, Huazhe Xu†,CoRL 2025,Oral.
------------------------------------------------------------------------------------------------------------------------------
成果15:深度强化学习连续控制中的遗忘-生长扩展策略(2025年度)
许华哲团队提出了一种深度强化学习连续控制中的遗忘-生长策略FoG。FoG通过回放缓冲区样本遗忘和评论家网络扩张,解决了当前强化学习算法过拟合回放缓冲区内早期数据的问题,显著提升了已有算法的数据效率。FoG在多个主流基准的超过40个环境测试中超过了多种主流基线算法。
论文信息:
https://openreview.net/pdf?id=VhmTXbsdtx
A Forget-and-Grow Strategy for Deep Reinforcement Learning Scaling in Continuous Control, Zilin Kang*, Chenyuan Hu*, Yu Luo, Zhecheng Yuan, Ruijie Zheng, Huazhe Xu†, ICML 2025
------------------------------------------------------------------------------------------------------------------------------
成果14:接住它!学习用灵巧手接住飞行的物体(2025年度)

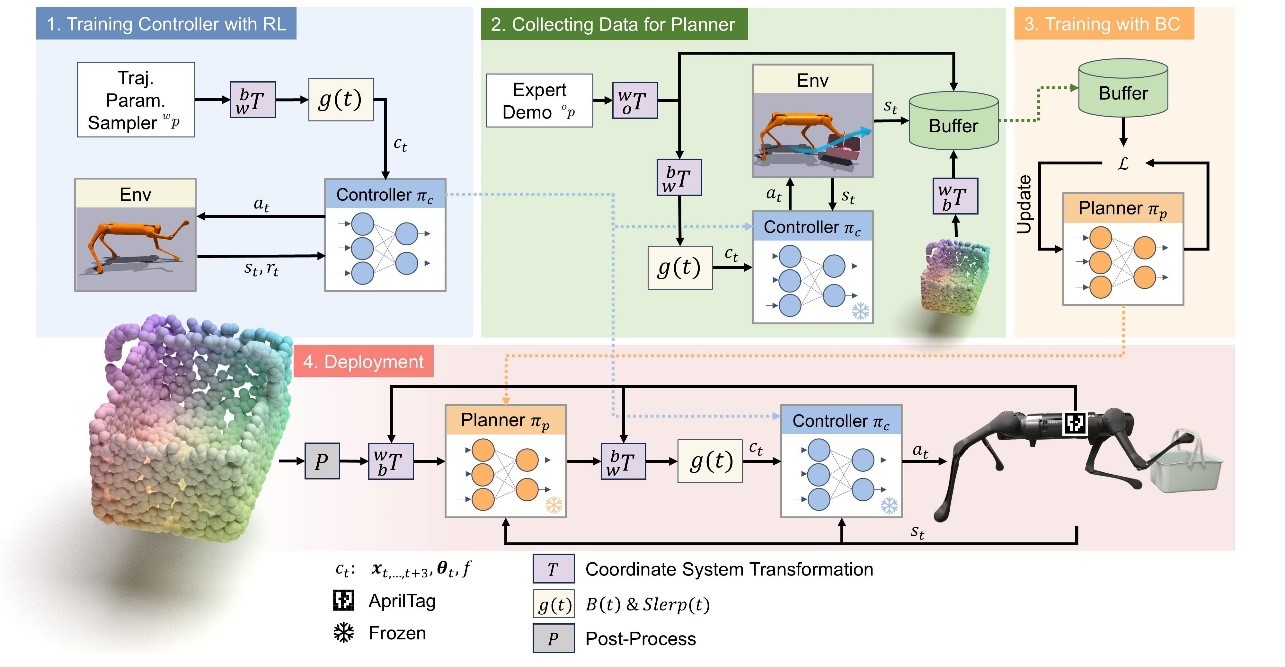
许华哲团队提出了一种集成移动平台、机械臂和灵巧手的高自由度操作系统—Catch It,实现了机器人对飞行物体的自主捕捉能力。该系统具备较大的工作空间与操作灵活性,并采用全身控制策略控制各组件协同完成任务,满足了飞行物体抓取对时效性、准确性和动作协调性的要求。该设计显著扩展了传统固定平台系统在动态操作任务中的适用范围。
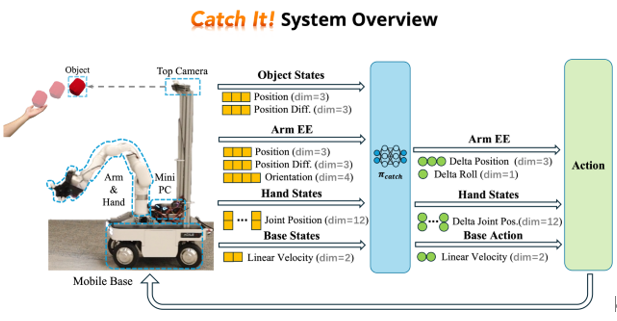
图13. 系统概览
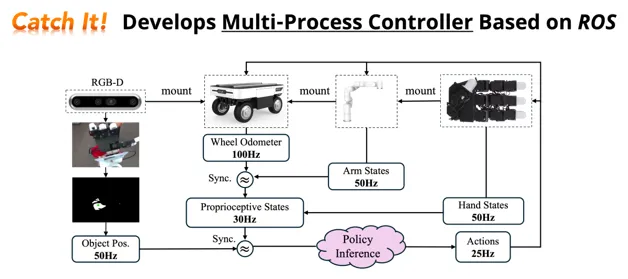
图. 多进程控制器
为了提高策略训练的效率和稳定性,“Catch It”提出了一种两阶段强化学习框架:(1) 跟踪阶段:训练底盘与机械臂以快速接近飞行物体;(2) 抓取阶段:加入灵巧手控制,并对已有策略进一步细化,以实现更可靠的抓取行为。该分阶段设计有效降低了策略搜索空间,提升了学习效率,避免了直接在高维动作空间中训练所带来的不稳定性。实验结果表明,在模拟环境中该方法可达到约80% 的物体抓取成功率,在任务完成能力和策略泛化能力方面均优于对比基线方法。
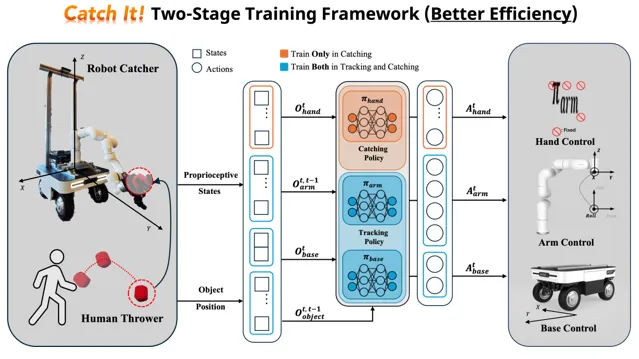
图. 两阶段强化学习框架
为增强策略在实际应用中的可行性,“Catch It”在训练过程中引入了物体属性、物理参数及感知误差的随机化机制,并结合控制信号的平滑处理(低通滤波),从而减小仿真与真实环境间的差异。
训练完成的策略无需额外的微调,可直接部署于真实机器人系统完成对多种形状沙袋的抓取操作。尽管在真实环境中由于物体弹性和感知不确定性,抓取成功率相对较低(最高约25%),但实验结果仍验证了该方法在实际动态操作任务中的一定适应能力和可部署性。

------------------------------------------------------------------------------------------------------------------------------
成果13:利用三维语义对应实现的基于单个示例的类别内泛化操作(2025年度)
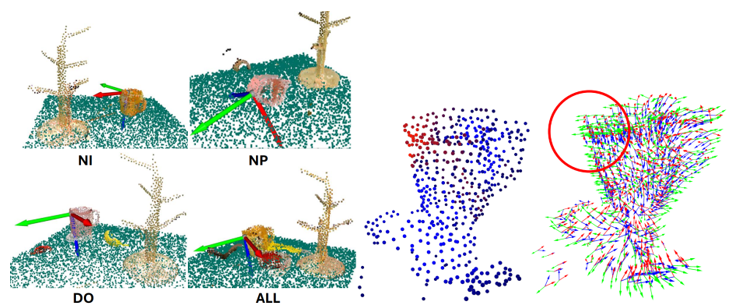
稠密的3D对应关系可以通过将一个物体的空间、功能和动态信息推广到未见过的新物体上,从而增强机器人操作能力。与形状对应相比,语义对应在跨不同物体类别的泛化方面更为有效。为此,团队提出了 DenseMatcher,一种能够计算具有相似结构的真实环境中物体之间3D对应关系的方法,旨在解决机器人仅通过单次演示学习在类别层面进行操作的泛化问题。
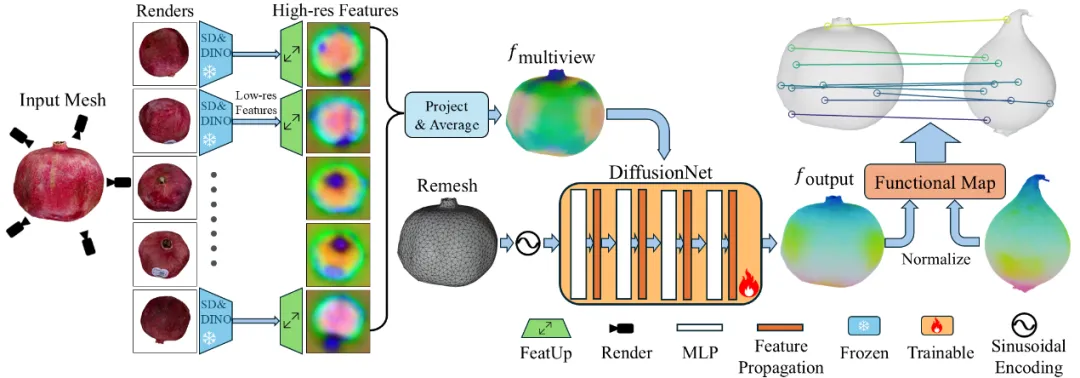
图. DenseMatcher模型架构
该方法的核心创新在于其两步流程:首先,通过将多视角的2D图像特征投影到3D物体网格上,并结合一个3D网络进行特征优化,从而计算出鲁棒的顶点特征;其次,利用这些特征,并通过功能图(functional map)技术来计算物体间的稠密对应关系。这种方法能够有效地在具有相似结构但分属不同类别的物体间建立语义层面的联系。此外,团队构建了首个包含不同类别彩色物体网格的3D匹配数据集。实验结果表明,DenseMatcher 的性能显著优于先前的3D匹配基线方法达43.5%。

图. (a) 三维物品间零样本色彩迁移。(b) 真机实验中,使用DenseMatcher将操作序列从单次人类示范迁移至机器人。

图. 6 种机器人任务的关键动作帧分解
------------------------------------------------------------------------------------------------------------------------------
成果12:借助逆扩散过程生成类干细胞观测助力可泛化的视觉模仿学习(2025年度)
模仿学习是机器人通过观察专家的示范行为学习执行任务的方法。其中,视觉模仿学习是一种利用高维视觉观察的方法,用于特定任务的状态估计。然而在面对视觉输入扰动时,如照明和纹理变化,视觉模仿学习仍存在泛化性不足的问题。
Stem-OB 通过使用预训练的图像扩散模型创建一种“干细胞状”的收敛观察,为视觉模仿学习引入了一种创新方法。该方法解决了视觉模仿学习在面对如光照和纹理变化的非特定视觉输入扰动时泛化能力差的关键问题。
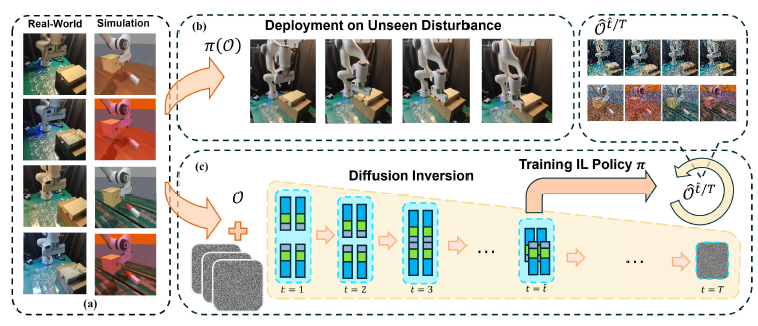
图. Stem-OB概览
其核心创新在于通过图像反演过程,在抑制低级视觉差异的同时保留高级场景结构的能力。这有效地将多样化的视觉输入转换为共享的、规范的表示,并剥离了无关的细节。与传统的数据增强技术不同,Stem-OB 无需额外训练即可对各种视觉变化保持鲁棒性,使其成为一种简单而高效的即插即用解决方案。
Stem-OB 的重要价值通过其经验结果得到了证明。它在模拟任务中显示出显著的有效性,并在实际应用中取得了非常显著的改进。具体而言,在真实世界场景中,与最佳基线方法相比,其成功率平均提高了22.2%。这突显了其在使视觉模仿学习在动态、真实的现实环境中更加可靠和适用方面的潜力。

图. Stem-OB反演树由通过扩散反演过程逐步倒置的不同物体构成。
------------------------------------------------------------------------------------------------------------------------------
成果11:智能体生成器:一种通过行为提示扩散生成通用策略网络的框架(2024年度)

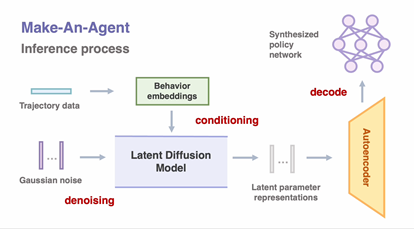
传统强化学习需要通过行为数据训练策略网络,而许华哲团队Make-An-Agent框架创新性地从离线的次优轨迹中逆向预测最优策略参数。该方法无需显式建模行为分布,直接学习参数空间的潜在分布,揭示任务行为与策略参数之间的隐含关系。通过扩散模型逐步优化噪声为结构化参数,团队实现了行为到策略的直接生成,生成的策略不仅性能优越,还具有更强的鲁棒性和高效性。
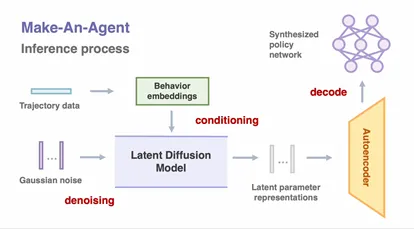
图1. 通过扩散模型生成策略参数,解决行为到策略生成问题
Make-An-Agent框架提出了三项关键技术创新:
(1) 使用自编码器压缩并重建策略网络的潜在表示,从而有效捕捉策略参数特征;
(2) 利用对比学习方法,捕获长期轨迹与未来成功状态间的互信息,生成高效的行为嵌入;
(3) 基于行为嵌入,使用条件扩散模型生成潜在的策略参数表示,并通过预训练解码器将其转化为可部署的策略。团队还构建了一个包含策略参数和轨迹数据的预训练数据集以支持模型训练。
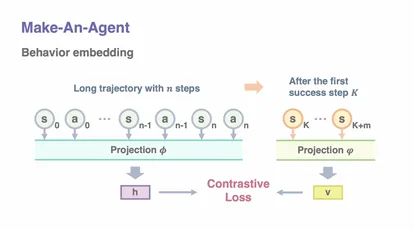
图2. 基于课程学习的数据增强与域随机化
在连续控制领域(包括复杂桌面操作和真实机器人运动任务)中,Make-An-Agent在测试阶段通过次优轨迹生成策略,展现出卓越的跨任务泛化能力。相比于多任务学习、元学习及基于超网络的方法,生成的策略在性能、鲁棒性和任务迁移能力上均表现最佳。尤其在嘈杂轨迹输入下,框架仍可生成高性能策略,验证了其对环境随机性的强鲁棒性。这种能力使其成为具备广泛应用潜力的端到端行为到策略生成工具。


图3. MetaWorld、Robosuite和真实四足运动的可视化
该工作提出的Make-An-Agent对多任务和真实世界机器人应用具有重要意义。
论文信息:Make-An-Agent: A Generalizable Policy NetworkGenerator with Behavior Prompted Diffusion, Yongyuan Liang, Tingqiang Xu, Kaizhe Hu, Guangqi Jiang, Furong Huang, Huazhe Xu†, https://cheryyunl.github.io/make-an-agent/, NeurIPS 2024.
------------------------------------------------------------------------------------------------------------------------------
成果10:学习在任何地点操作:一种视觉泛化强化学习框架(2024年度)
如何让智能体具备在多个视角下进行操作的能力是机器人走向落地的关键。许华哲团队设计了在层之间的一个multi-view的表征学习目标函数,去捕捉不同视角下的correspondence和alignment。同时也去插入STN模块,并把affine transformation改成了perspective transformation的形式,辅助网络更好的理解不同视角下的图像。利用该种方式将同一时刻不同视角的表征都投影到特征空间的相似位置。

图1. Maniwhere框架能够训练出能够跨各种视觉变化有效泛化的视动机器人
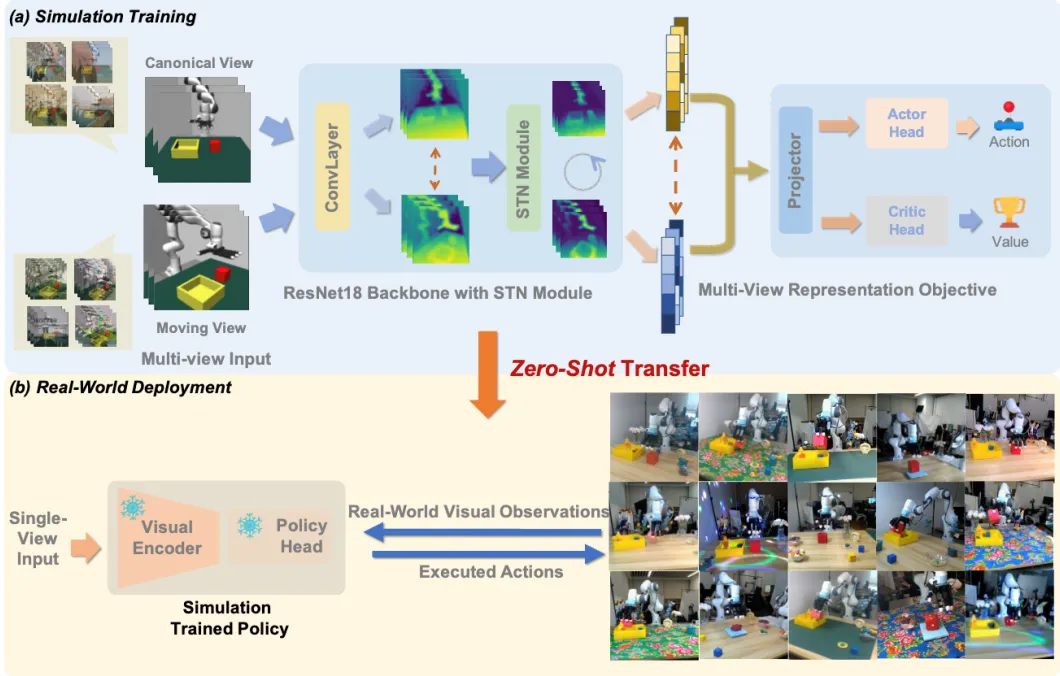
图2. Maniwhere概览
在具备了视角泛化能力后,团队又设计了一种可泛化框架可以将多种视觉泛化的先验知识融入到智能体中。团队使用基于课程学习的数据增强与域随机化方法,将纹理,具身形态等多种其他视觉泛化类型也融入到网络中。同时利用该种方式也可以更好的扩展训练数据的分布,以便于从模拟仿真器至现实环境的迁移。
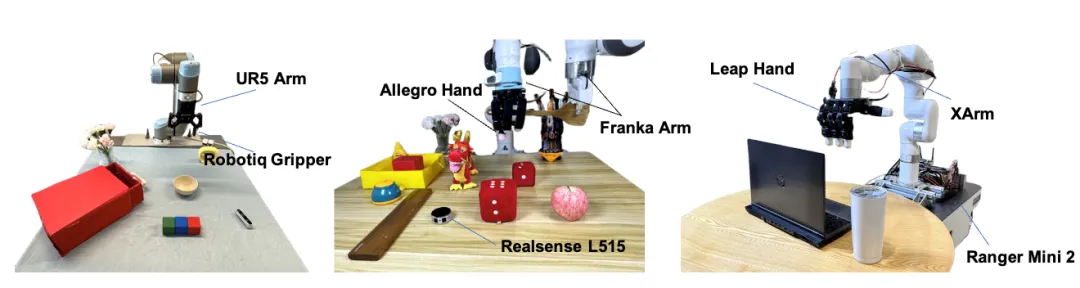
图3. 真机实验设置
为了验证方法的有效性,团队设计了8种任务,在3个硬件平台上执行了sim2real的实验。结果表明,该方法效果在所有的任务上都取得了最佳的泛化表现。
论文信息:Learning to Manipulate Anywhere: A Visual Generalizable Framework For Reinforcement Learning, Zhecheng Yuan*, Tianming Wei*, Shuiqi Cheng, Gu Zhang, Yuanpei Chen, Huazhe Xu†, https://gemcollector.github.io/maniwhere/, CoRL 2024.
------------------------------------------------------------------------------------------------------------------------------
成果9:从示范中学习实现四足机器人移动操纵(2024年度)

四足机器人的移动能力近年来得到不断的提升,但在四足机器人技术中,同时实现移动与多任务的操控一直是一个巨大的挑战。传统方法依赖于机械臂来实现复杂的操控任务,这不仅增加了系统的复杂性,而且限制了机器人的运动能力。
针对这一问题,许华哲团队提出了一个创新的分层学习框架,结合高层的视觉行为克隆规划器和低层的动态控制强化学习控制器,实现了四足机器人通过腿部执行复杂操控任务的能力。这种方法同时发挥了强化学习对高动态系统控制的优势,以及行为克隆对多任务学习的优势。
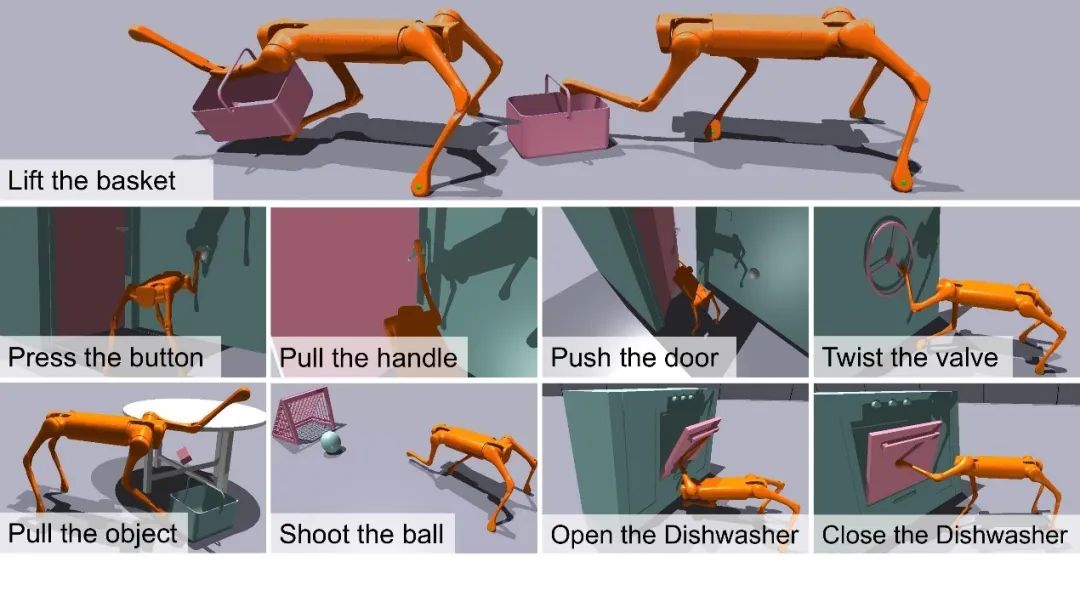
图1. 训练机器人完成的9个运动操作任务概述
同时,模仿学习的算法通常需要大量的数据收集和测试,这在真实环境中执行时成本高昂且效率低下。为了解决这一问题,我们的团队在仿真环境中通过大规模并行仿真采集数据,通过模拟复杂的操纵任务来生成大量的训练数据。利用这些数据,我们训练了能够精确规划和执行复杂移动操纵任务的模型。然后,通过简单的后处理,我们将现实和仿真中的点云进行对齐,实现了仿真到现实的迁移。
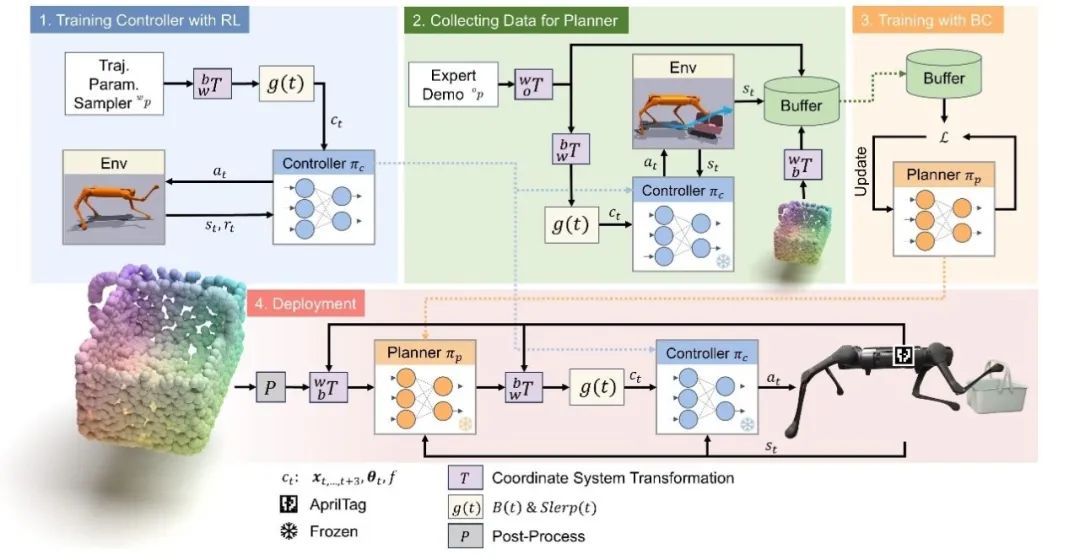
图2. 分层学习框架示意图
为了验证团队提出的框架有效性,团队根据足式操纵器的运用场景和实际需求,设计了9个不同的任务,包括提篮子、踢足球、推门等,并在Isaac Gym仿真器钟进行了实验。结果表明,许华哲团队的方法效果在所有任务上都优于3个基线。
本研究有潜力加速足式机器人多任务操作技能的发展。
论文信息:Learning Visual Quadrupedal Loco-Manipulation from Demonstrations, Zhengmao He, Kun Lei, Yanjie Ze, Koushil Sreenath, Zhongyu Li, Huazhe Xu†, https://zhengmaohe.github.io/leg-manip, IROS 2024.
------------------------------------------------------------------------------------------------------------------------------
成果8:Robo-ABC: 通过语义对应实现跨类别的可供性泛化,用于机器人操控(2024年度)
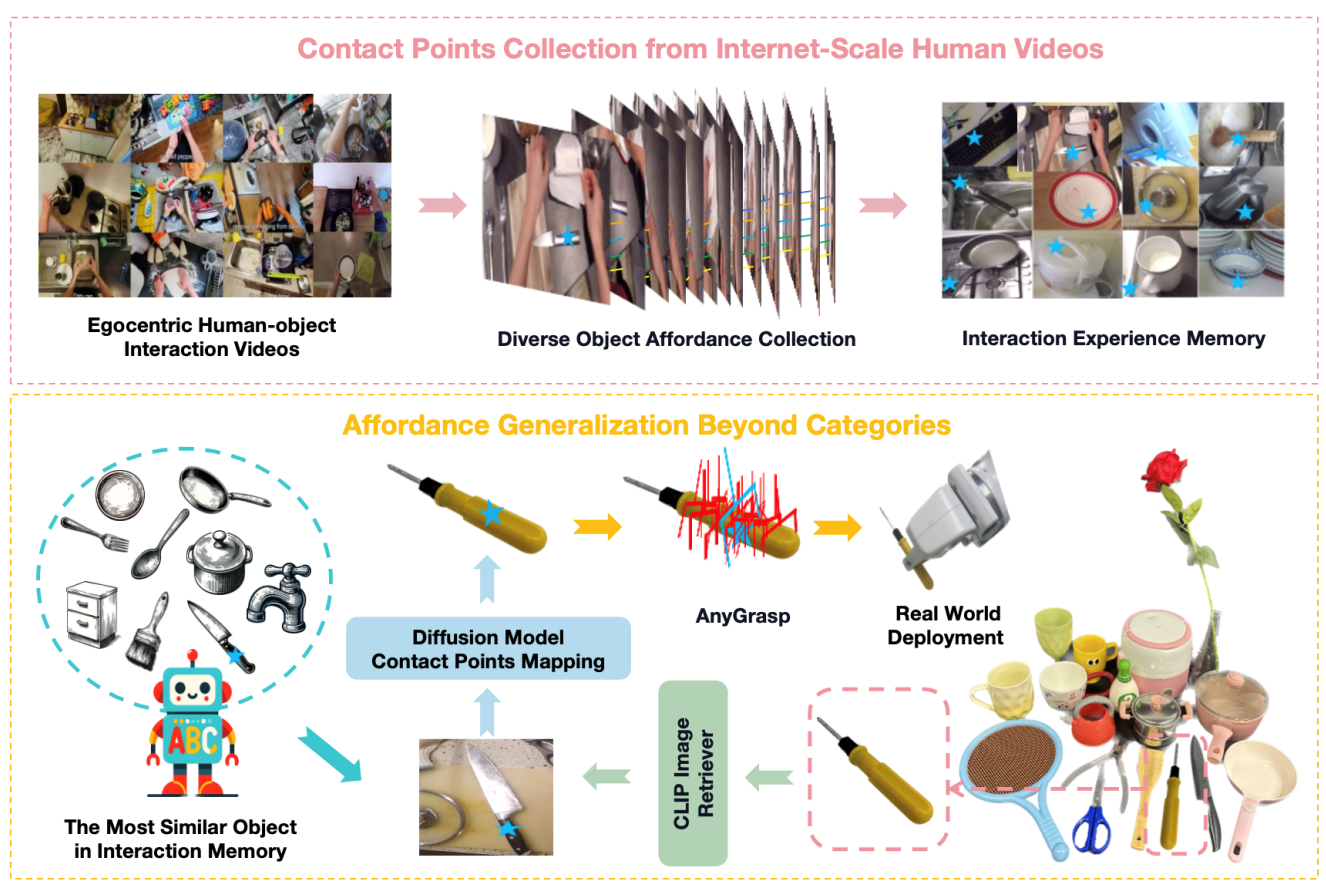
Robo-ABC 是一种新的机器人操控框架,旨在使机器人能够泛化地理解和操作在训练时未见过的类别的物体。该框架的核心思想是利用人类视频中的交互经验,通过语义对应(semantic correspondence)来帮助机器人在面对新物体时,能够通过检索与已知物体在视觉或语义上相似的物体,来推断新物体的可供性(即物体可被如何操作的特性)。团队首先从人类与物体互动的视频中提取可供性信息,并将这些信息存储在可供性记忆中。当机器人面对一个新物体时,它会从记忆中检索与新物体在视觉和语义上相似的物体。然后,利用扩散模型的语义对应能力,将检索到的物体的接触点映射到新物体上。这个过程使得机器人能够在没有手动标注、额外训练、部件分割、预编码知识或视角限制的情况下,零样本地泛化到跨类别物体的操控。

图1. Robo-ABC流程图
团队发现了Robo-ABC在泛化性上有优异的性能。在真实世界实验中,Robo-ABC在跨类别物体抓取任务中达到85.7%的成功率,显著提高了机器人在开放世界中处理新视图和跨类别设置的抓取准确性。
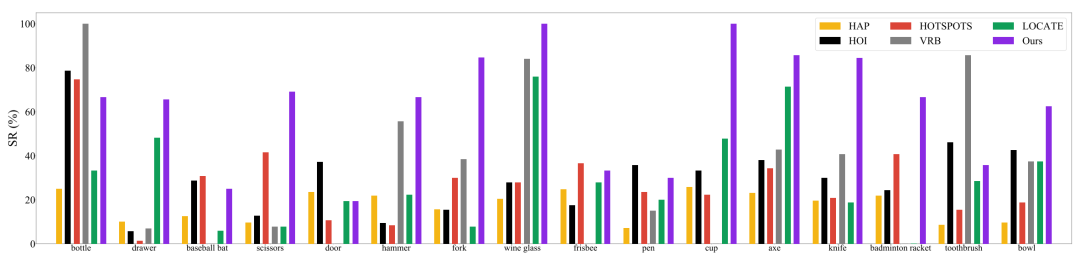
图2. Robo-ABC的优异性能

图3. Robo-ABC可泛化至多种不同类型的物体
该研究解决了机器人在面对新类别物体时如何有效抓取的挑战,对推动机器人在非结构化环境中的自主操作具有重要价值。
论文信息:Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation, Yuanchen Ju*, Kaizhe Hu*, Guowei Zhang, Gu Zhang, Mingrun Jiang, Huazhe Xu†, ECCV 2024.
------------------------------------------------------------------------------------------------------------------------------
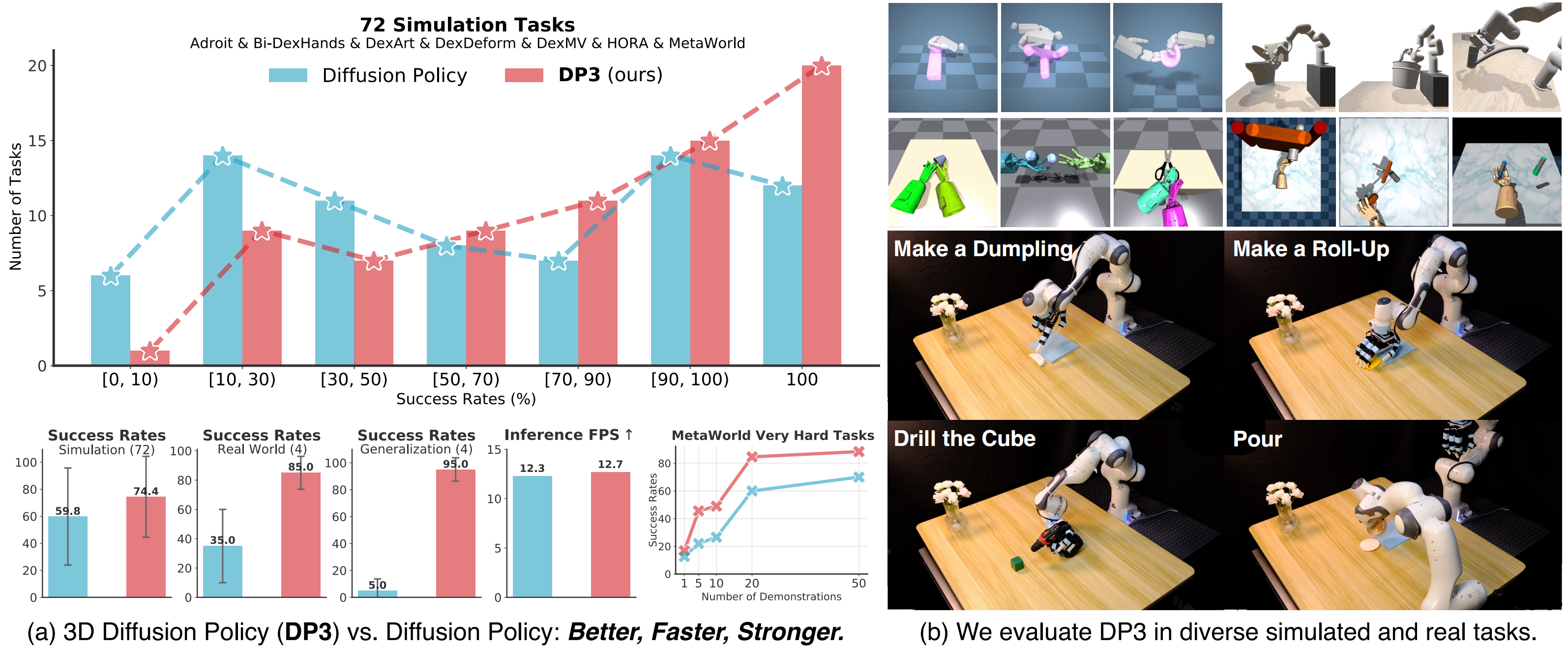
成果7:新型视觉模仿学习算法:3D扩散策略(DP3)(2024年度)

3D 扩散策略(DP3)是一种专为提高机器人的模仿学习效率和泛化能力设计的新型模仿学习算法。DP3 通过融合简洁高效的 3D 视觉表征和扩散模型来实现对复杂机器人操作的学习和执行。DP3 在处理稀疏点云数据时采用了高效的点云编码器来提取紧凑的 3D 视觉表征,并在此基础上从随机噪声中降噪得到连贯的动作序列。通过在仿真和真实物理数据环境中的广泛测试,DP3 展示了其在少量专家演示数据下快速学习并成功处理多项任务的能力,显著优于当前的SOTA方法。

图1:3D扩散策略(DP3)的方法流程,分为感知和决策2个环节
在仿真环境中,DP3 被应用于 72 个不同的任务,覆盖从简单的物体操作到复杂的双手协调等多种机器人技能。实验结果显示,DP3仅通过10条演示数便可以成功执行大多数操作任务,并且相对于当前SOTA模型有24.2%的性能相对提升。同时,在真实机器人实验中,DP3 在四个不同的任务上进行了测试,这些任务涉及精细的物体操控和动态交互。DP3 展示了其在实际应用中的高度可行性和效率,依赖其稳定的 3D 视觉表征和动作生成策略,可以实现高达 85% 的成功率。
DP3 在多个方面显示出优异的泛化能力,包括空间泛化、外观泛化、实例泛化和视角泛化,如下方视频展示。这一广泛的泛化能力证明了 DP3 在真实世界应用中的潜力,尤其是在面对环境变化和新任务时。DP3为教授机器人掌握鲁棒且泛化的灵巧技能提供了有效方法,并大大提高了学习效率。
------------------------------------------------------------------------------------------------------------------------------
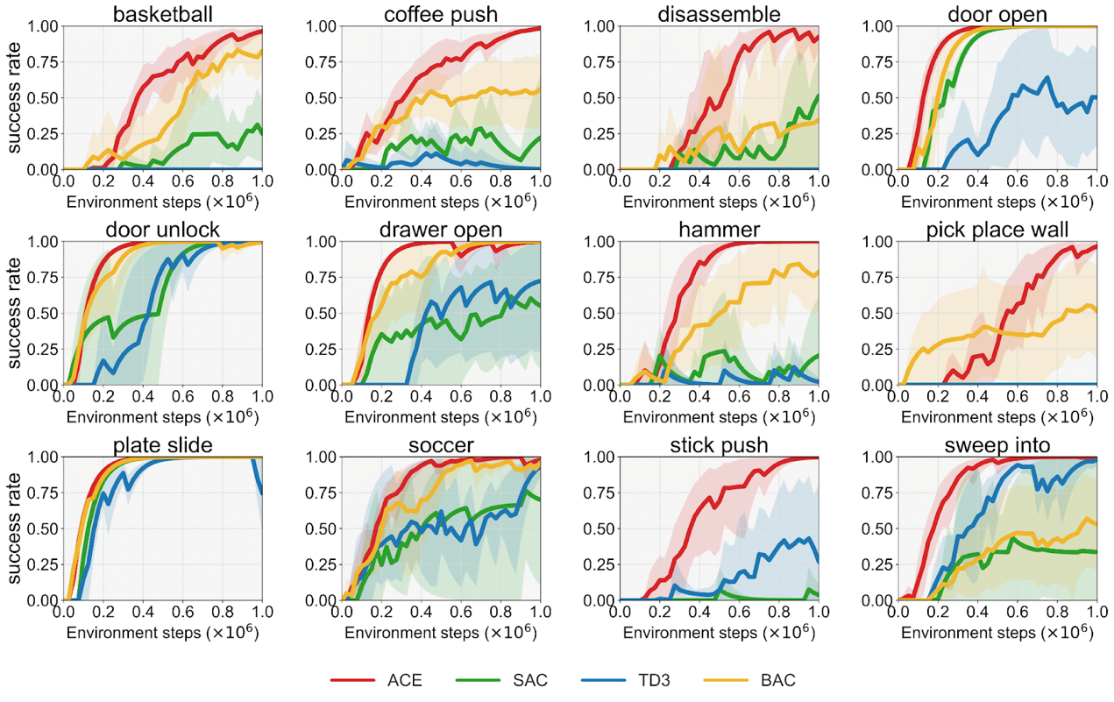
成果6:ACE: 具有因果感知能力的熵正则化离线策略演员-评论家算法(2024年度)
以往的强化学习算法忽略了不同原始行为在策略学习过程中的重要性变化。许华哲团队探索了不同动作维度与奖励之间的因果关系,以评估各种原始行为在训练过程中的重要性。我们提出的具有因果感知能力的熵正则化离线策略演员-评论家算法ACE (Off-policy Actor-critic with Causality-aware Entropy regularization),通过因果感知熵正则化进一步提高了强化学习的效率和效果。

图1. ACE的原始策略概念展示与效果
团队首次探索了动作维度与奖励之间的因果关系,评估不同原始行为在训练过程中的重要性,从而评估训练过程中各种行为的重要性。引入了一种因果感知熵项 (causality-aware entropy term),有效识别并优先探索具有高潜在影响的动作,有效解决了现有强化学习算法存在的探索效率和样本效率问题。分析了梯度休眠现象,并引入了一种休眠引导重置机制,防止过度关注特定原始行为,提升算法鲁棒性。

图2. ACE的优异性能
团队在7个领域的29个不同连续控制任务上,相较于其他强化学习基准算法表现出显著的性能优势,验证了方法的有效性、通用性和更高的采样效率。

图3. 激励性示例—机械臂将螺丝钉锤入墙壁
ACE算法将因果关系分析引入强化学习算法设计,为解决复杂决策问题提供了新的思路,具有重要的理论和实践价值。
论文信息:ACE: Off-Policy Actor-Critic with Causality-Aware Entropy Regularization, Tianying Ji*, Yongyuan Liang*, Yan Zeng, Yu Luo, Guowei Xu, Jiawei Guo, Ruijie Zheng, Furong Huang, Fuchun Sun, Huazhe Xu, https://arxiv.org/pdf/2402.14528, Oral, ICML 2024.
---------------------------------------------------------------------------------------------------------------------------
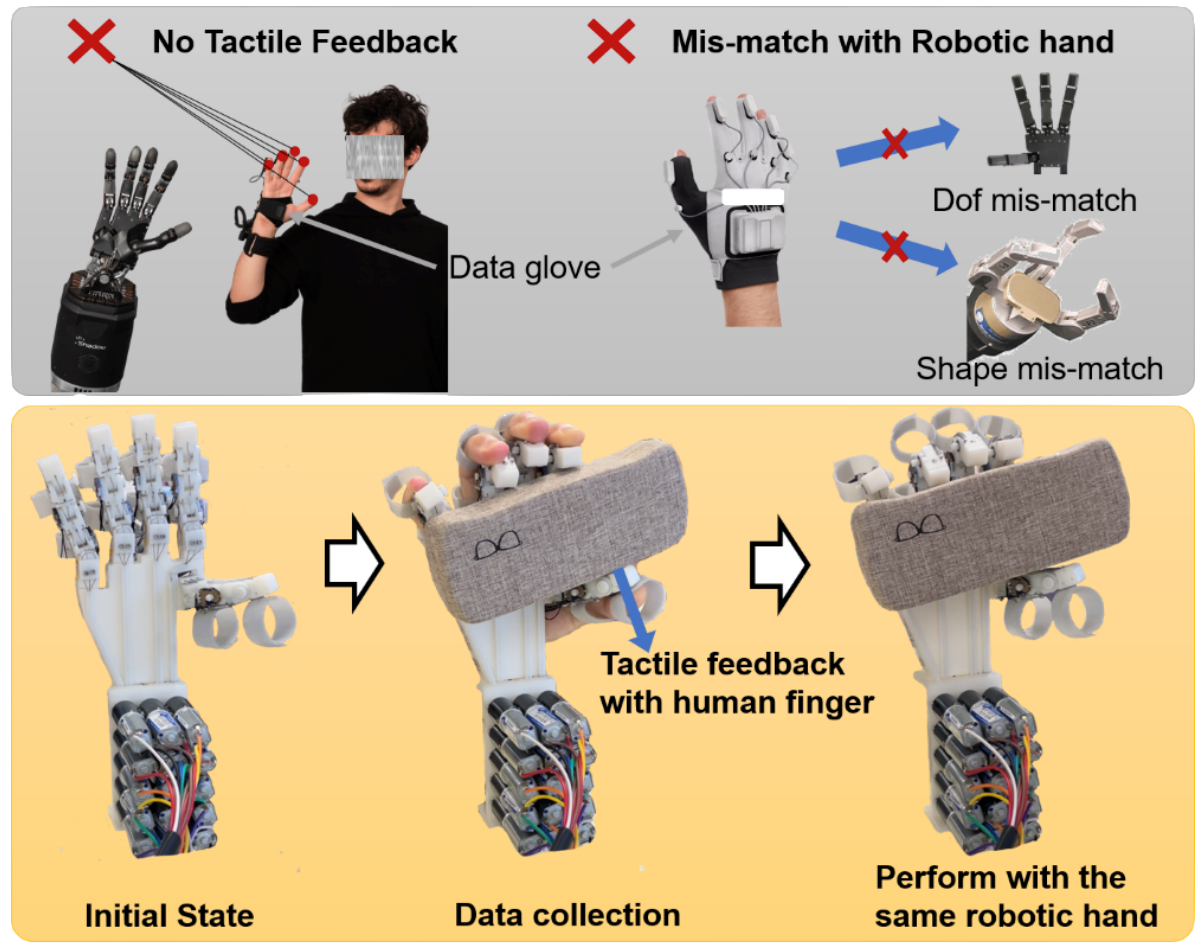
成果5:用于可泛化操作的阵列式机器人&可穿戴机械手 —ArrayBot & HIRO Hand(2024年度)
运用强化学习算法实现通用分布式操作的系统ArrayBot,通过触觉传感器进行操作学习,可用于真实世界的多种操作任务,展示了在模拟环境训练后无需领域随机化即可迁移至真实机器人的能力。提出了一种新型的手对手模仿学习可穿戴灵巧手HIRO Hand,它结合了专家数据收集和灵巧操作的实现,使操作者能够利用自己的触觉反馈来确定适当的力量、位置和动作,以执行更复杂的任务。

论文题目:ArrayBot: Reinforcement Learning for Generalizable Distributed Manipulation through Touch,Zhengrong Xue*, Han Zhang*, Jingwen Cheng, Zhengmao He, Yuanchen Ju, Changyi Lin, Gu Zhang, Huazhe Xu,https://steven-xzr.github.io/ArrayBot/
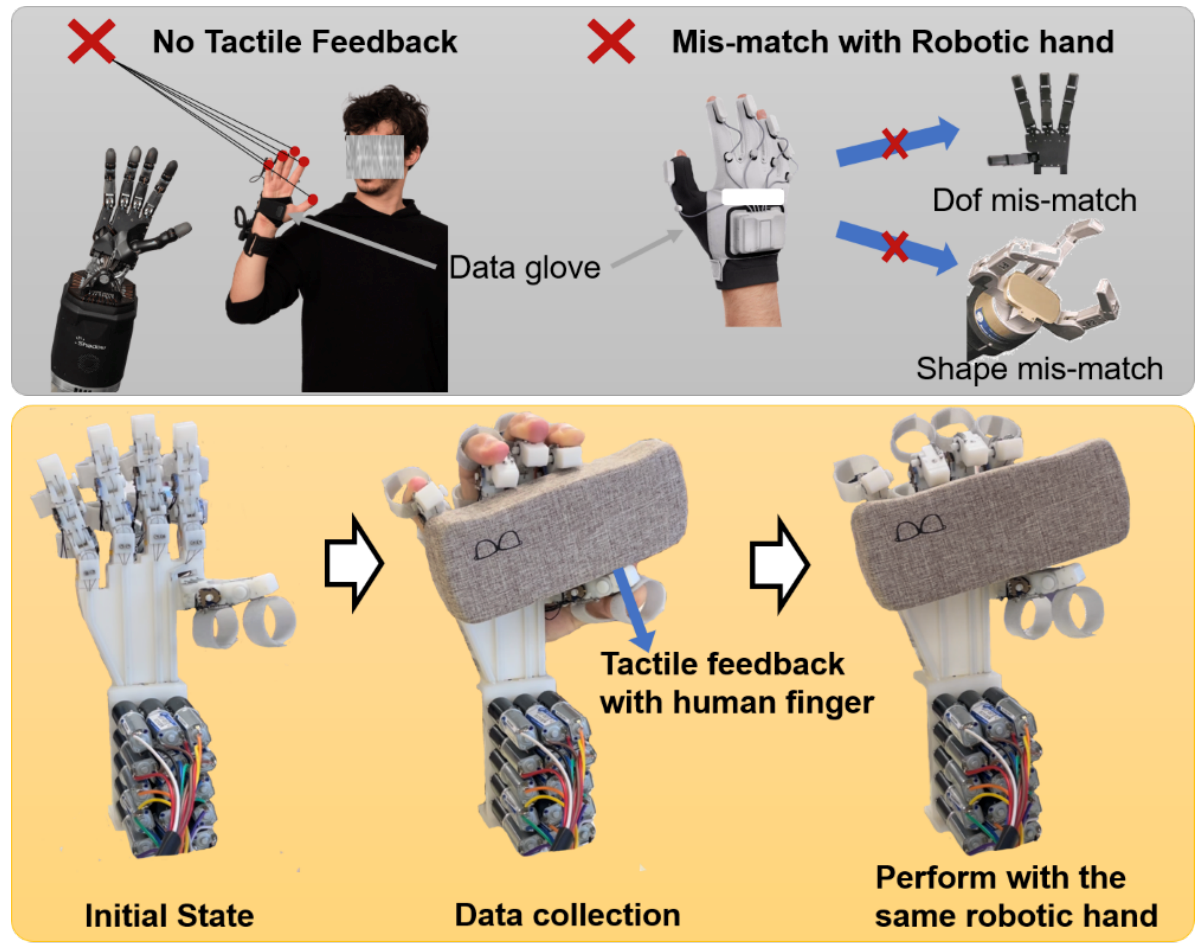
论文信息:A Wearable Robotic Hand for Hand-over-Hand Imitation Learning,Dehao Wei, Huazhe Xu,https://sites.google.com/view/hiro-hand
------------------------------------------------------------------------------------------------------------------------------
成果4:大模型生成具身智能仿真(2023年度)
使用大语言模型生成仿真环境是一种技术,它可以帮助模拟虚拟世界和场景,以便进行各种实验、测试和训练。本文利用大语言模型可以产生详细的场景描述,包括物体的位置、形状等信息。模型可以生成逼真的描述,使得仿真环境更加真实和可信。大语言模型可以结合物理引擎,生成仿真环境中的物理行为。例如,模型可以生成物体的运动、碰撞、重力效应等,以及其他复杂的物理行为。大语言模型可以生成智能体的行为策略和决策。这些智能体可以根据环境中的情况进行学习和优化,以实现特定的目标或任务。

研究领域:具身智能、机器人操作
项目网站:https://liruiw.github.io/gensim/
研究论文:Lirui Wang, Yiyang Ling*, Zhecheng Yuan*, Mohit Shridhar, Chen Bao, Yuzhe Qin, Bailin Wang, Huazhe Xu, Xiaolong Wang ‘GenSim: Generating Robotic Simulation Tasks via Large Language Models’. In CoRL workshop (best paper), 2023. 查看PDF
------------------------------------------------------------------------------------------------------------------------------
成果3:可泛化机器人操作和强化学习(2023年度)
机器人操作是具身人工智能中的重要任务。但传统的机器人任务往往缺乏泛化性,难以在开放世界中应用。许华哲团队提出基于三维视觉的机器人泛化操作算法USEEK和基于预训练模型的强化学习泛化算法PIE-G,可以在多样的环境和物理实体机器人上,取得强大的泛化性能。团队主要考虑了在机器人问题中的旋转等变性和和视觉多样性等挑战和特性,提出了系统化解决方法。提出了在视觉端自动无监督地学习旋转等变的关键点,在控制端采用大规模数据集预训练策略模型,最终可以达到类内物体的泛化,并且在视觉大幅变化的环境达到了世界最佳的强化学习泛化能力。算法解决了机器人操作和强化学习领域的重大基础科学问题,填补了国际可泛化强化学习领域的空白,为强化学习和机器人学习算法在开放物理世界落地铺平了道路。
与此同时,团队搭建了触觉传感器DTact, 从而使机器人可以获取多模态输入。在触觉的加持下,机器人操作可以进行更精细、更准确、更可靠,同时加泛化能力。

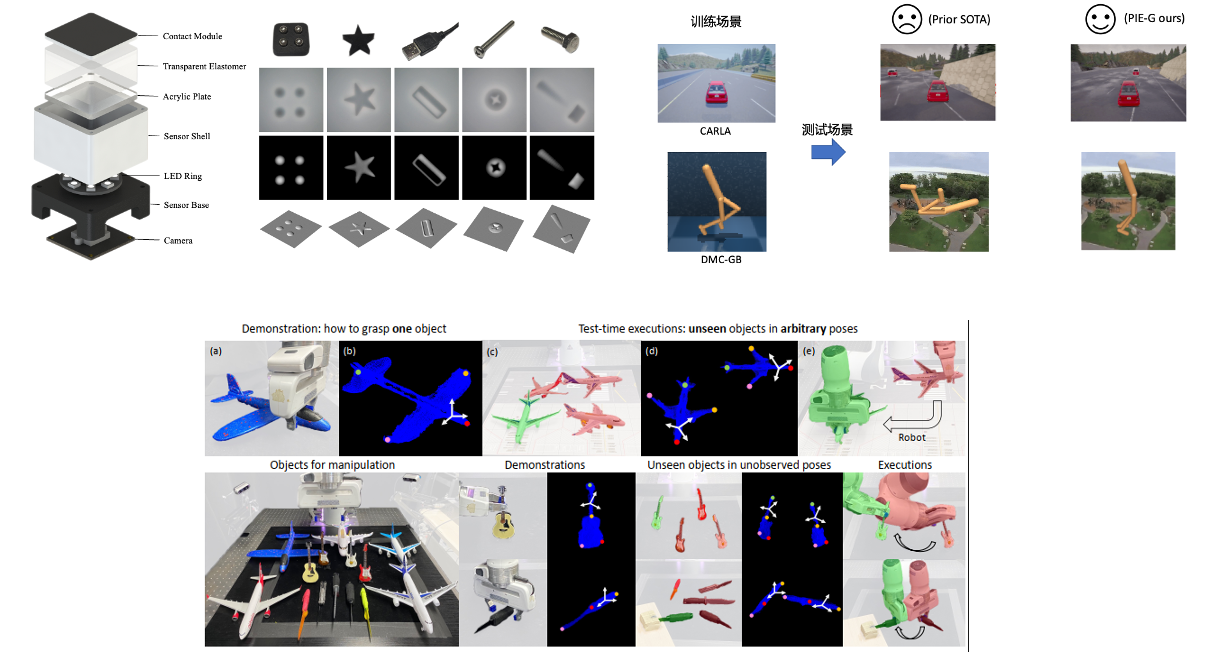
------------------------------------------------------------------------------------------------------------------------------
成果2:视觉强化学习泛化性基准平台(2023年度)
如何让我们训练得到的模型能够应用于广泛的任务环境中是深度学习中的核心问题。近年来视觉强化学习已经取得了瞩目的成绩, 有越来越多的技术已用来解决图像输入时带来的高维度和冗余信息多等问题。但是也有研究表明,训练得到的智能体易过拟合于环境。如何让智能体拥有更强的泛化能力也值得研究者去关注与思考。为了实现这一目标,本文提出了一种新型视觉强化学习基准泛化测试框架,致力于提高智能体的泛化能力,同时解决当前基准测试中存在的诸多不足。该框架具有以下特点:
(1) 多样化的任务环境:本文所提出的基准测试包含了各种不同类型的任务,例如导航、自动驾驶、抓取、控制等,以便更全面地评估智能体在不同场景下的泛化能力。
(2) 高度现实世界仿真:本文的基准测试环境采用了高度现实的物理和视觉仿真引擎和环境,以便更接近现实世界的情境,从而提高算法在实际应用中的表现的潜力。
(3) 连续和高维度动作空间:本文的基准测试支持连续和高维度的动作空间,以便更好地评估算法在复杂动作控制任务中的性能。
(4) 新的评估指标:本文引入了新的评估指标,以更全面地评估算法的泛化性能。

研究领域:视觉强化学习泛化基准平台
项目网站:https://gemcollector.github.io/RL-ViGen/
研究论文:Zhecheng Yuan*, Sizhe Yang*, Pu Hua, Can Chang, Kaizhe Hu, Xiaolong Wang, Huazhe Xu. ‘RL-ViGen: A Reinforcement Learning Benchmark for Visual Generalization’. In NeurIPS, 2023.
------------------------------------------------------------------------------------------------------------------------------
成果1:无标记物可力感知的视触觉传感器9DTact(2023年度)
9DTact是一种触觉传感器技术,它具有两个关键特点:
1凝胶感知:9DTact传感器的主要特点是其凝胶表面。该表面由一个透明的弹性凝胶材料覆盖,类似于人类的皮肤。凝胶表面可以通过接触物体来感知微小的形状和纹理信息,并以高分辨率记录这些信息。当传感器与物体接触时,凝胶会略微变形,这种变形的形状变化可以被传感器中的摄像机系统捕捉到。
2视觉反馈:9DTact传感器结合了视觉反馈和触觉感知。传感器内部包含一个内置的摄像机系统,用于记录凝胶表面的形变情况。摄像机可以捕捉到物体在凝胶表面上产生的形状变化,并将其转化为数字图像。通过分析这些图像,可以获取关于物体形状、纹理和表面细节的信息。
与已有方案相比,9DTact无需任何标记物可以同时感知纹理和力觉。

研究领域:具身智能、机器人触觉
项目网站:https://linchangyi1.github.io/9DTact/
研究论文:Changyi Lin, Han Zhang, Jikai Xu, Lei Wu, Huazhe Xu, ‘9DTact: A Compact Vision-Based Tactile Sensor for Accurate 3D Shape Reconstruction and Generalizable 6D Force Estimation’. In RAL, 2023. 查看PDF

许华哲 成果收录于NeurIPS 2024
许华哲 成果收录于CoRL 2024
许华哲 成果收录于IROS 2024
许华哲 成果收录于ECCV 2024
许华哲 成果收录于RSS 2024
许华哲 成果收录于ICML 2024
许华哲 成果收录于ICRA 2024

许华哲 成果收录于ICLR 2024



42. A Forget-and-Grow Strategy for Deep Reinforcement Learning Scaling in Continuous Control, Zilin Kang*, Chenyuan Hu*, Yu Luo, Zhecheng Yuan, Ruijie Zheng, Huazhe Xu†, ICML 2025
41. DemoSpeedup: Accelerating Visuomotor Policies via Entropy-Guided Demonstration Acceleration, Lingxiao Guo, Zhengrong Xue, Zijing Xu, Huazhe Xu†,CoRL 2025,Oral.
40. FACET: Force-Adaptive Control via ImpedanceReference Tracking for Legged Robots, Botian Xu∗, HaoyangWeng∗, Qingzhou Lu∗, Yang Gao, Huazhe Xu†,CoRL 2025,Oral.
39. DTactive: A Vision-Based Tactile Sensor with Active Surface, Jikai Xu*, Lei Wu*, Changyi Lin, Ding Zhao, Huazhe Xu†,IROS 2025.
38. 4D Visual Pre-training for Robot Learning, Chengkai Hou, Yanjie Ze, Yankai Fu, Zeyu Gao, Songbo Hu, Yue Yu, Shanghang Zhang, Huazhe Xu†,ICCV 2025.
37. Key-Grid: Unsupervised 3D Keypoints Detection using Grid Heatmap Features, Chengkai Hou, Zhengrong Xue, Bingyang Zhou, Jinghan Ke, Shao Lin, Huazhe Xu†, https://jackhck.github.io/keygrid.github.io/, NeurIPS 2024.
36. Make-An-Agent: A Generalizable Policy NetworkGenerator with Behavior Prompted Diffusion, Yongyuan Liang, Tingqiang Xu, Kaizhe Hu, Guangqi Jiang, Furong Huang, Huazhe Xu†, https://cheryyunl.github.io/make-an-agent/, NeurIPS 2024.
35. RiEMann: Near Real-Time SE(3)-Equivariant Robot Manipulation without Point Cloud Segmentation, Chongkai Gao, Zhengrong Xue, Shuying Deng, Tianhai Liang, Siqi Yang, Lin Shao, Huazhe Xu†, https://riemann-web.github.io/, CoRL 2024.
34. Learning to Manipulate Anywhere: A Visual Generalizable Framework For Reinforcement Learning, Zhecheng Yuan*, Tianming Wei*, Shuiqi Cheng, Gu Zhang, Yuanpei Chen, Huazhe Xu†, https://gemcollector.github.io/maniwhere/, CoRL 2024.
33. Learning Visual Quadrupedal Loco-Manipulation from Demonstrations, Zhengmao He, Kun Lei, Yanjie Ze, Koushil Sreenath, Zhongyu Li, Huazhe Xu†, https://zhengmaohe.github.io/leg-manip, IROS 2024.
32. Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation, Yuanchen Ju*, Kaizhe Hu*, Guowei Zhang, Gu Zhang, Mingrun Jiang, Huazhe Xu†, ECCV 2024.
31. Diffusion Reward: Learning Rewards via Conditional Video Diffusion, Tao Huang*, Guangqi Jiang*, Yanjie Ze, Huazhe Xu†, ECCV 2024.
30. 3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations, Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, Huazhe Xu, RSS 2024.
29. ACE: Off-Policy Actor-Critic with Causality-Aware Entropy Regularization, Tianying Ji*, Yongyuan Liang*, Yan Zeng, Yu Luo, Guowei Xu, Jiawei Guo, Ruijie Zheng, Furong Huang, Fuchun Sun, Huazhe Xu, https://arxiv.org/pdf/2402.14528, Oral, ICML 2024.
28. Rethinking Transformer in Solving POMDPs, Chenhao Lu*, Ruizhe Shi*, Yuyao Liu*, Kaizhe Hu, Simon Shaolei Du, Huazhe Xu, https://arxiv.org/abs/2405.17358, ICML 2024.
27. Seizing Serendipity: Exploiting the Value of Past Success in Off-Policy Actor-Critic,Tianying Ji, Yu Luo, Fuchun Sun, Xianyuan Zhan, Jianwei Zhang, Huazhe Xu,https://arxiv.org/abs/2306.02865, ICML 2024.
26. Dehao Wei, Huazhe Xu, A Wearable Robotic Hand for Hand-over-Hand Imitation Learning, ICRA 2024
25. Zhengrong Xue*, Han Zhang*, Jingwen Cheng, Zhengmao He, Yuanchen Ju, Changyi Lin, Gu Zhang, Huazhe Xu, ArrayBot: Reinforcement Learning for Generalizable Distributed Manipulation through Touch, ICRA 2024
24. Dehao Wei, Huazhe Xu, A Wearable Robotic Hand for Hand-over-Hand Imitation Learning, ICRA 2024
23. Guowei Xu, Ruijie Zheng, Yongyuan Liang, Xiyao Wang, Zhecheng Yuan, Tianying Ji, Yu Luo, Xiaoyu Liu, Jiaxin Yuan, Pu Hua, Shuzhen Li, Yanjie Ze, Hal Daume III, Furong Huang, & Huazhe Xu, DrM: Mastering Visual Reinforcement Learning through Dormant Ratio Minimization. ICLR 2024
22. Xiyao Wang, Ruijie Zheng, Yanchao Sun, Ruonan Jia, Wichayaporn Wongkamjan, Huazhe Xu, Furong Huang, COPlanner: Plan to Roll Out Conservatively but to Explore Optimistically for Model-Based RL, ICLR 2024
21. Ruizhe Shi*, Yuyao Liu*, Yanjie Ze, Simon S. Du, Huazhe Xu, Unleashing the Power of Pre-trained Language Models for Offline Reinforcement Learning, ICLR 2024
20. Kun Lei, Zhengmao He, Chenhao Lu, Kaizhe Hu, Yang Gao, Huazhe Xu, Uni-O4: Unifying Online and Offline Deep Reinforcement Learning with Multi-Step On-Policy Optimization, ICLR 2024
19. Changyi Lin, Han Zhang, Jikai Xu, Lei Wu, Huazhe Xu, 9DTact: A Compact Vision-Based Tactile Sensor for Accurate 3D Shape Reconstruction and Generalizable 6D Force Estimation, IEEE Robotics and Automation Letters (RA-L), 2023 查看PDF
18. Zhecheng Yuan*, Sizhe Yang*, Pu Hua, Can Chang, Kaizhe Hu, Huazhe Xu, RL-ViGen: A Reinforcement Learning Benchmark for Visual Generalization, Conference on Neural Inforation Processing Systems (NeurIPS), 2023 查看PDF
17. Ruijie Zheng, Xiyao Wang, Yanchao Sun, Shuang Ma, Jieyu Zhao, Huazhe Xu+, Hal Daumé III+, Furong Huang+, TACO: Temporal Latent Action-Driven Contrastive Loss for Visual Reinforcement Learning, Conference on Neural Information Processing Systems (NeurIPS), 2023 查看PDF
16. Jialu Gao*, Kaizhe Hu*, Guowei Xu, Huazhe Xu, Can Pre-Trained Text-to-Image Models Generate Visual Goals for Reinforcement Learning?, Conference on Neural Information Processing Systems (NeurIPS), 2023 查看PDF
15. Sizhe Yang*, Yanjie Ze*, Huazhe Xu, MoVie: Visual Model-Based Policy Adaptation for View Generalization, Conference on Neural Information Processing Systems (NeurIPS), 2023 查看PDF
14. Yanjie Ze, Yuyao Liu*, Ruizhe Shi*, Jiaxin Qin, Zhecheng Yuan, Jiashun Wang, Huazhe Xu, H-InDex: Visual Reinforcement Learning with Hand-Informed Representations for Dexterous Manipulation, Conference on Neural Information Processing Systems (NeurIPS), 2023 查看PDF
13. Jinxin Liu*, Li He*, Yachen Kang, Zifeng Zhuang, Donglin Wang, Huazhe Xu, CEIL: Generalized Contextual Imitation Learning, Conference on Neural Information Processing Systems (NeurIPS), 2023 查看PDF
12. Yuerong Li, Zhengrong Xue, Huazhe Xu, OTAS: Unsupervised Boundary Detection for Object-Centric Temporal Action Segmentation, IEEE Winter Conference on Applications of Computer Vision (WACV), 2023 查看PDF
11. Nicklas Hansen*, Zhecheng Yuan*, Yanjie Ze*, Tongzhou Mu*, Aravind Rajeswaran+, Hao Su+, Huazhe Xu+, Xiaolong Wang+. On Pre-Training for Visuo-Motor Control: Revisiting a Learning-from-Scratch Baseline, International Conference on Machine Learning (ICML), 2023 查看PDF
10. Zhengrong Xue, Zhecheng Yuan, Jiashun Wang, Xueqian Wang, Yang Gao, Huazhe Xu. USEEK: Unsupervised SE(3)-Equivariant 3D Keypoints for Generalizable Manipulation, International Conference on Robot Automation (ICRA), 2023 查看PDF
9. Changyi Lin, Ziqi Lin, Shaoxiong Wang, Huazhe Xu. DTact: A Vision-Based Tactile Sensor that Measures High-Resolution 3D Geometry Directly from Darkness, International Conference on Robot Automation (ICRA), 2023 查看PDF
8. Ray Chen Zheng*, Kaizhe Hu*, Zhecheng Yuan, Boyuan Chen, Huazhe Xu. Extraneousness-Aware Imitation Learning, International Conference on Robot Automation (ICRA), 2023 查看PDF
7. Yunfei Li*, Chaoyi Pan*, Huazhe Xu, Xiaolong Wang, Yi Wu. Efficient Bimanual Handover and Rearrangement via Symmetry-Aware Actor-Critic Learning, International Conference on Robot Automation (ICRA), 2023 查看PDF
6. Kaizhe Hu*, Ray Zheng*, Yang Gao, Huazhe Xu. Decision Transformer under Random Frame Dropping, International Conference on Learning Representation (ICLR), 2023 查看PDF
5. Pu Hua, Yubei Chen+, Huazhe Xu+. Simple Emergent Action Representations from Multi-Task Policy Training, International Conference on Learning Representation (ICLR), 2023 查看PDF
4. Linfeng Zhao, Huazhe Xu, Lawson L.S. Wong. Scaling up and Stabilizing Differentiable Planning with Implicit Differentiation, International Conference on Learning Representation (ICLR), 2023 查看PDF
3. Ruijie Zheng*, Xiyao Wang*, Huazhe Xu, Furong Huang, Is Model Ensemble Necessary? Model-based RL via a Single Model with Lipschitz Regularized Value Function, International Conference on Learning Representation (ICLR), 2023 查看PDF
2. Zhecheng Yuan, Zhengrong Xue, Bo Yuan, Xueqian Wang, Yi Wu, Yang Gao, Huazhe Xu, Pre-Trained Image Encoder for Generalizable Visual Reinforcement Learning, Conference on Neural Information Processing Systems (NeurIPS), 2022 查看PDF
1. Can Chang, Ni Mu, Jiajun Wu, Ling Pan, Huazhe Xu, E-MAPP: Efficient Multi-Agent Reinforcement Learning with Parallel Program Guidance, Conference on Neural Information Processing Systems (NeurIPS), 2022 查看PDF








