上海期智研究院PI,上海交通大学计算机科学与工程系教授。
2007年于上海交通大学获得计算机科学与技术学士学位,2013年于香港中文大学计算机科学与工程系获得博士学位。研究方向为计算机体系架构与设计自动化。在AI专用处理器,编译器,异构加速器设计,与存算一体架构等领域有多项技术突破成果。在相关领域发表会议与期刊论文100余篇,获2次最佳论文奖,1次最佳博士论文奖,多次最佳论文提名。入选国家级青年人才计划,曾获ACM上海新星奖, CCF集成电路Early Career Award等。承担二十余项国家、省部级项目,相关成果已被引入IEEE P1838标准,并且与台积电、华为和阿里巴巴合作的几项技术已商业化使用。
个人荣誉
2023年,入选国家级青年人才计划(QB)
2022年,吴文俊人工智能奖(芯片类)二等奖
2019年,CCF(中国计算机学会)集成电路Early Career Award
2019年,中国图灵大会,ACM上海新星奖
存算一体架构:构建存储内计算的非冯诺依曼系统架构的关键科学问题与技术挑战,突破内存墙瓶颈
高性能AI系统:算法、编解码、编译与架构跨层协同的设计与优化,解决大模型的算力、访存与通信瓶颈
成果7:MILLION开源框架定义模型量化推理新范式(2025年度)
在通用人工智能的黎明时刻,大语言模型被越来越多地应用到复杂任务中,虽然展现出了巨大的潜力和价值,但对计算和存储资源也提出了前所未有的挑战。在以 transformer 模型为基础的大模型中,键值缓存虽然用以存代算的思想显著加速了推理速度,但在长上下文场景中成为了存储瓶颈。例如,半精度的 LLaMA-2-7B 模型权重约 14GB,在上下文长度为 128K 时键值缓存占据 64GB,总和已经接近高端卡 NVIDIA A100 的 80GB 显存容量上限。键值量化可被用于压缩缓存,但往往受到异常值的干扰,导致模型性能的显著下降。为此,本文的研究者提出了 MILLION,一种基于乘积量化的键值缓存压缩和推理加速设计。

arxiv 链接:https://arxiv.org/abs/2504.03661
开源链接:https://github.com/ZongwuWang/MILLION
整型量化的软肋:异常值
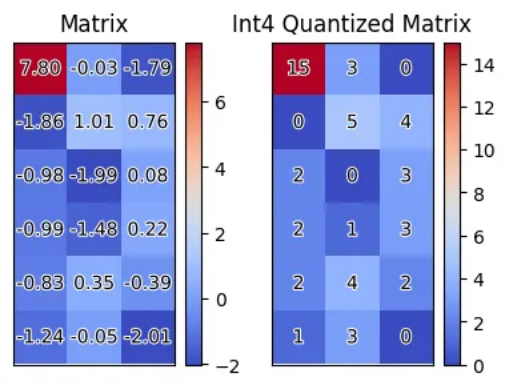
图1 :矩阵量化可视化。红色代表的异常值显著大于其他值,导致均匀量化后高位编码被浪费。
量化中受到广泛使用的整型均匀量化受到异常值的影响较为显著。图 1 展示了矩阵中的量化。在一组分布较为集中的数据中,一个显著偏离其他值的异常值会导致其他值的量化结果全部落在较低区间,浪费了高位编码的表示能力。
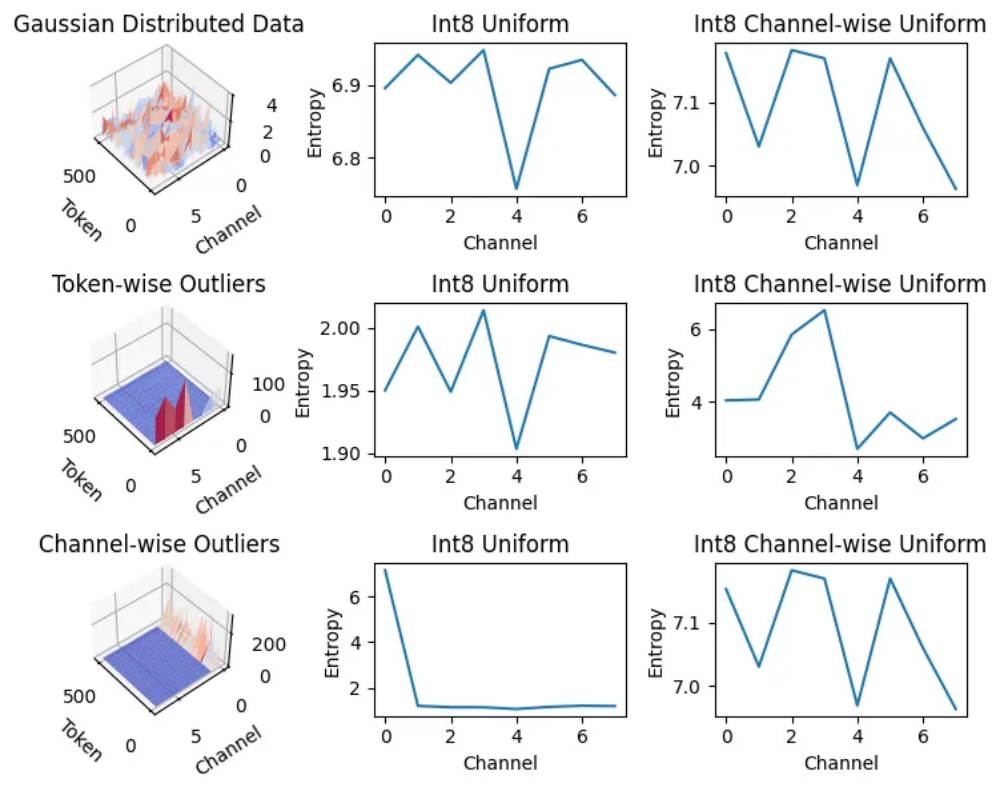
图 2:图中使用 「通道熵」 定量比较不同方案的量化效果,越大表明越有效地利用了通道容量,即整型的宽度。沿通道量化只能解决沿该方向分布的异常值,而在面对另一方向异常值时效果不佳。
在实际的键值量化中,为了更好的表示能力,通常对于每个通道(即键值向量的维度)或每个 token 采取不同的量化参数,这种方法被称为沿通道量化(channel-wise quantization)或沿词元量化(token-wise quantization)。然而,如图 2 所示,沿特定方向量化只能解决沿该方向分布的异常值。
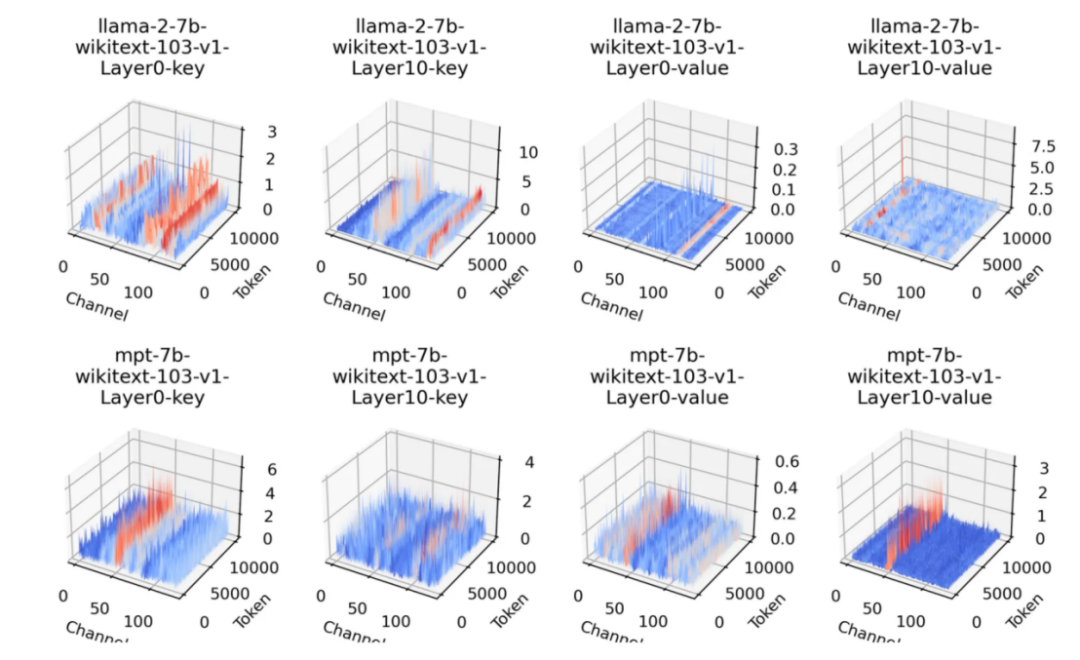
图3:实际采样获得的键值缓存分布。在 llama-2-7b-wikitext-103-v1-layer10-value 中,异常值并不遵循简单的沿通道分布,而是呈现为较复杂的点状和团状。
研究团队通过实际采样数据发现,在键值缓存中,沿通道方向分布的异常值占多数,但也存在并不明显的情况,如图 3 所示。这表明,上述量化方案并不是一劳永逸的解决方式,仍然存在优化空间。
异常值的解决方案:乘积量化
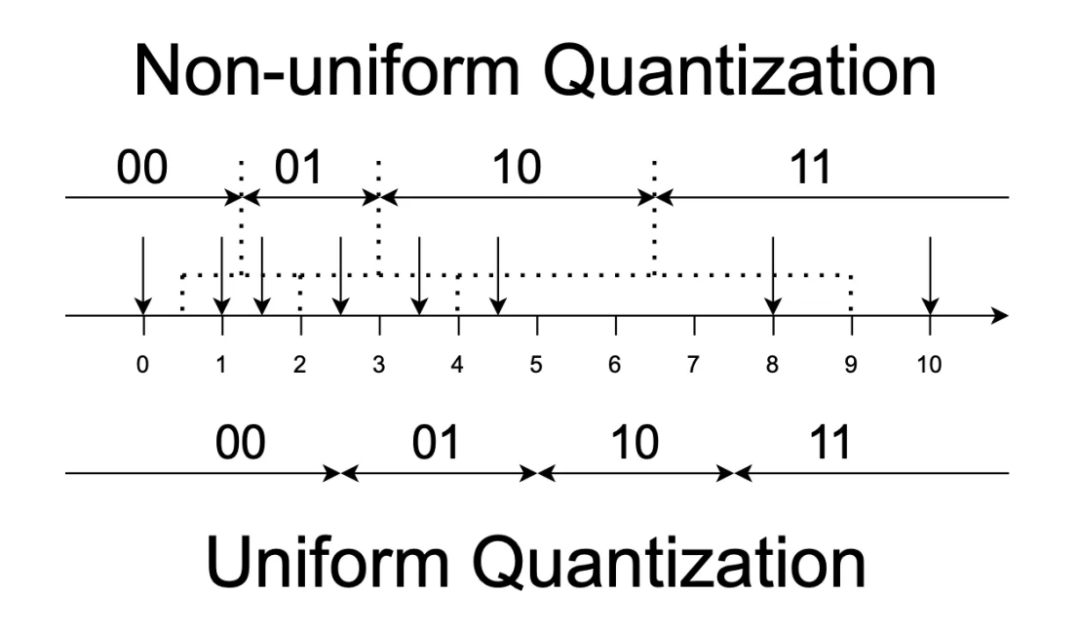
图 4:数轴上的均匀和非均匀量化对比。在对 8 个数据点进行 2 比特量化过程中,均匀量化浪费了 10 编码。而基于聚类的非均匀量化则编码更合理。
如图 4 所示,非均匀量化通过聚类的方式允许量化区间不等长,从而更合理地分配编码,提升量化效率。研究团队观察到,由于通道间的数据分布可能存在关联(即互信息非负),将通道融合后在向量空间中聚类,效果一定不亚于独立通道的量化,如图 5 所示。
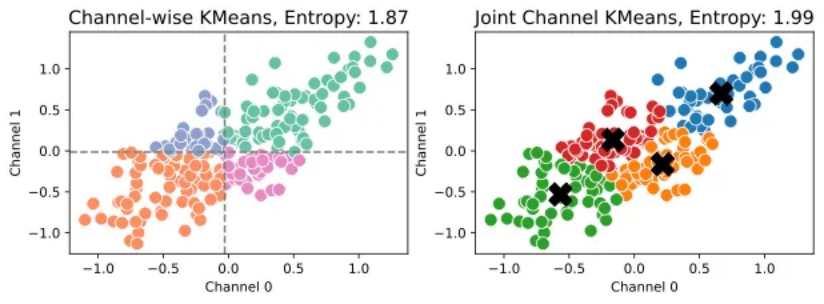
图 5:左图为两个通道独立进行 1 比特量化,右图为在通道融合后进行 4 分类的 KMeans 聚类。融合通道量化的通道熵更加接近 2 比特的容量极限,展示出更好的量化效果。
由于高维空间中聚类较为困难,因此将整个向量空间划分为多个低维子空间的笛卡尔积,可以平衡聚类复杂度和量化效果。这与最近邻搜索中使用的乘积量化思想一致。研究团队通过实验发现,子空间维度为 2 或 4 是较好的平衡点。
推理加速手段:高效的系统和算子实现
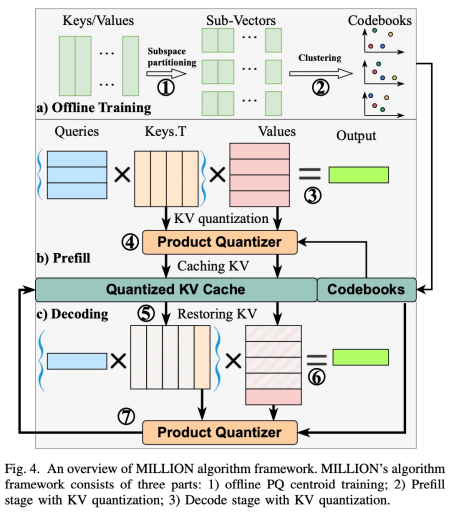
图 6:三阶段的推理系统设计

图 7:分块注意力机制使得批量延迟量化成为可能
图 6 展示了离线训练、在线预填充、在线解码三阶段的量化推理系统设计。其中,码本训练(量化校准)属于秒级轻量化任务,并且离线进行,不影响运行时开销;在线预填充阶段使用训练好的码本对键值缓存进行量化压缩,达到节省显存的目的;在线解码阶段采用分块注意力机制的方法,将预填充阶段的历史注意力和生成 token 的自注意力分开计算(如图 7 所示),达成批量延迟量化的目的,掩藏了在线量化的开销,确保模型输出的高速性。并且,在历史注意力阶段,由于历史键值对数远大于码本长度,因此先用查询向量与码本计算好非对称距离查找表(ad-LUT),可以大大减少内积距离计算量,达到加速计算的目的。
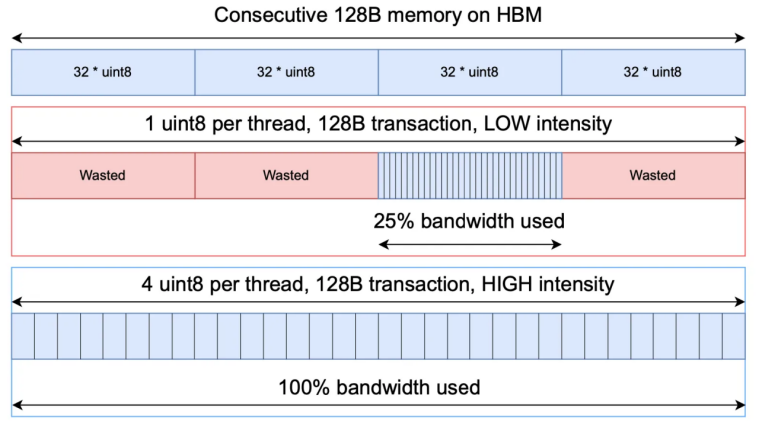
图 8:向量化加载可有效使带宽饱和
在算子优化方面,研究团队在 flash decoding 的基础上使用了宽数据(如 float4)向量化加载的方式,将多个乘积量化编码打包为宽数据,有效使带宽饱和(如图 8 所示)。同时,在表查找阶段,子空间之间的表具有独立性,并且可以被放入少量缓存行中,研究团队利用这一空间局部性极大提高了表查找的 L2 缓存命中率。此外,研究团队还仔细扫描了不同上下文长度下可能的内核参数,找到最优配置,形成了细粒度的预设,在实际运行时动态调整,充分利用 GPU 的计算资源。具体实现可以在开源仓库中找到。
实验结果
实验设置
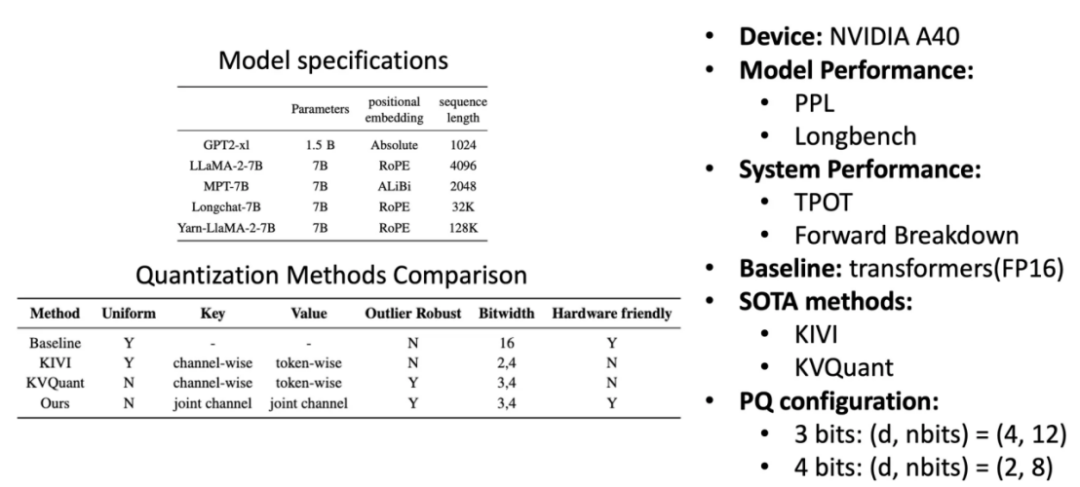
图 9:实验设置
实验采用了不同位置编码、不同上下文长度的多种模型进行了详细的评估。在模型性能方面,采用困惑度(Perplexity,PPL)和 Longbench 两种指标;在系统性能方面,采用每词元输出间隔(Time Per Output Token, TPOT)定量分析,并给出了注意力层详细的剖析。对比采用方案和乘积量化参数如图 9 所示。
模型性能、
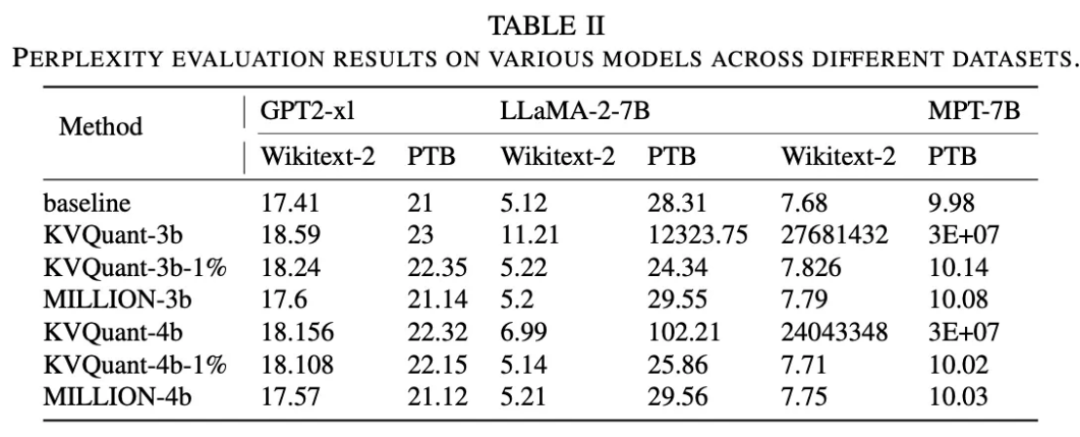
图 10:困惑度指标。其中 「-1%」 表示该方法额外存储 1% 的异常值不参与量化。
困惑度越小表明模型输出质量越高。实验结果表明,MILLION 与额外处理了异常值的 SOTA 方案输出质量保持一致,展现出对异常值良好的鲁棒性。而 SOTA 方案在不处理异常值的情况下可能会遭遇严重的输出质量损失。
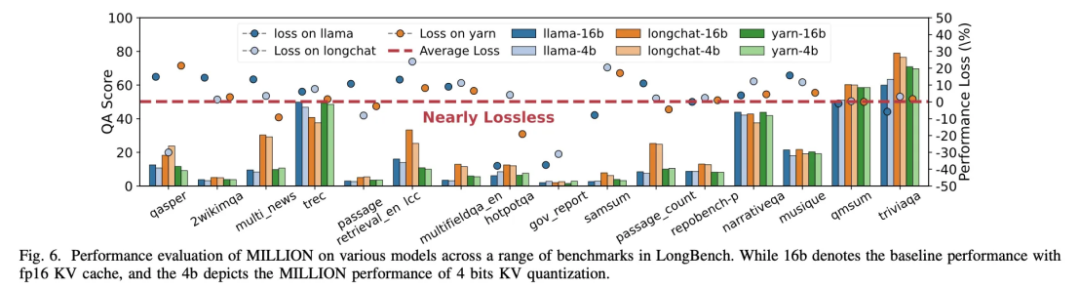
图 11:Longbench 问答数据集得分展示
在长对话问答任务中,不同模型在各种数据集上的得分均表明,MILLION 方案能够在 4 倍键值缓存压缩效率下保持几乎无损的表现。
系统性能
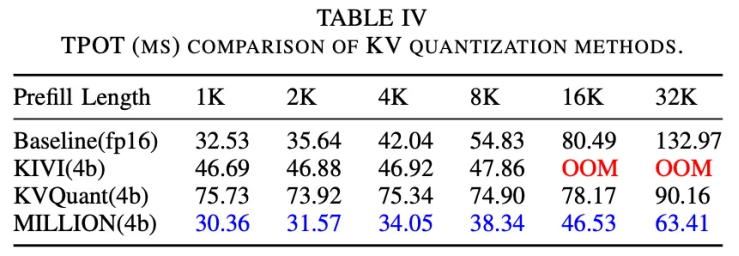
图 12:每词元输出时间。对比其他方案,MILLION 的优势持续增长,在 32K 上下文时达到 2 倍加速比。
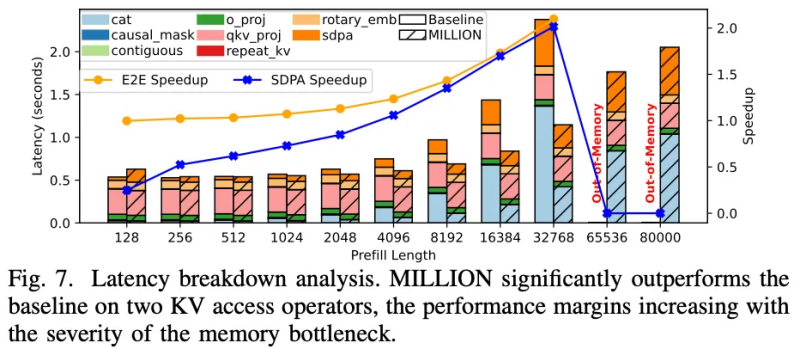
图 13:注意力层时间剖析
在 TPOT 评估中,MILLION 能够在 32K 上下文语境下同时达成 4 倍键值缓存压缩比和 2 倍端到端加速比。注意力层的深入分析表明,MILLION 在访存和内核函数方面对比 baseline 取得显著优势。
总结
MILLION 的主要贡献在于:(1)深入分析键值缓存分布;(2)提出基于乘积量化的非均匀量化算法;(3)设计高效的推理系统及内核。研究团队首先证实了键值缓存中异常值存在的普遍性,并指出异常值的不同分布是当前主流的量化方案精度不足的根本原因;然后提出通过将高维向量空间分解为多个子空间,并在每个子空间内独立进行向量量化的方法,更有效地利用了通道间的互信息,并且对异常值展现出极强的鲁棒性;接着通过 CUDA 异步流和高效的算子设计,充分利用了 GPU 的并行计算能力和内存层次结构,以支持乘积量化的高效执行。实验表明,对比主流框架 transformers 的半精度实现,MILLION 在 32K 上下文场景中同时达成 4 倍压缩率和 2 倍加速比,并且在多种语言任务中精度表现几乎无损。
------------------------------------------------------------------------------------------------
成果6:基于索引对编码的DNN加速方案—INSPIRE(2024年度)
DNN推理消耗了大量的计算和存储资源。传统的量化方法大多依赖于固定长度的数据格式,在处理异常值 (outliers) 时往往导致模型精度下降。现有的可变长度量化方法涉及复杂的编码和解码算法,引入了显著的硬件开销。为解决这一问题,蒋力团队提出了一种针对DNN加速的算法/架构协同设计方案,引入索引对 (Index-Pair, INP) 量化方法,以低硬件开销和高性能增益有效处理了量化过程中的异常值,加速器有较好的软件亲和性。
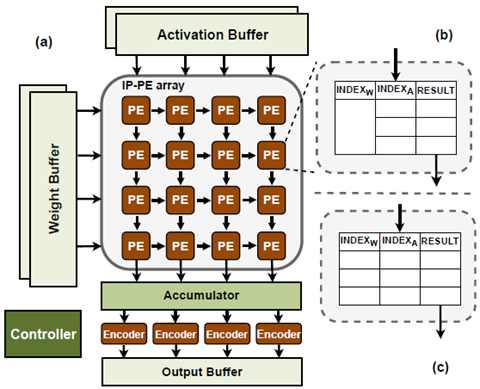
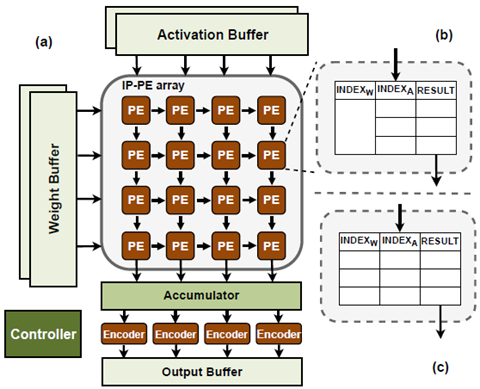
图1. INSPIRE架构概述
如图1所示,INSPIRE方案的核心在于:
(1) 索引对量化 (INP Quantization) :使用可变长度量化,识别与重要值相关的数据特征并将其编码为索引。在推理过程中,利用查找表 (LUT) 高效地存储/检索预先(线下)计算的结果,从而消除了运行时的计算开销。
(2) 全局异常值处理:INSPIRE用聚类法确定激活值和权重的质心 (centroids),并对这些质心进行编码,有效地适应了不同值的重要性变化。主要聚类算法不仅作用于权重还作用域激活值,可以对两者同时量化索引。同时,有足够的索引空间来覆盖所有异常值。
(3) 统一处理单元架构 (Unified Processing Element Architecture):设计了一个统一的处理单元架构 (IP-PE),用基于索引对匹配的LUT单元,直接替换传统基于数值乘累加 (MAC) 操作的ALU单元,与可以现有DNN加速器架构无缝集成。实验结果表明,本方案的加速器在模型精度近乎无损的同时,性能加速9.31倍,能耗减少81.3%。
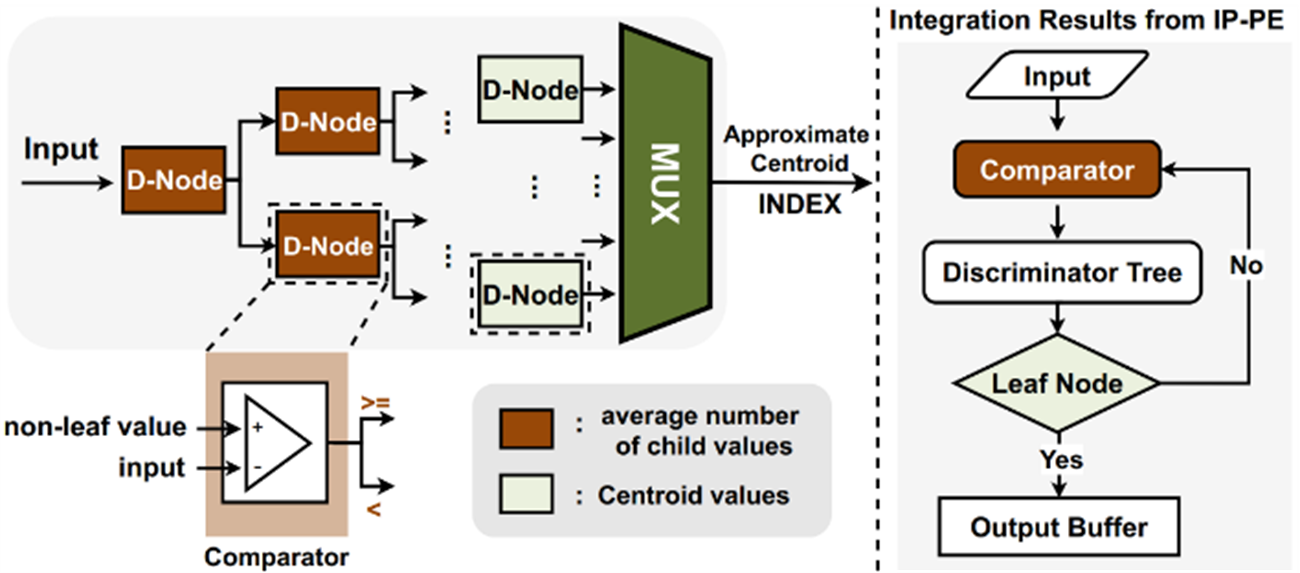
图2. INSPIRE编码器的设计及编码计算过程
INSPIRE创新了量化技术和架构设计,实现一种全新的DNN加速器设计,将在自动驾驶、实时翻译、嵌入式系统等领域具有广泛的应用前景。相关成果收录于DAC 2024中。本论文一作为期智研究院兼职研究员、上海交通大学助理研究员刘方鑫。
论文信息:INSPIRE: Accelerating Deep Neural Networks via Hardware-friendly Index-Pair Encoding, Fangxin Liu, Ning Yang, Zhiyan Song, Zongwu Wang, Haomin Li, Shiyuan Huang, Zhuoran Song, Songwen Pei and Li Jiang, DAC 2024.
------------------------------------------------------------------------------------------------
成果5:基于脉冲编码的SNN可靠性建模与优化(2024年度)
SNN作为传统人工神经网络的高能效替代方案正在崭露头角。虽然SNN非常适合部署在边缘计算设备,但各种安全问题也随之浮现。蒋力团队发现:SNN实现中的能量消耗与脉冲活性密切相关,设计了一种针对SNNs的新型攻击方法—能量导向的SNN攻击框架EOS,旨在通过恶意操纵存储了神经元信息的DRAM-cell来增加其能耗。
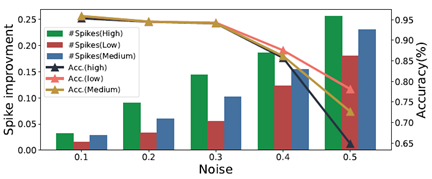
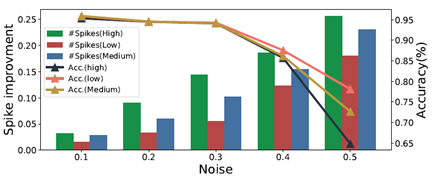
图1. 不同噪声模式下SNN的准确度和神经元的活跃度
该框架采用了嵌入式攻击中主流的行锤攻击 (Row Hammer) 来翻转DRAM-cell的二进制位 (bit)。为了减少被发觉的可能性,通过识别SNN中脉冲活性最强大的神经元,并尽可能减少比特翻转来实现此目标。进一步,采用了脉冲活性分析和渐进搜索策略的组合来确定位翻转攻击的目标神经元,其主要目标是在确保准确性不受影响的情况下逐步增加SNN的能耗。经过实验,通过该攻击框架的实施,在不影响模型准确度的情况下,SNN平均能耗增加43%,表明了该攻击方法的隐蔽性和有效性。
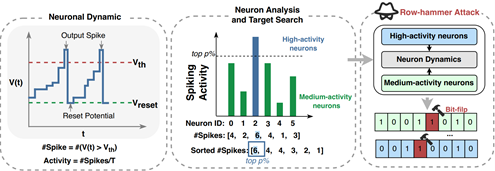
图4. EOS攻击框架概述
EOS进一步回答了如何抵御能耗攻击的问题,为SNN安全提供了新视角,这对于需要在边缘设备上部署SNNs的应用场景尤为重要。相关成果收录于DAC 2024中。
论文信息:EOS: An Energy-Oriented Attack Framework for Spiking Neural Networks, Yilong Zhao, Mingyu Gao, Fangxin Liu, Yiwei Hu, Zongwu Wang, Han Lin, Ji Li, He Xian, Hanlin Dong, Tao Yang, Naifeng Jing, Xiaoyao Liang, Li Jiang, DAC 2024.
------------------------------------------------------------------------------------------------
成果4:基于八叉树编码的存内搜索碰撞检测—RTSA(2024年度)
运动规划是机器人运动导航的关键功能,其中,碰撞检测又是运动规划中极其耗时的部分,通常占据总计算时间的90%以上。现有的FPGA加速器在大型路线图的运动规划任务中难以保持计算的实时性。蒋力团队针对这一难题,提出了一种基于RRAM-TCAM的存内搜索硬件加速器 (RTSA)。它专为在运动规划中的碰撞检测任务设计,可实现亚100μs级的响应时间。
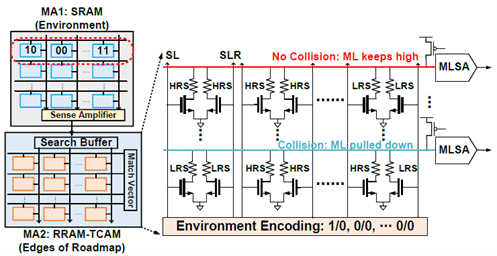
(1) 基于RRAM-TCAM的内存搜索碰撞检测加速器:RTSA结合了基于电阻式随机存取存储器 (RRAM) 密度高、功耗低的特点,以及三态内容可寻址存储器 (TCAM) 体积小、搜索速度快和能效高的特点,来实现碰撞检测逻辑。这种设计实现了大规模并行搜索操作,从而显著减少了数据在内存和计算单元之间的传输需求。
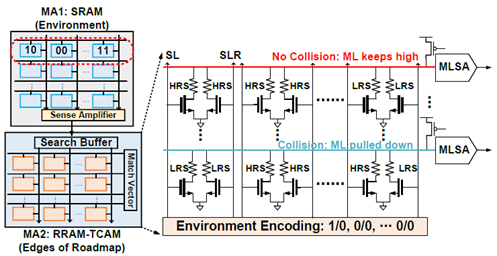
图1.TCAMs 工作流映射方案及配置
(2) 亚100μs级的碰撞检测响应时间:可以在800 MB规模的路线图中实现亚100μs的碰撞检测响应时间。该结构相比先前基于硬件的碰撞检测加速器实现了27-286倍的加速,相比基于CPU的碰撞检测加速了超过4,356倍。
(3) 八叉树编码和电路架构设计:对环境和路线图边缘使用两比特编码来表示三种不同的空间状态:占用、部分占用和空闲空间。设计中使用SRAM存储环境信息以便于频繁修改,同时使用RRAM-TCAM存储路线图边缘信息,这些边缘信息不需要频繁更新。这种设计不仅提高了碰撞检测的速度和能效,还减少了计算资源的占用。
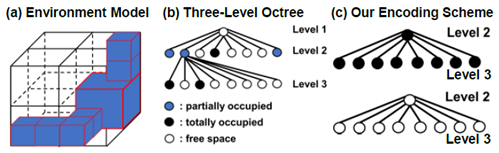
图2. 八叉树编码示意图
RTSA不仅提高了计算速度,还减少了能耗,为机器人运动规划、制造和物理模拟等多种应用提供快速且能效高的碰撞检测解决方案。相关成果收录于DATE 2024。
论文信息:RTSA: An RRAM-TCAM based In-Memory-Search Accelerator for Sub-100 μs Collision Detection, Jiahao Sun, Fangxin Liu, Yijian Zhang, Li Jiang, and Rui Yang, DATE 2024.
------------------------------------------------------------------------------------------------
成果3:在近 DRAM Bank 处理架构中的跨 Bank 协调支持—NDPBridge(2024年度)
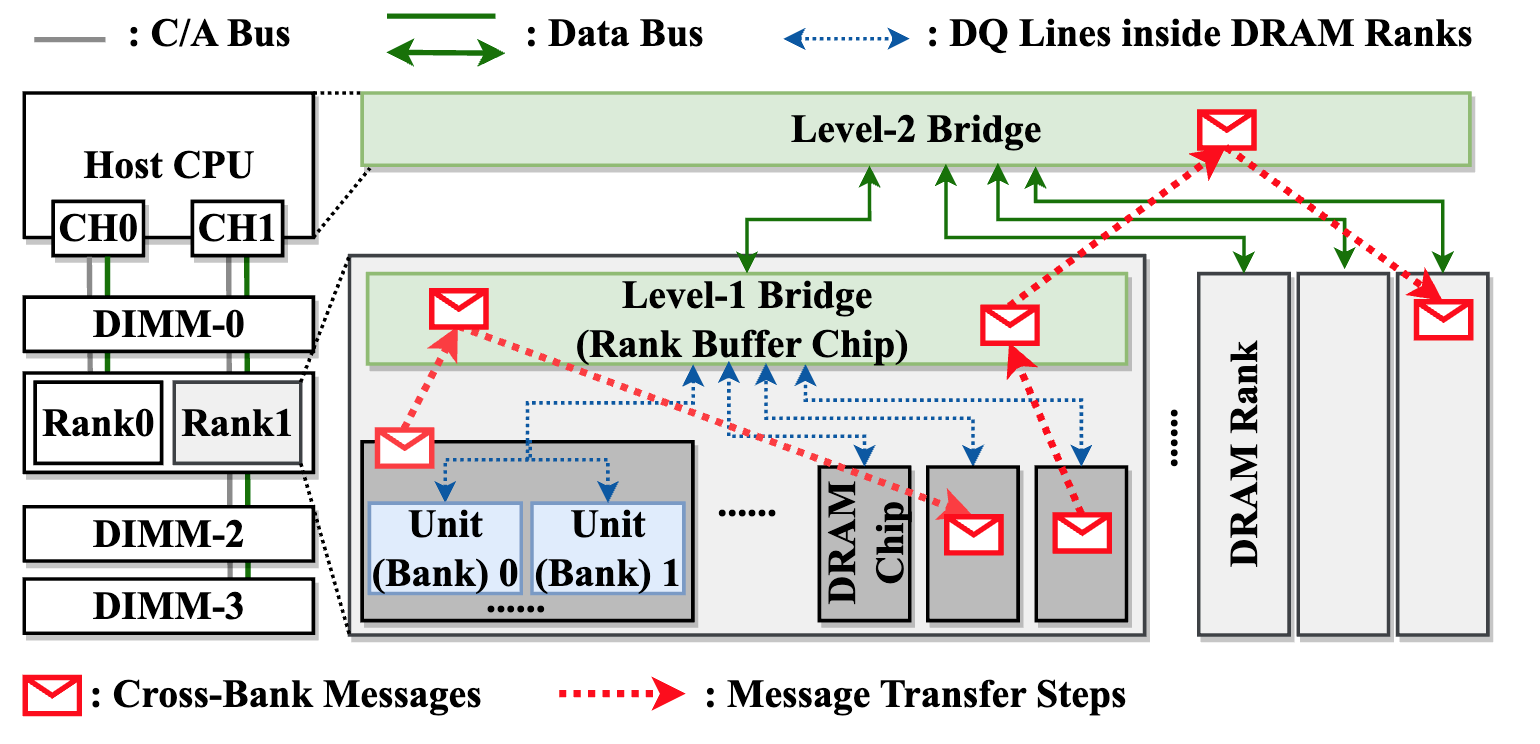
近数据处理架构是一条缓解内存墙问题、降低内存访问开销的重要技术路线。其中,近DRAM bank架构在DRAM bank附近集成计算逻辑,每个bank及其周围的计算逻辑构成独立单元,可以高效并行访问和处理数据。但是,近DRAM bank架构同样面临两点主要挑战。首先,不同的单元互相隔离,无法进行跨单元通信。此外,由于系统由上千个单元组成,单元间的负载均衡也需要得到高效支持。】
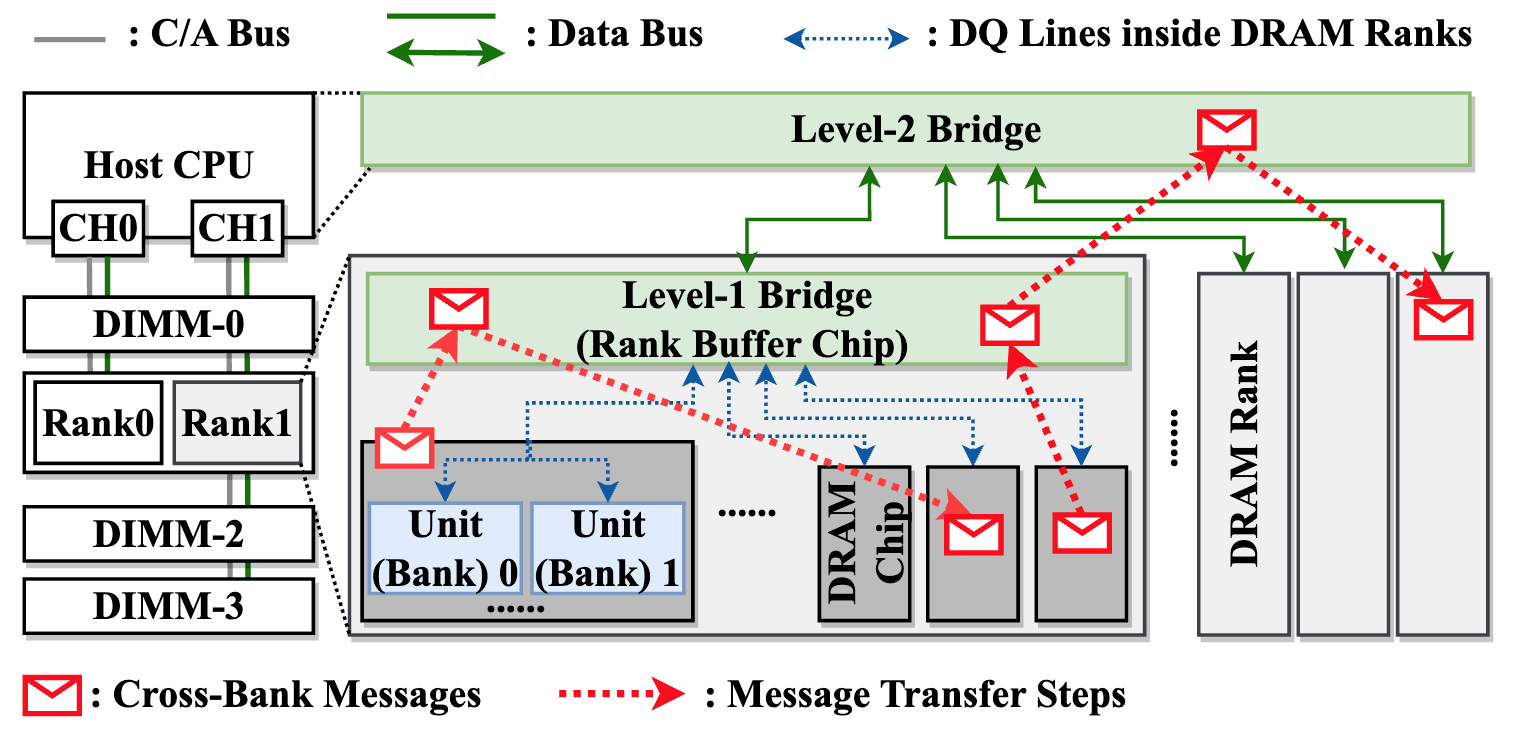
图1. OP-C2B 算法
高鸣宇团队与蒋力团队合作提出一种软硬件协同设计方案NDPBridge,在硬件层面,引入硬件桥,通过复用DRAM内部现有硬件接口和连线资源,在DRAM内部支持了跨bank传输。在软件层面,在上述硬件通讯机制基础上,他们设计了层次化和数据传输感知的调度方案,高效支持了跨单元负载均衡。
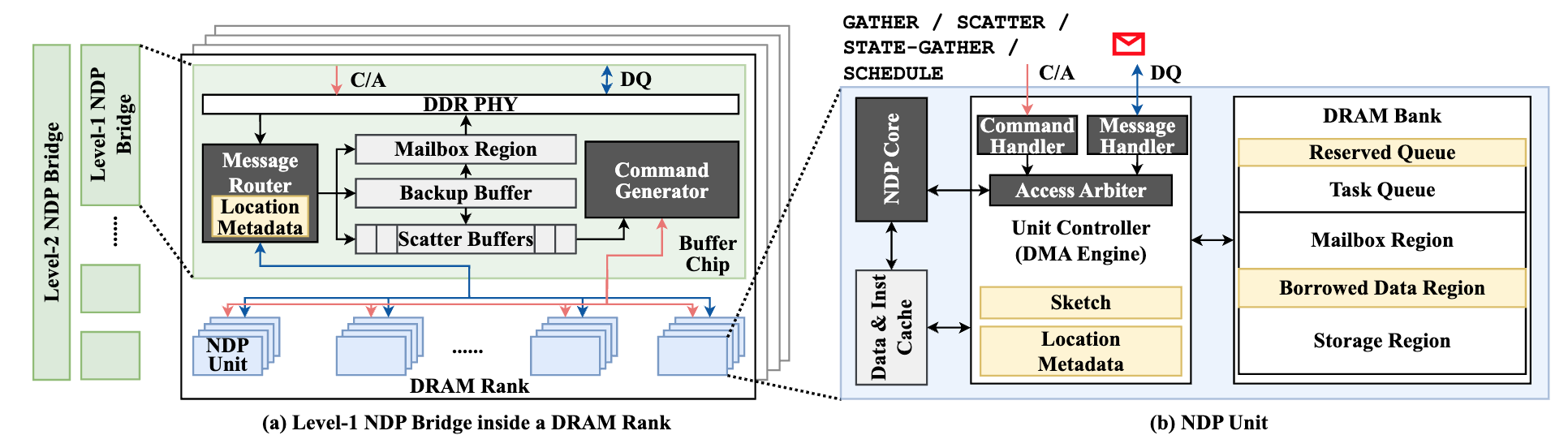
图2. NDPBridge中NDP单元和桥接部分的详细硬件结构
NDPBridge在性能、开销和适用性等方面具有显著优点,具体包括:
1. 相较于现有近DRAM bank处理方案,实现了平均2.23倍、最高2.98倍性能提升。
2. 硬件修改开销较小,对于DRAM内部芯片的尺寸和接口没有修改,且所有的修改均限制在现有的近数据处理产品修改过的硬件模块中。
3. 该架构对软件适配性较好,可应用至多种类型的应用和不同的数据规模。此外,由于该架构实现了自动的跨单元通信优化和负载均衡,大大降低了上层程序员的编程负担。
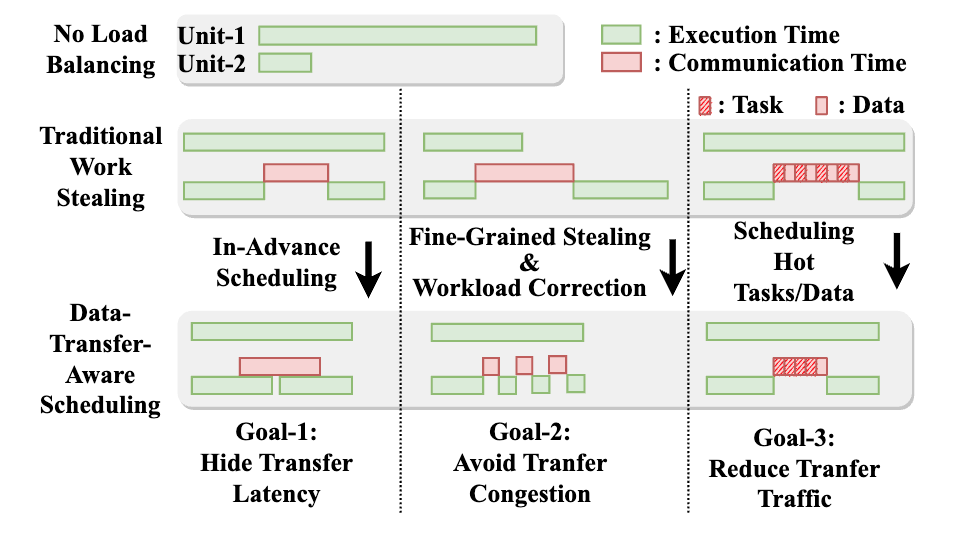
图3. 数据传输感知调度中的三个关键设计考虑因素
NDPBridge的成功实现不仅扩展了近bank NDP系统的应用范围,使其能够处理更复杂的应用场景,还为内存密集型应用提供了一种有效的解决方案,对于推动数据处理架构的发展具有重要意义。
论文信息:NDPBridge: Enabling Cross-Bank Coordination in Near-DRAM-Bank Processing Architectures, Boyu Tian, Yiwei Li, Li Jiang, Shuangyu Cai, and Mingyu Gao, ISCA 2024.
------------------------------------------------------------------------------------------------
成果2:软硬协同的稀疏存内计算架构(2023年度)
随着数据为中心的人工智能应用不断增长,传统处理器面临着处理能力、性能和能耗瓶颈的挑战。为了突破内存墙和能效墙的限制,存算一体架构成为领域专用处理器设计的趋势之一。蒋力团队在2023年进一步扩展了对存算一体架构的研究,不仅进一步探索细粒度动静态稀疏性数据,从而提升计算性能和能效。特别是将超维计算(HDC)的特点——高维数据表示和并行处理能力——与存算一体架构的优势结合起来。这一融合旨在应对传统处理器在处理大量非结构化、非规则稀疏数据时面临的性能和能效瓶颈。开发新型存算一体架构,该架构可以更有效地利用细粒度动静态稀疏性数据,从而提升计算性能和能效。
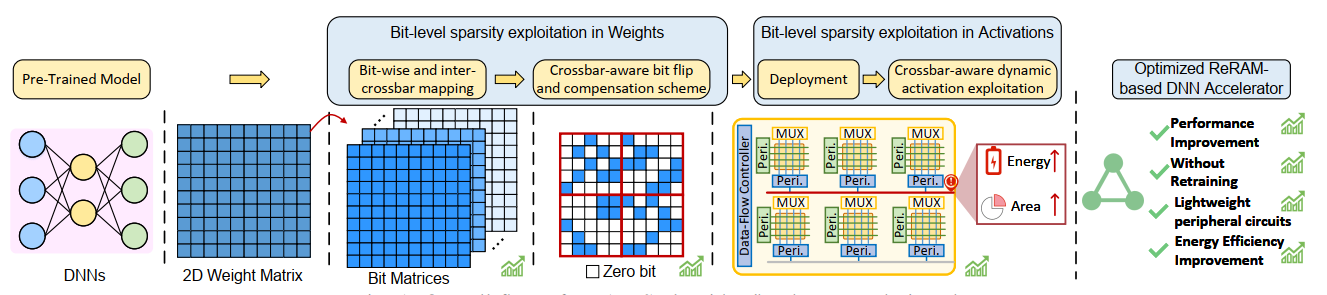
图. 存算一体架构动静态稀疏利用示意图
忆阻器阵列在存算一体架构中,因其高度结构化的操作数与数据流紧耦合问题,虽提供了计算的高并行性,但对细粒度的稀疏性支持不足。针对这一问题,2023年度的研究中,我们提出了一种新的架构设计方法,有效结合了静态稀疏和动态稀疏。对于静态稀疏,通过解耦数据流和操作数,我们设计了一种灵活的数据路径,使得架构能够在不牺牲并行性的同时,更高效地支持细粒度压缩。对于动态稀疏,利用层次化结构化稀疏范式,以有效地加速深度神经网络模型,特别是在面对不同、运行时稀疏性。这种方法通过将张量值分成更小的块并赋予每个块简单的稀疏模式,实现了模型性能的优化这种方法不仅提高了计算性能,也降低了能耗,为存算一体架构可以更高效地处理大规模数据集中的稀疏性提供了更好的支持。
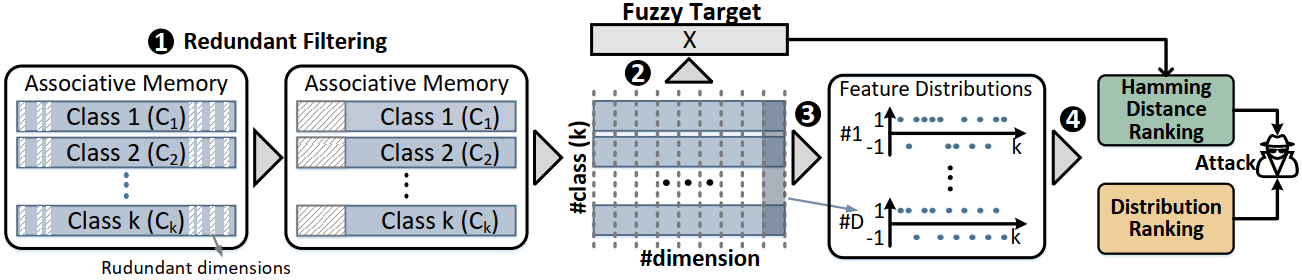
图. 类脑融合的安全性测试示意图
类脑计算范式,特别是超维计算(HDC),因其在模拟人脑处理信息的方式上具有独特的优势,正在被广泛研究以优化边缘端部署的安全性。这种计算范式使用高维向量(即超向量)来表示数据和操作,可以通过简单的几何和代数操作来执行学习和认知任务。HDC的核心优势之一在于其超向量的稳健性,即使在噪声或错误数据的情况下也能维持其功能。在存算一体架构研究中嵌入HDC,不仅提高了计算效率,也极大地加强了边缘设备的安全性。
团队针对以存算一体架构为代表的非冯计算架构,通过细粒度稀疏算法和架构的协同优化,显著提高了神经网络计算性能。将算法进一步融合AI编译框架中,通过多层IR机制,用一种特殊的IR来表示稀疏张量算子。通过编译lowering与lifting的两次pass结合,自动根据芯片架构的张量运算单元的粒度(如忆阻器阵列大小)进行稀疏算子的拆分,以及最优化的算子融合(重新融合成不包含或只包含少量零的张量算子)。
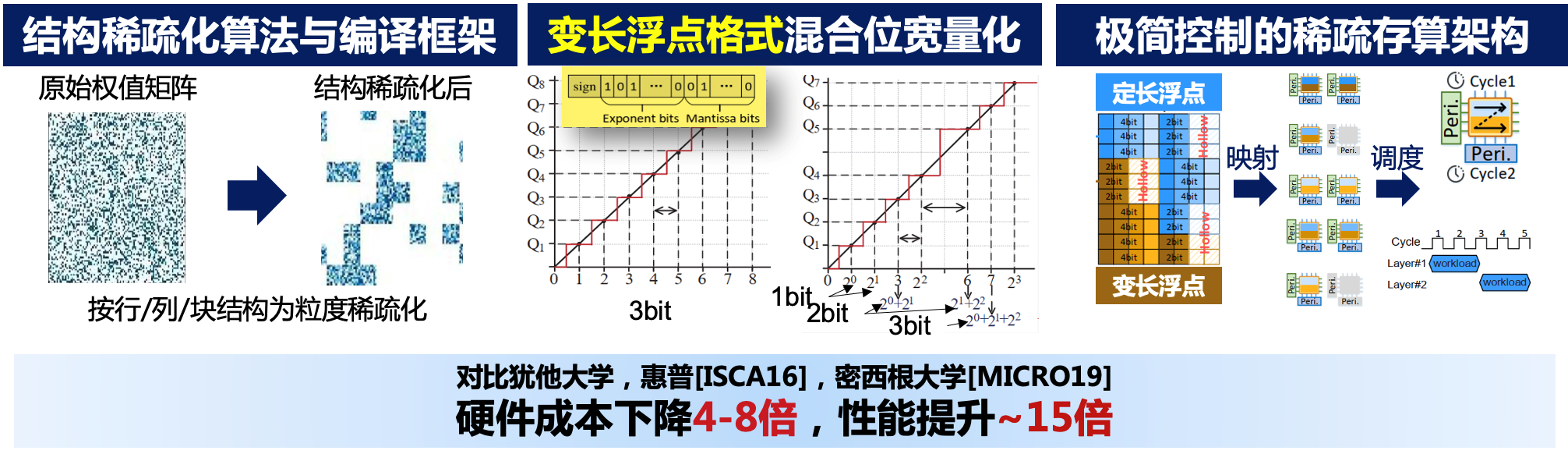
图示:细粒度的稀疏化算法与映射方法 课题组的相关成果发表于2023年的欧洲设计自动化与测试学术会议(DATE)、IEEE计算机汇刊 (TC)和设计自动化会议(DAC),并荣获最佳论文提名奖。稀疏编译器提升了华为昇腾处理器2倍性能,合入了华为Mindspore开源AI编译框架,并荣获华为火花奖。

------------------------------------------------------------------------------------------------
成果1:多比特神经形态计算阵列精度自适应编程(2023年度)
针对现有基于ReRAM神经形态计算系统中普遍存在的高阻值不稳定性的问题,亟需一种高效高精度的ReRAM的权值映射方案,这也是所有基于忆阻器件的存算系统所必须要解决的关键性问题。蒋力团队提出了多比特精度自适应编程的电路级解决方案,并深度融合现有存算系统,使得ReRAM存算系统的存储密度和算力提升2倍,同时神经网络权值部署速度和能效分别提升4.7倍和2倍。从早期SAWM编程电路工作出发,与现有的ReRAM-based存算一体加速系统深度融合,在最大程度复用现有外围电路的基础之上,设计实现了极致紧凑的自适应编程电路,单编程通道只需要额外增加7个晶体管,就可以同时实现对SET和RESET操作的自适应截止,同时紧凑的电路设计还保证了反馈电路的高效性,实现更加精确的阻值控制。该成果发表在2022年的欧洲设计自动化与测试学术会议(Design, Automation and Test in Europe, DATE),并荣获Test and Dependability领域最佳论文奖。





36. INSPIRE: Accelerating Deep Neural Networks via Hardware-friendly Index-Pair Encoding, Fangxin Liu, Ning Yang, Zhiyan Song, Zongwu Wang, Haomin Li, Shiyuan Huang, Zhuoran Song, Songwen Pei and Li Jiang, DAC 2024.
35. EOS: An Energy-Oriented Attack Framework for Spiking Neural Networks, Yilong Zhao, Mingyu Gao, Fangxin Liu, Yiwei Hu, Zongwu Wang, Han Lin, Ji Li, He Xian, Hanlin Dong, Tao Yang, Naifeng Jing, Xiaoyao Liang, Li Jiang, DAC 2024.
34. RTSA: An RRAM-TCAM based In-Memory-Search Accelerator for Sub-100 μs Collision Detection, Jiahao Sun, Fangxin Liu, Yijian Zhang, Li Jiang, and Rui Yang, DATE 2024.
33. UM-PIM: DRAM-based PIM with Uniform & Shared Memory Space, Yilong Zhao, Mingyu Gao, Fangxin Liu, Yiwei Hu, Zongwu Wang, Han Lin, Ji Li, He Xian, Hanlin Dong, Tao Yang, Naifeng Jing, Xiaoyao Liang, Li Jiang, ISCA 2024.
32. Haomin Li, Fangxin Liu, Yichi Chen and Li Jiang, HyperNode: An Efficient Node Classification Framework Using HyperDimensional Computing, ICCD, 2023 查看PDF
31. Fangxin Liu, Ning Yang and Li Jiang, PSQ: An Automatic Search Framework for Data-Free Quantization on PIM-based Architecture, ICCD, 2023 查看PDF
30. Fangxin Liu, HaominLi, Yongbiao Chen, TaoYang and Li Jiang, HyperAttack: An Effcient Attack Framework for HyperDimensional Computing, DAC, 2023 查看PDF
29. Tao Yang, YiyuanZhou, QidongTang, FengXu, HuiMa, JieruZhao and Li Jiang, SpM
MPlu: A Compiler Plug-in with Sparse IR for Efficient Sparse Matrix Multiplication, DAC, 2023 查看PDF
28. Fangxin Liu, Wenbo Zhao, Zongwu Wang, Yongbiao Chen, Xiaoyao Liang and Li Jiang, ERA-BS: Boosting the Efficiency of ReRAM-based PIM Accelerator with Fine-Grained Bit-Level Sparsity, IEEE Transactions on Computers , 2023 查看PDF
27. Fangxin Liu, Wenbo Zhao, Zongwu Wang, XiaokangYang and Li Jiang, SIMSnn:A Weight-Agnostic ReRAM-based Search-In-Memory Engine for SNN Acceleration, DATE, 2023 查看PDF
26. Tao Yang, HuiMa, Yilong Zhao, Fangxin Liu, Zhezhi He, Xiaoli Sun and Li Jiang, PIMPR:PIM-based Personalized Recommendation with Heterogeneous Memory Hierarchy, DATE, 2023 查看PDF
25. Tao Yang, Dongyue Li, Fei Ma, Zhuoran Song, Yilong Zhao, Jiaxi Zhang, Fangxin Liu and Li Jiang, PASGCN: An ReRAM-Based PIM Design for GCN With Adaptively Sparsified Graphs., TCAD, 2023 查看PDF
24. Fangxin Liu, Zongwu Wang, Yongbiao Chen, Zhezhi He, Tao Yang, Xiaoyao Liang and Li Jiang, SoBS-X: Squeeze-Out Bit Sparsity for ReRAM-Crossbar-Based Neural Network Accelerator, TCAD, 2023 查看PDF
23. Yanan Sun, Chang Ma, Zhi Li, Yilong Zhao, Jiachen Jiang, Weikang Qian, Rui Yang, Zhezhi He, Unary Coding and Variation-Aware Optimal Mapping Scheme for Reliable ReRAM-based Neuromorphic Computing, (TCAD) IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2021 查看PDF
22. Tao Yang, Dongyue Li, Yibo Han, Yilong Zhao, Fangxin Liu, Xiaoyao Liang, Zhezhi He, Li Jiang, PIMGCN: A ReRAM-Based PIM Design for Graph Convolutional Network Acceleration, (DAC) in ACM/IEEE Design Automation Conference, 2021 查看PDF
21. Yilong Zhao, Zhezhi He, Naifeng Jing, Xiaoyao Liang, Li Jiang, Re2PIM: A Reconfigurable ReRAM-based PIM Design for Variable-sized Vector-Matrix Multiplication, (GLSVLSI) in ACM Great Lakes Symposium on VLS , 2021 查看PDF
20. Fangxin Liu, Wenbo Zhao, Zongwu Wang, Tao Yang, Li Jiang, IM3A: Boosting Deep Neural Network Efficiency via In-Memory Addressing-Assisted Acceleration, (GLSVLSI) in ACM Great Lakes Symposium on VLSI, 2021 查看PDF
19. Zhuoran Song, Dongyue Li, Zhezhi He, Xiaoyao Liang, Li Jiang, ReRAM-Sharing: Fine-Grained Weight Sharing for ReRAM-Based Deep Neural Network Accelerator, (ISCAS) in International Symposium on Circuits and Systems , 2021 查看PDF
18. Xingyi Wang, Yu Li, Yiquan Chen, Shiwen Wang, Yin Du, Cheng He, YuZhong Zhang, Pinan Chen, Xin Li, Wenjun Song, Qiang xu, Li Jiang, On Workload-Aware DRAM Failure Prediction in Large-Scale Data Centers, (VTS) in IEEE VLSI Test Symposium, 2021 查看PDF
17. Fangxin Liu, Wenbo Zhao, Zhezhi He, Zongwu Wang, Yilong Zhao, Yongbiao Chen, Li Jiang, Bit-Transformer: Transforming Bit-level Sparsity into Higher Preformance in ReRAM-based Accelerator, (ICCAD)International Conference on Computer-Aided Design, 2021 查看PDF
16. Fangxin Liu,Wenbo Zhao,Zhezhi He,Yanzhi Wang,Zongwu Wang, Changzhi Dai, Xiaoyao Liang, Li Jiang, Improving Neural Network Efficiency via Post-training Quantization with Adaptive Floating-Point, (ICCV)International Conference on Computer Vision, 2021 查看PDF
15. Dongyue Li,Tao Yang,Lun Du,Zhezhi He,Li Jiang, AdaptiveGCN: Efficient GCN Through Adaptively Sparsifying Graphs, (CIKM)International Conference on Information and Knowledge Management, 2021 查看PDF
14. Hanchen Guo, Zhehan Lin, Yunfei Gu, Chentao Wu*, Li Jiang*, Jie Li, Guangtao Xue, Minyi Guo, Lazy-WL: A Wear-aware Load Balanced Data Redistribution Method for Efficient SSD Array Scaling, (CLUSTER)IEEE International Conference on Cluster Computing, 2021 查看PDF
13. Fangxin Liu, Wenbo Zhao, Zhezhi He, Zongwu Wang, Yilong Zhao, Tao Yang, Xiaoyao Liang, Naifeng Jing and Li Jiang, SME: ReRAM-based Sparse-Multiplication-Engine to Squeeze-Out Bit Sparsity of Neural Network, (ICCD)International Conference on Computer Design, 2021 查看PDF
12. Fangxin Liu, Wenbo Zhao, Zongwu Wang,Qidong Tang, Yongbiao Chen,Zhezhi He,Naifeng Jing,Xiaoyang Liang and Li Jiang, EBSP: Evolving Bit Sparsity Patterns for Hardware-Friendly Inference of Quantized Deep Neural Networks, (DAC) in ACM/IEEE Design Automation Conference, 2022 查看PDF
11. Fangxin Liu, Wenbo Zhao,Yongbiao Chen,Zongwu Wang,Zhezhi He,Rui Yang,Qidong Tang, Tao Yang,Cheng Zhuo and Li Jiang, PIM-DH: ReRAM-based Processing-in-Memory Architecture for Deep Hashing Acceleration, (DAC) in ACM/IEEE Design Automation Conference, 2022 查看PDF
10. Fangxin Liu,Wenbo Zhao, Zongwu Wang,Yongbiao Chen,Li Jiang, SpikeConverter: An Efficient Conversion Framework Zipping the Gap between Artificial Neural Networks and Spiking Neural Networks, AAAI Conference on Artificial Intelligence, 2022 查看PDF
9. Tao Yang, Dongyue Li, Zhuoran Song, Yilong Zhao, Fangxin Liu, Zongwu Wang, Zhezhi He and Li Jiang, DTQAtten: Leveraging Dynamic Token-based Quantization for Efficient Attention Architecture, (DATE)Design, Automation & Test in Europe Conference & Exhibition, 2022 查看PDF
8. Tao Yang,Dongyue Li,Fei Ma,Zhuoran Song,Yilong Zhao,Jiaxi Zhang,Fangxin Liu and Li Jiang, PASGCN: An ReRAM-Based PIM Design for GCN with Adaptively Sparsified Graphs, (TCAD)IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2022 查看PDF
7. Zongwu Wang,Zhezhi He, Rui Yang,Shiquan Fan,Jie Lin, Fangxin Liu,Yueyang Jia, Chenxi Yuan,Qidong Tang and Li Jiang, Self-Terminating Write of Multi-Level Cell ReRAM for Efficient Neuromorphic Computing, (DATE)Design, Automation & Test in Europe Conference & Exhibition, 2022 查看PDF
6. Fangxin Liu, Wenbo Zhao, Yongbiao Chen, Zongwu Wang, Tao Yang and Li Jiang, SSTDP: Supervised Spike Timing Dependent Plasticity for Efficient Spiking Neural Network Training, Frontiers in Neuroscience, section Neuromorphic Engineering, 2022 查看PDF
5. Qidong Tang, Zhezhi He, Fangxin Liu, Zongwu Wang, Yiyuan Zhou, Yinghuan Zhang, Li Jiang, HAWIS: Hardware-Aware Automated WIdth Search for Accurate, Energy-Efficient and Robust Binary Neural Network on ReRAM Dot-Product Engine, (ASP-DAC)27th Asia and South Pacific Design Automation Conference, 2022 查看PDF
4. Fangxin Liu, Wenbo Zhao, Zongwu Wang, Yongbiao Chen, Tao Yang, Zhezhi He, Xiaokang Yang and Li Jiang, SATO: Spiking Neural Network Acceleration via Temporal-Oriented Dataflow and Architecture, (DAC) in ACM/IEEE Design Automation Conference, 2022 查看PDF
3. Fangxin Liu,Haomin Li,Xiaokang Yang,Li Jiang, L3E-HD: A Framework Enabling Efficient Ensemble in High-Dimensional Space for Language Tasks, (SIGIR)International Conference on Research and Development in Information Retrieval, 2022 查看PDF
2. Fangxin Liu, Zongwu Wang,Wenbo Zhao, Yongbiao Chen, Xiaokang Yang and Li Jiang, Randomize and Match: Exploiting Irregular Sparsity for Energy Efficient Processing in SNNs, IEEE International Conference on Computer Design (ICCD), 2022 查看PDF
1. Tao Yang,Hui Ma,Xiaoling Li,Fangxin Liu,Yilong Zhao,Zhezhi He and Li Jiang, DTATrans: Leveraging Dynamic Token-basedQuantization with Accuracy Compensation Mechanism for Efficien tTranformer Architecture, IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems(TCAD), 2022 查看PDF




.jpg)