上海期智研究院PI,清华大学交叉信息研究院助理教授。
于斯坦福大学取得博士学位,导师为Leonidas J. Guibas教授,毕业后在谷歌研究院任研究科学家,与Thomas Funkhouser教授密切合作。此前在清华大学电子工程系取得了学士学位。研究兴趣涵盖3D感知,计算机图形学和具身人工智能,研究目标是使机器人代理具备理解3D世界并与之互动的能力。在CVPR,ICCV,ECCV,NeurIPS,SIGGRAPH,SIGGRAPH Asia等顶级会议发表二十余篇论文,并担任CVPR 2022领域主席。工作在领域内得到广泛关注,引用数达7500+,代表作品包括ShapeNet,光谱图CNN,PointNet++等。他创立并领导了三维视觉计算与机器智能实验室(3D VIsual Computing and machine Intelligence,简称3DVICI Lab)。该实验室致力于解决人工智能领域最前沿的通用三维视觉和具身交互问题,旨在使智能机器人具备理解三维世界并与之互动的能力。
高维计算机视觉:基于三维、四维等高维视觉数据的世界模型构建与开放世界理解
以人为中心的具身智能环境仿真:数字人智能交互行为仿真与以人为中心的具身智能仿真学习平台构建
人机交互: 基于多模态驱动的机器人与人交互任务规划与技能学习
成果13:SoFar:让机器人真正“看懂”方向(2025年度)
弋力团队提出了物体的语义方向 (Semantic Orientation) 概念:在任意几何参考系下,结合文本与物体感知输入,预测物体在交互场景中的关键方向向量。团队构建了大规模语义方向数据集 OrienText300K,通过渲染千万级多视图数据、剔除坐标未对齐样本,并使用多模态大模型进行语义标注,最终形成约 35 万条高质量训练数据。基于此,团队训练得到语义方向基础模型 PointSO。
为进一步服务机器人操作,研究者设计了系统 SoFar (Semantic Orientation for Action and Reasoning)。SoFar 展现出前所未有的泛化能力与性能,支持多类型机械臂与灵巧手操作、铰链物体操作、长程抓放任务甚至机器狗导航,并在 Simpler-Env 环境中取得 SOTA 结果。同时,团队还提出了两个全新评测基准—Open6DOR v2 与 6-DoF SpatialBench,推动空间推理与机器人操作研究的发展。

图. SoFar通过语义方向桥接空间推理和机器人操作
论文信息:
https://arxiv.org/pdf/2502.13143
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation, Zekun Qi*, Wenyao Zhang *, Yufei Ding*, Runpei Dong, XinQiang Yu, Jingwen Li, Lingyun Xu, Baoyu Li, Xialin He, Guofan Fan, Jiazhao Zhang, Jiawei He, Jiayuan Gu, Xin Jin, Kaisheng Ma, Zhizheng Zhang†, He Wang†, Li Yi†,NeurIPS 2025 Spotlight.
-----------------------------------------------------------------------------------------------------------------------------
成果12:SyncDiff:面向多主体人物-物体交互的同步运动扩散模型(2025年度)
弋力团队提出一种扩散模型SyncDiff,可以合成包含任意数量手、人体和刚体的同步多体交互动作,例如双人合作搬运箱子,或一手持镊子从另一手所持容器中夹取物品。合成此类交互的算法在具身智能体规划、动画制作、虚拟现实等领域有重要应用。不同于以往工作,SyncDiff用一个单独的扩散模型建模所有物品运动轨迹的联合分布。为保证运动的同步化,SyncDiff提出了两个创新点:首先,在传统扩散模型的data sample scores之外类比推导得到alignment scores,训练阶段加入对应的alignment loss进行监督,推理阶段则基于训练时拟合的梯度场进行联合最大化似然采样。其次,SyncDiff利用快速傅里叶变换(FFT)将运动信号分解为高频与低频分量,对高频分量在频率域进行建模,并对二者分别加以监督。
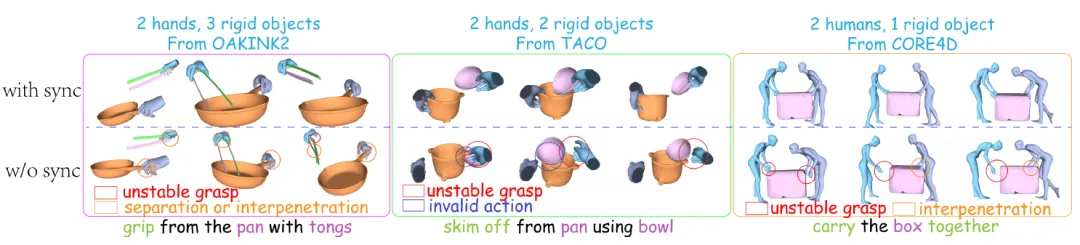
图. SyncDiff使用统一框架,合成包含任意数量手、人体和刚体的同步多体交互动作
论文信息:
https://arxiv.org/pdf/2412.20104
SyncDiff: Synchronized Motion Diffusion for Multi-Body Human-Object Interaction Synthesis, Wenkun He, Yun Liu, Ruitao Liu, Li Yi†,ICCV 2025.
------------------------------------------------------------------------------------------------------------------------------
成果11:一种基于双线程系统的4D流式全景分割方法(2025年度)
弋力团队提出4DSegStreamer系统,为了实现对动态环境的全面理解,通过创新的架构设计实现高效的流式4D全景分割。该系统采用双线程架构:预测线程通过利用历史运动和几何特征来预测未来动态,负责维护和更新场景的几何与运动记忆,从而实现长期时空感知;推理线程通过预测运动与几何对齐从记忆中检索相关特征,专注于实时推理,从而确保在严格的时间约束内输出结果。
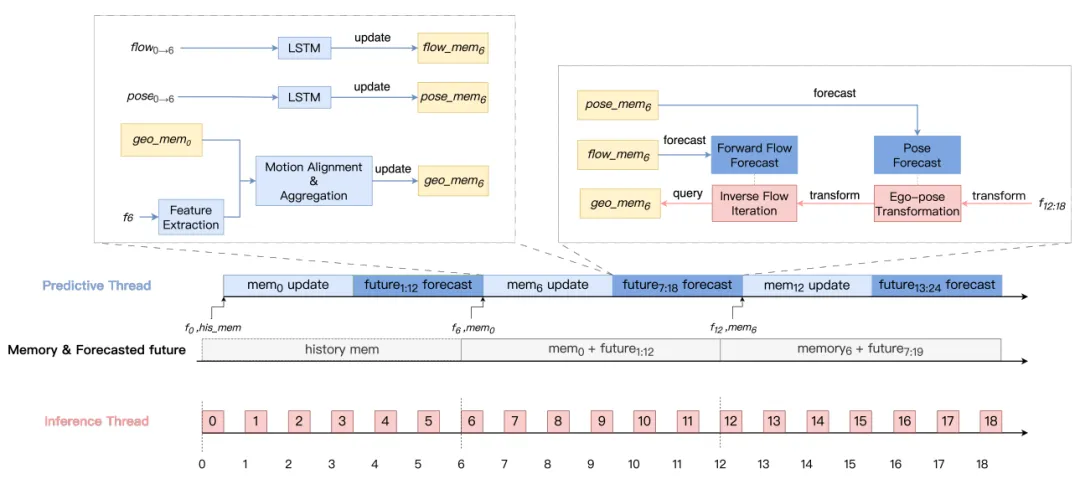
图. 4DSegStreamer:该双线程系统由预测线程与推理线程构成,可实现对未来未观测帧的实时查询
论文信息:
https://arxiv.org/pdf/2510.17664
4DSegStreamer: Streaming 4D Panoptic Segmentation via Dual Threads, Ling Liu*, Jun Tian*, Li Yi†,ICCV 2025.
------------------------------------------------------------------------------------------------------------------------------
成果10:基于行走数据的通用人体交互动作生成:少数据、高灵活的生成新范式(2025年度)
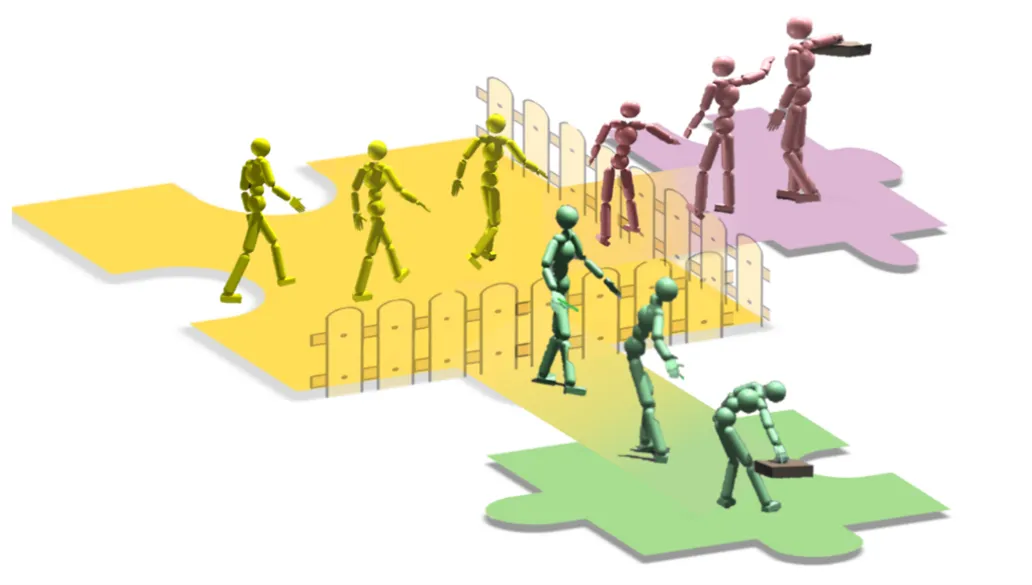
图. 基于简短行走参考的人体全身操作技能生成框架示意图
在人类与物理世界的互动中,和物体的交互性的动作扮演着核心角色。生成真实可信、基于物理的全身人体抓取动作,不仅对于动画、AR/VR等应用具有重要意义,也为具身智能体如仿人机器人带来了巨大潜力。
以往的研究多数依赖大规模的运动捕捉(MoCap)数据,通过对这些数据的模仿或跟踪生成动作,尽管质量较高,但难以脱离数据分布进行泛化。而复杂场景下的操控技能具有高度多样性,数据采集成本高、样本分布偏倚严重,使得通用性受限。
为此,弋力团队提出一种新颖的人体操控动作生成方法:仅使用少量简单的行走运动捕捉数据,即可生成多样且物理可行的全身抓取和操控动作。尽管“行走”和“抓取”在语义上差异巨大,但我们发现行走数据中蕴含着丰富的局部运动模式和身体平衡能力,具有很强的迁移性。同时,先进的运动学技术也可提供高质量的目标抓取姿态,尽管这些姿态没有物理保障,但可作为有效的任务引导。

图. 多种复杂场景和未知物体上的动作生成
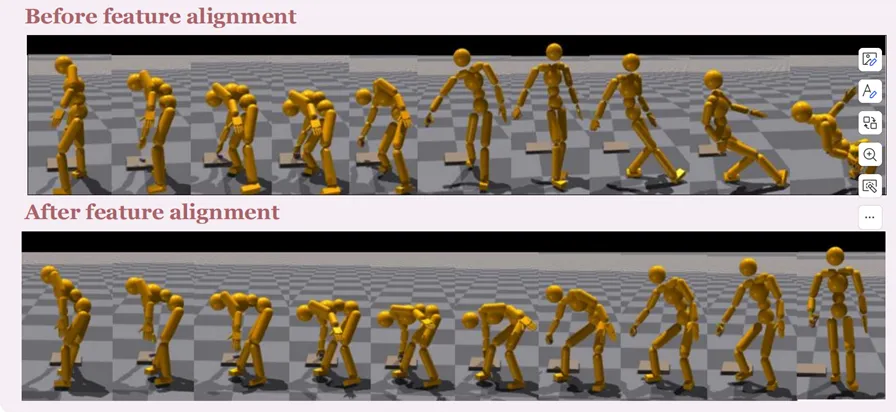
图.局部运动模式能有效提升动作质量,动作稳定性
该工作提出了一个基于有限行走数据生成多样人体交互动作的通用框架,并通过主动生成与特征对齐机制成功融合真实与合成数据,展现出优异的效果与鲁棒性,为低资源环境下的人体运动生成提供了新思路。
------------------------------------------------------------------------------------------------------------------------------
成果9:面向通用灵巧操作技能的通用轨迹跟踪器—DexTrack(2025年度)
赋予机器人以像人一样的灵巧操控的技能是通往未来终极具身智能的重要一步。如何让一个具身智能体获得广泛的灵巧操控技能一直是具身智能领域的一个重要的问题。灵巧操控任务复杂且多样,之前很多工作大多专注在特定技能的获取(如抓取或者在手里转动)。他们大多需要对单独的任务进行针对性的设计,例如专门对某一种特定的任务设计对应的奖励函数,之后根据这样的奖励函数训练策略网络来解决对应的问题。这些难以迁移到不一样的任务上的奖励函数设计是通往通用操控技能的一个阻力。所以为了实现通用的灵巧操控技能,团队首先需要任务表示层面的统一。此外,灵巧操控技能涉及到复杂的和随时间变化的手-物接触,复杂的物体运动轨迹。再考虑到对使用一个操控策略解决不同类型的操控任务的需求,得到一个通用的灵巧操控智能体对算法本身的设计也提出了很大的挑战。

图. DexTrack: 通用灵巧操作轨迹跟踪器
为了实现这一目标,团队将运动规划以及控制的问题拆解开来,将不同种的灵巧操控技能重新统一到一个轨迹跟踪控制的框架下,进一步借助于大量的人类操控物体的数据作为跟踪的目标,通过学习一个通用的轨迹跟踪控制器,来一定程度上解决这个问题。
团队将不同类型的操控任务统一到一个轨迹跟踪任务来完成任务表示层面的统一。在每一个时刻,给定机器手和物体当前的状态,以及下一步想要达到的状态,轨迹跟踪控制器的任务是给出机器手当前应该执行的动作,从而通过执行该动作,机器手可以运动且和物体进行交互,使得机器手以及物体实际达到的状态与下一步想要达到的状态相吻合。这样的表示方式对不同的操控任务是比较适配的。基于这一任务表示,团队通过训练一个通用的灵巧操控轨迹跟踪器来解决通用灵巧操控的问题。一个通用的轨迹跟踪需要可以响应各种各样的轨迹跟踪命令。这一多样的轨迹空间对该轨迹跟踪器的学习提出了更高的挑战。团队提出了一个将RL和IL结合起来的方法,在RL训练的同时引入监督信号来降低policy学习的难度。通过交替地使用高质量的轨迹跟踪数据辅助通用轨迹跟踪控制器的学习,以及借助通用轨迹跟踪器来提高单一轨迹跟踪演示的质量,团队可以逐渐得到一个强大的可以跟踪各种各样轨迹的控制器。

图. 通用轨迹跟踪器的训练方法
团队的方法在极具挑战性的任务上达到了令人瞩目的效果。同时团队也进行了大量的真机实验来验证它在真实世界中的可行性。团队的机器手可以转动并尝试“安装”一个灯泡。在工具使用方面,团队也可以在手中调整一个刀使得刀可以刀刃向下来切东西,可以在手中转动一个锤子,并使用正确的朝向来锤东西。
------------------------------------------------------------------------------------------------------------------------------
成果8:仅从二维图像中学习开放词汇点云的三维目标检测—ImOV3D(2024年度)

在三维视觉领域,开放词汇三维目标检测正受到越来越多的关注。该任务旨在推理阶段时,可以检测到那些在训练阶段未出现的物体类别。在现实世界的动态环境中,目标类别不断出现和变化,这种能力至关重要。尽管开放词汇三维目标检测取得了一定进展,但该领域的三维数据和标注资源仍然稀缺,限制了模型处理新颖目标的能力。
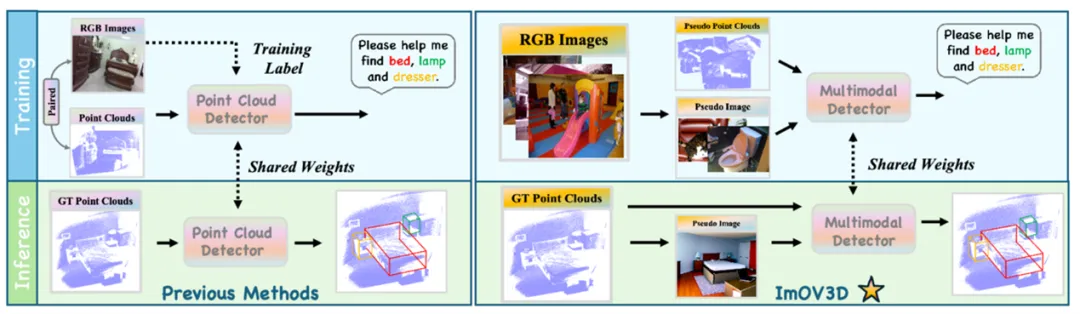
图1. ImOV3D和其他方法对比
现有方法通常借助强大的开放词汇二维检测器。一个常见的方法是利用配对的RGB-D数据二维检测器生成三维伪标注以解决标注稀缺问题。然而,这些方法仍受到现有配对RGB-D数据规模较小的限制。此外,由于模态差异,从头训练的三维检测器很难直接继承开放词汇二维检测器的强大能力。因此,如何更有效地将二维知识转移到三维以支持开放词汇三维目标检测,并有效缓解三维数据少的问题?
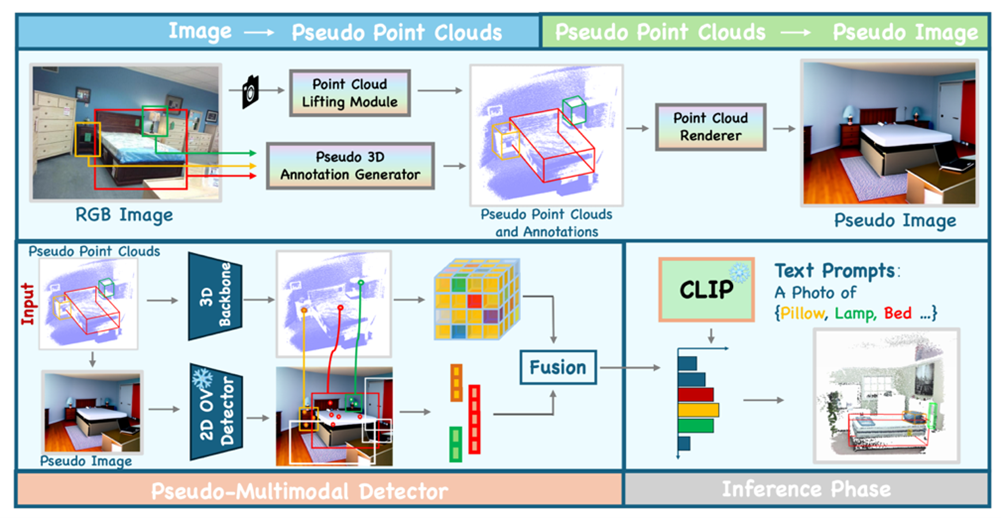
弋力团队提出ImOV3D,利用伪多模态表示来解决上述挑战。一方面,通过深度估计和相机矩阵将二维图像提升为伪三维表示;另一方面,可以通过渲染将三维点云转换为伪二维表示。这种伪图像-点云多模态表示可以作为二维到三维知识转移的共同基础。
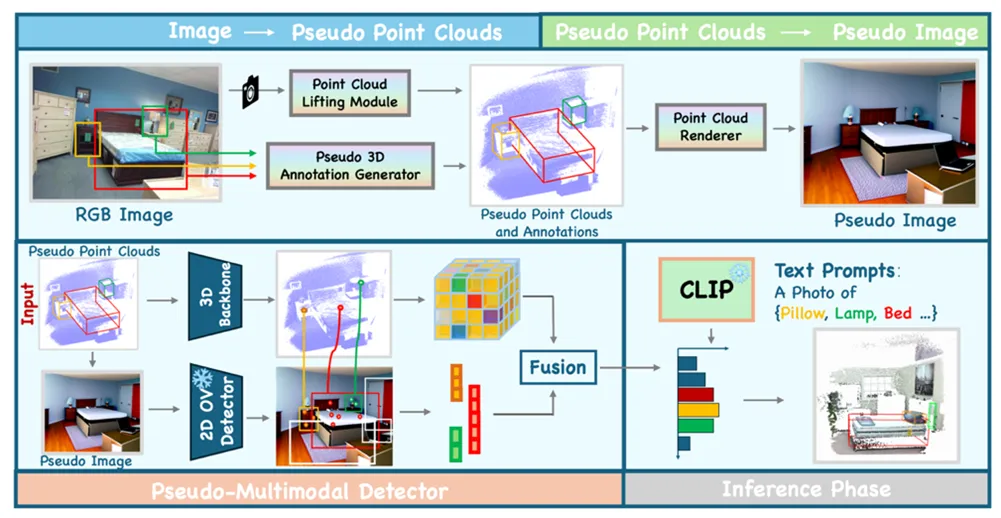
图2. ImOV3D概述图
具体来说,整个流程包括两部分:
(1) 图像 → 伪点云。团队利用大规模的二维图像训练集,通过单目深度估计和近似相机参数,将图像转换为伪点云,并基于二维标注自动生成伪三维标注,提供必要的训练数据。同时,团队设计了一系列修正模块,通过尺寸先验和法线图的估计方向显著提高伪三维数据的质量。
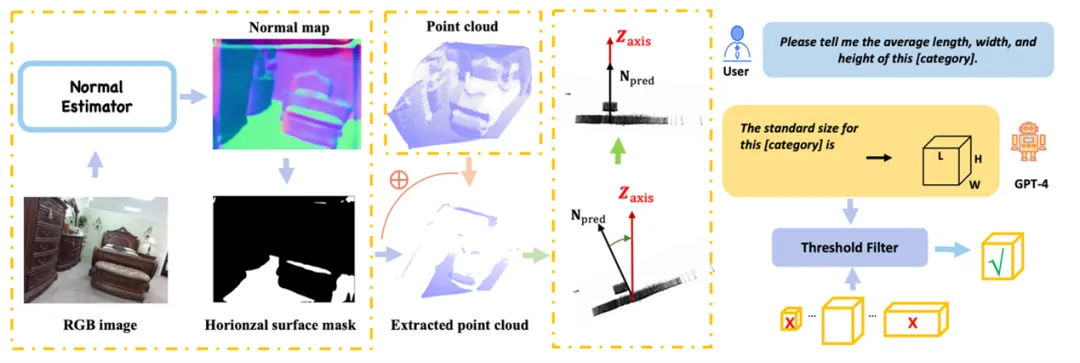
图3. 伪三维数据修正模块
(2) 伪点云 → 伪图像。团队学习了一个点云渲染器,能够从伪三维点云生成具有自然纹理的二维图像。这使得ImOV3D即使在推理阶段只有点云输入的情况下,仍能利用伪多模态三维目标检测,将丰富的二维语义信息和提案转移到三维空间,从而进一步提升检测器的性能。
尽管仅使用二维图像集进行训练,ImOV3D在直接处理真实三维测试数据时仍表现出色,这得益于高质量的点云提升和点云渲染。此外,当少量真实三维数据可用时,即使没有三维标注,ImOV3D也能通过微调进一步缩小伪数据和真实数据之间的差距,从而提升检测性能。为了验证ImOV3D的有效性,团队在两个基准数据集上进行了广泛实验。在没有真实三维训练数据的情况下,ImOV3D相比以往的开放词汇三维目标检测器,分别在两个数据集上实现了显著的性能提升。
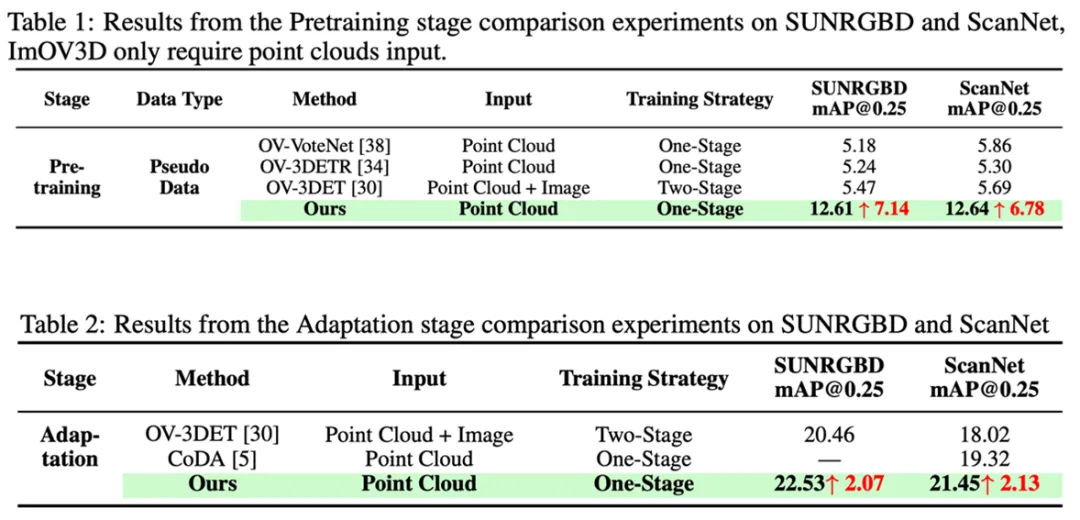
图4. 预训练阶段和适应阶段在SUNRGBD和ScanNet数据集上表现最好
ImOV3D展示了利用二维图像提升开放词汇三维目标检测的潜力,为未来在伪多模态数据生成及其在三维检测方法中的应用开辟了新方向。本论文共同一作为上海期智研究院实习生杨题鸣、学士后鞠沅良,通讯作者为上海期智研究院PI、清华大学助理教授弋力。
论文信息:ImOV3D: Learning Open-Vocabulary Point Clouds 3D Object Detection from Only 2D Images, Timing Yang*, Yuanliang Ju*, Li Yi†, https://yangtiming.github.io/ImOV3D_Page/, NeurIPS 2024.
------------------------------------------------------------------------------------------------------------------------------
成果7:通过准物理模拟器来解决复杂灵巧操作迁移问题—QuasiSim(2024年度)
提升具身智能体与世界交互的能力是实现通用人工智能的重要一步。由于设置真实机器人在真实世界中进行反复试验的成本高昂且存在潜在危险,开发具身算法的标准方法一般是先在物理模拟器中学习,然后通过模拟到真实的技术迁移到真实世界。在大多数情况下,物理模拟器被视为黑匣子,人们已经投入了大量精力来开发这些黑匣子中具身技能的学习和优化方法。尽管取得了长足的进步, 但很少讨论所使用的模拟器是否最合适的问题。
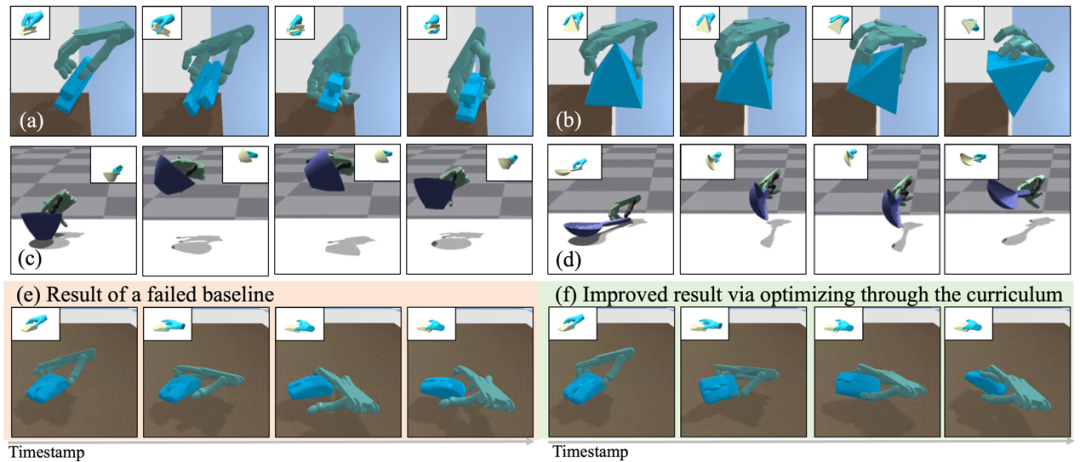
图1. QuasiSim—通过准物理模拟器来解决复杂灵巧操作迁移问题
弋力团队研究了这个问题,并说明了如何在技能习得的同时优化模拟器,可以使机器人操作中一项流行但具有挑战性的任务—灵巧操作迁移受益。QuasiSim提出了一系列参数化的准物理模拟器 (Quasi-Physical Simulators),用于手-物接触丰富的灵巧操作任务。这些模拟器可以定制以增强任务的可优化性,同时也可以定制以近似真实物理。参数化模拟器将铰接式多刚体表示为参数化点集,使用不受约束的参数化弹簧阻尼器对接触进行建模,并通过参数化的残差物理补偿未建模的影响。
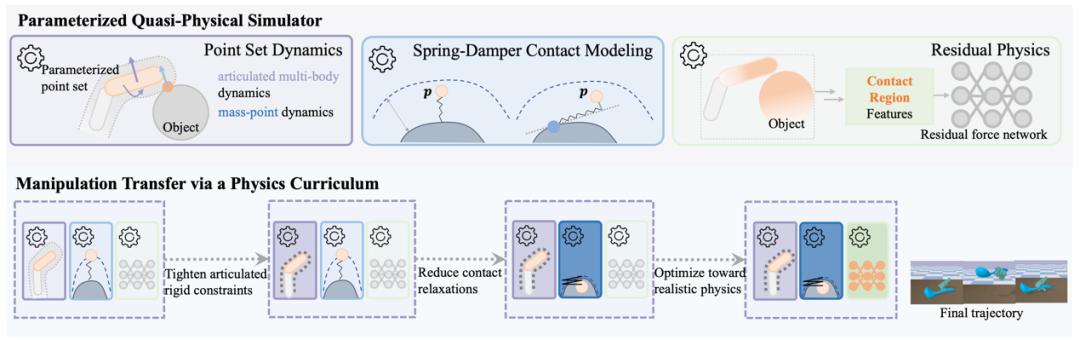
图2. 参数化的准物理模拟器
在优化过程中,模拟器中铰接刚性约束和接触模型刚度都在最开始的阶段被完全放松。它可能无法反映物理真实性,但提供了一个良好的环境,可以轻松解决操作迁移的问题。随后,我们逐渐收紧铰接刚性约束和接触模型。任务解决在这个课程中的每个模拟器中迭代进行。最后,我们优化参数化的模拟器以近似真实的物理。任务优化继续进行,产生能够在具有真实物理的环境中执行操作的灵巧手轨迹。
团队在两个广受欢迎的模拟器,PyBullet和Isaac Gym中验证了该方法的有效性。我们可以跟踪涉及非平凡物体运动(例如大旋转)和复杂工具使用(例如使用勺子来回搅水)的复杂操作。该方法在数量和质量上都成功超越了之前表现最佳的方法,成功率比之前表现最佳的方法高出 11% 以上。
QuasiSim有潜力加速机器人灵巧操作技能的发展。相关成果收录于2024 ECCV中。本论文一作为上海期智研究院实习生、清华大学博士生刘雪怡,通讯作者为弋力助理教授。共同作者为清华大学博士生吕康博,清华大学本科生张洁琼,上海期智研究院PI、清华大学助理教授杜韬。
论文信息:QuasiSim: Quasi-Physical Simulators for Dexterous Manipulations Transfer, Xueyi Liu, Kangbo Lyu, Jieqiong Zhang, Tao Du, Li Yi†, https://meowuu7.github.io/QuasiSim/, ECCV 2024.
------------------------------------------------------------------------------------------------------------------------------
成果6:创建首个大规模双手协作双物体的数据集—TACO(2024年度)
手物交互动作的理解与生成是虚拟/增强现实、机器人灵巧手操作和人机协作等领域的一个重要的基础课题。先前的技术方法大多关注单一物体的抓取和操作,而忽视了日常生活中更为常见的多物体协作,这归咎于相关的数据集和基准任务的不足。为了支持研究手物交互场景中不同物体的协作,弋力团队构建了首个大规模的双手使用工具实现双物体协作的四维数据集—TACO。TACO数据集的创建和相应的基准测试任务的提出,为计算机视觉领域中的手部-物体交互理解与合成的研究提供了新的视角和挑战,推动了该领域向更高层次的泛化性和智能化发展。
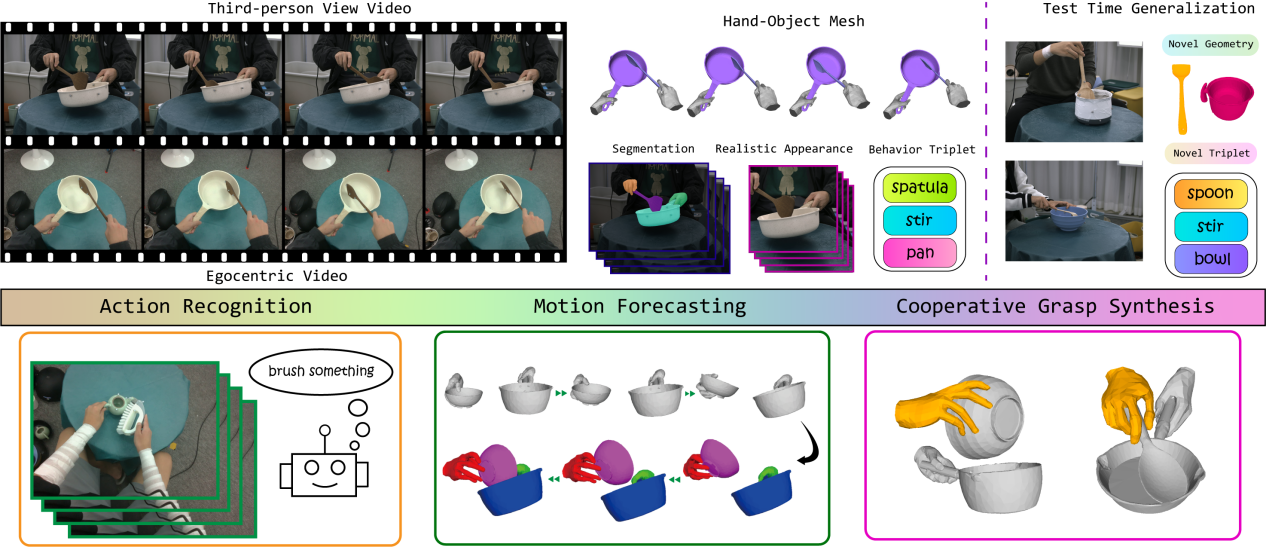
图1. TACO数据集
1)TACO数据集涵盖了日常生活中人们用双手使用工具完成任务的动作,将手物交互行为刻画成<工具-动作-使用对象>的交互三元组。提供了丰富的工具使用和物体操作的多样性,支持在测试时对未见物体几何形状和新的行为三元组进行泛化。涵盖了5.2M张来自第一和第三人称视角的彩色图片、2.5K段交互动作、131种“工具-动作-使用对象”的组合和196种物体形状。TACO关注数据内容包含第一和第三人称视角下的彩色视频、手和物体的三维网格序列、手和物体的二维掩码以及去除标志点的图片。
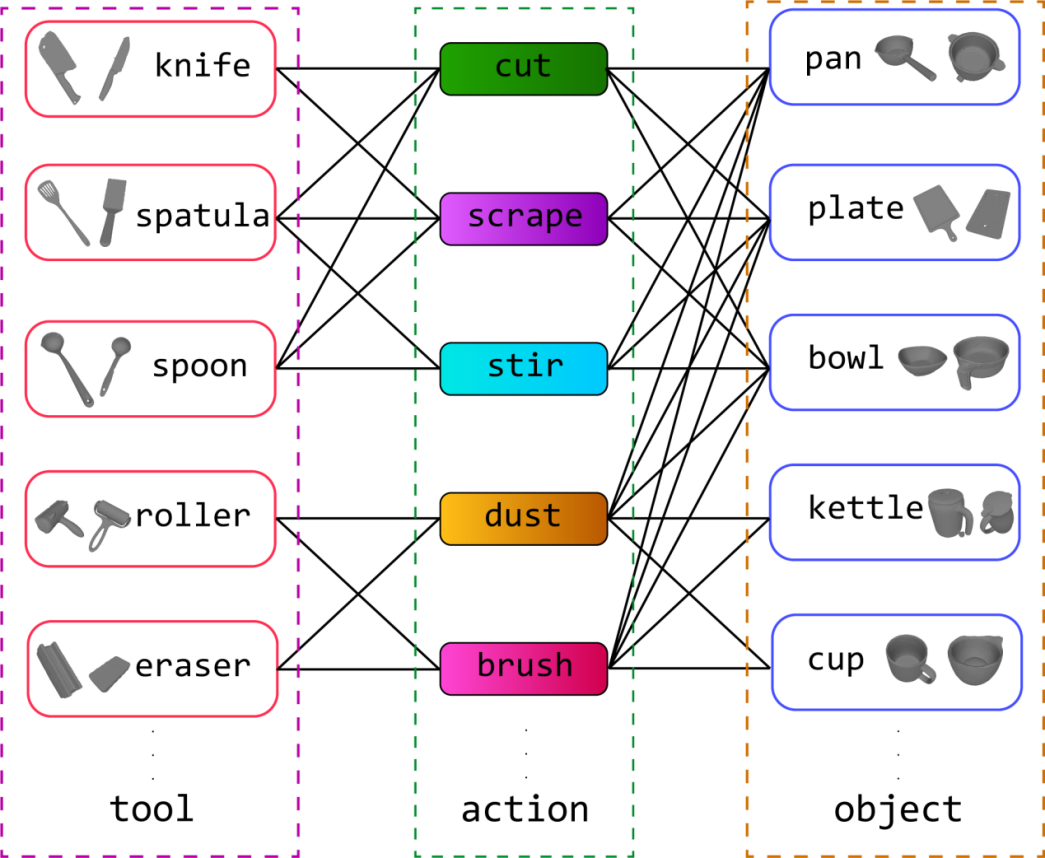
图2. TACO数据集中的交互三元组示例
2)为了快速扩大数据规模,该工作贡献了一种基于彩色视频和光学动捕系统的全自动数据标注算法。这一流程能够同时保证运动质量和视觉数据质量,并为每个时间步自动提供标签,包括在无标记视觉数据上的精确手部-物体网格恢复和分割。
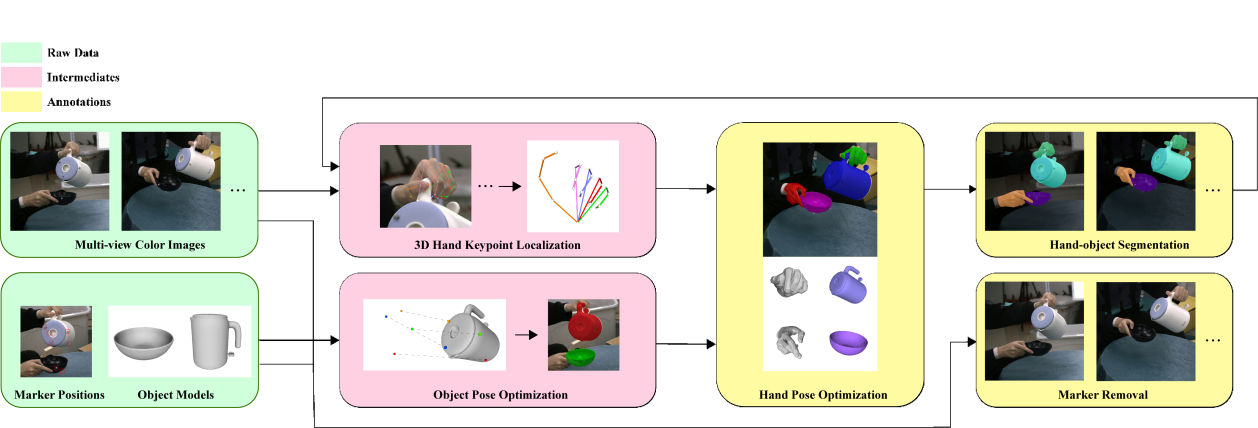
图3. 自动数据标注流程
3)在TACO数据集开拓的广阔研究空间中,团队提出了三个研究双物体协同操作的基准任务:动作识别、动作预测和合作式抓取生成,并关注现有的技术方法在物体形状和交互三元组等方面的泛化能力。三个基准任务中的大量实验表明现有方法在跨三元组的动作理解和在新物体、新类别上的抓取生成等方面尚存较大的提升空间,这为今后的研究带来了新的挑战和机遇。
TACO: Benchmarking Generalizable Bimanual Tool-ACtion-Object Understanding, Yun Liu, Haolin Yang, Xu Si, Ling Liu, Zipeng Li, Yuxiang Zhang, Yebin Liu, Li Yi, https://arxiv.org/pdf/2401.08399, CVPR 2024.
------------------------------------------------------------------------------------------------------------------------------
成果5:自监督学习&多模态数据融合 —CrossVideo & TEG-Track(2024年度)
弋力团队在机器人视觉与触觉感知领域研究中取得重要进展,通过自监督学习和多模态数据融合来提升机器人对环境的理解和交互能力,在ICRA 2024上发表2项成果。提出了一种自监督的跨模态对比学习方法CrossVideo,通过模态内和跨模态的对比学习技术,提高点云视频理解的性能。团队提出了一种触觉增强的6D姿态跟踪系统TEG-Track,用于跟踪手中持有的未见过的物体。该方法在合成和真实世界场景中均能一致性地提升最先进的通用6D姿态跟踪器的性能。相关成果可运用推广到机器人导航、增强现实、自动化驾驶等领域。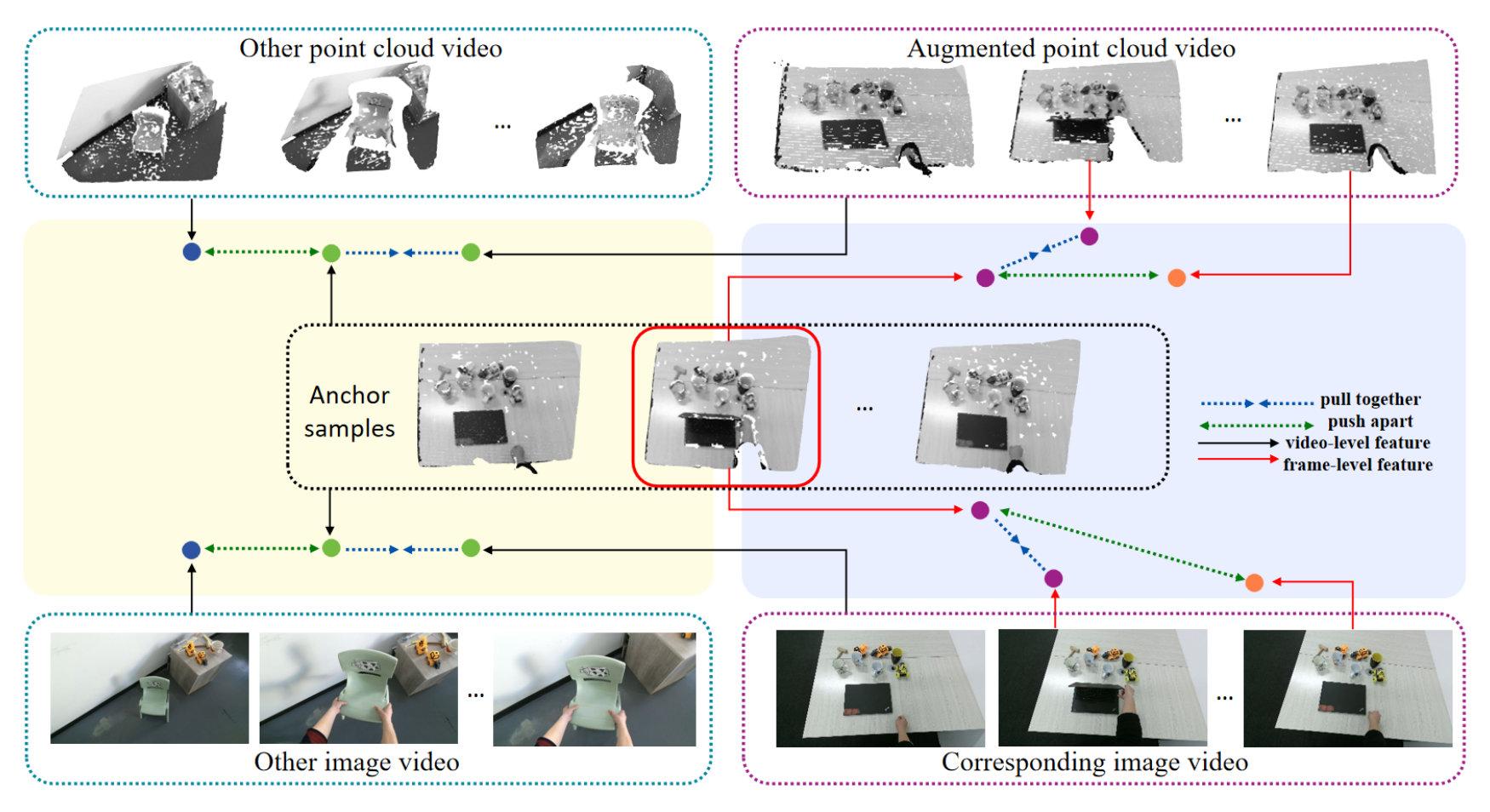
论文信息:CrossVideo: Self-supervised Cross-modal Contrastive Learning for Point Cloud Video Understanding,Yunze Liu, Changxi Chen, Zifan Wang, Li Yi,https://arxiv.org/abs/2401.09057
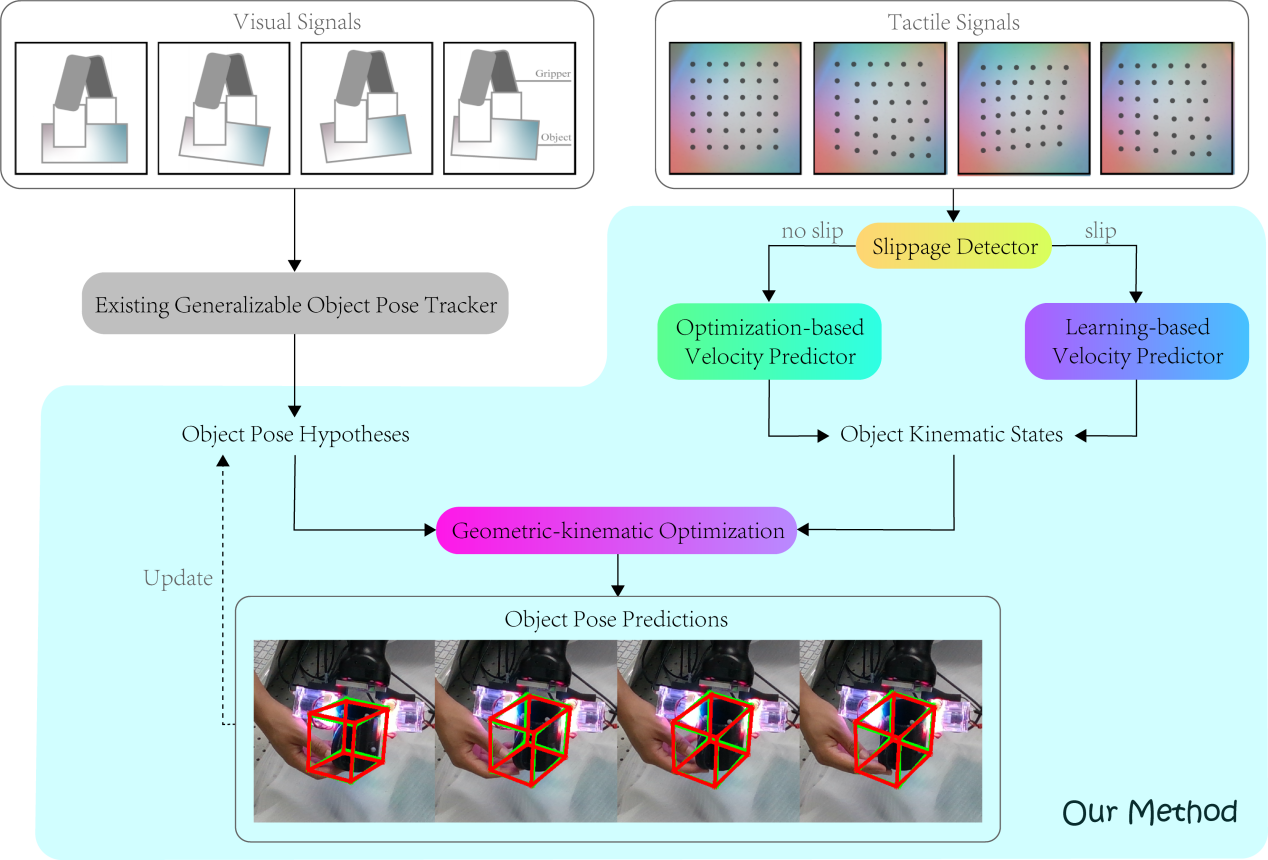
论文信息:CrossVideo: Self-supervised Cross-modal Contrastive Learning for Point Cloud Video Understanding,Yun Liu*, Xiaomeng Xu*, Weihang Chen, Haocheng Yuan, He Wang, Jing Xu, Rui Chen, Li Yi,https://github.com/leolyliu/TEG-Track
------------------------------------------------------------------------------------------------------------------------------
成果4:多模态大模型框架DREAMLLM&
通用泛化的手物交互算法GeneOH Diffusion(2024年度)
弋力团队提出了多模态大型语言学习框架DREAMLLM,首次实现了兼具多模态内容创作和理解的功能且相互促进的通用多模态大模型,并且是第一个原始数据级的完全自回归多模态大模型。该工作由弋力团队与清华大学马恺声老师团队合作完成。
该团队还提出了一套通用泛化的手物交互去噪算法GeneOH Diffusion,用于处理手-物交互(HOI)中的去噪问题。该方法通过创新的基于接触的HOI表示GeneOH和一个新的领域泛化去噪方案来解决复杂的交互噪声问题。GeneOH Diffusion在多个基准测试中展示了其优越的有效性和泛化能力,对各种下游应用也显示出了潜力。

论文信息:DreamLLM: Synergistic Multimodal Comprehension and Creation,Runpei Dong*, Cunrui Han*, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, Xiangwen Kong, Xiangyu Zhang, Kaisheng Ma, Li Yi,https://dreamllm.github.io/
论文信息:GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion. Xueyi Liu, Li Yi,https://meowuu7.github.io/GeneOH-Diffusion/
------------------------------------------------------------------------------------------------------------------------------
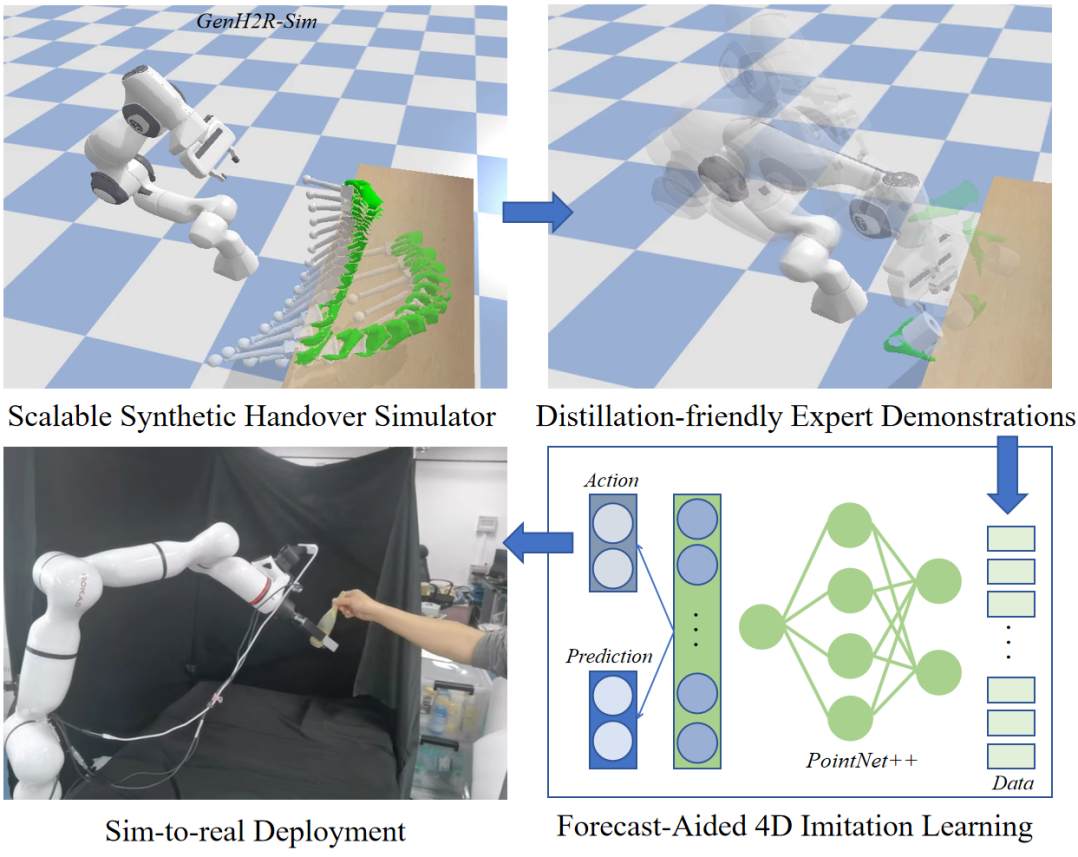
成果3:从可扩展的仿真、示例生成中模仿学习通用人机交接(2023年度)
在以人为中心的具身智能研究中,通用人机交接(Generalizable Human-to-Robot Handover)是一个关键的技能,它使机器人能够更好地与人类合作。受大数据+大算力所驱动的大模型启发,弋力团队验证了“海量高质量数据+大规模模仿学习”走向通用智能的方式,提出了GenH2R框架,分别从仿真、示例生成、模仿学习三个角度出发,让机器人第一次基于端到端的方式学习对任意抓取方式、任意交接轨迹、任意物体几何的通用交接。GenH2R模拟了百万级别人在不同交接任务中的行为,使得在虚拟场景中的技能学习成为可能。为了解决示例数据稀缺的问题,同时保证示例数据对于技能学习的有效性,GenH2R以视觉观测与行动的相关性作为核心优化目标提出了一套动态抓取与运动规划方法,自动生成大规模示例数据,使得通过简单的模仿学习就可以获取通用的人机交接技能。相比于之前最优的人机交接方法,GenH2R的方法在各种测试集上平均成功率提升14%,时间上缩短13%,并在真机实验中取得更加鲁棒的效果。

研究领域:基于高维视觉的可泛化人机协作
研究论文:Zifan Wang*, Junyu Chen*, Ziqing Chen, Pengwei Xie, Rui Chen, Li Yi. GenH2R: Learning Generalizable Human-to-Robot Handover via Scalable Simulation, Demonstration, and Imitation. In submission. 查看PDF
------------------------------------------------------------------------------------------------------------------------------
成果2:基于标准化交互空间的类别级手物功能性操控生成(2023年度)
长期以来,人类灵巧手与物体的交互问题受到机器人、三维视觉、图形学社区的高度关注。给定特定类别(如剪刀)下的一个物体示例以及操作目标,弋力团队希望能生成一段与之匹配的人类灵巧手操作动画,其中要求生成出的动画应接近人类操作方式,且物理真实。现有方法局限性相对较大,具体体现在训练数据采集困难,对形状泛化性不佳等。为此,弋力团队提出了标准化交互空间CAMS (CAnonicalized Manipulation Spaces)用以表示手物交互,其通过提取手与物体的接触点、建立以接触为中心的手指嵌入特征,来实现局部交互与物体全局形状的解耦,使得交互生成具有更强的跨物体泛化性。基于CAMS表示,弋力团队提出了一套采用条件变分自编码器结构的手物交互动画生成框架。得益于CAMS表示的标准化特性,在同一物体类别下动作表示对具体物体形状的依赖性大大降低,因此类内跨物体泛化性大大提升。实验表明,对于已知类别内任意给定的目标形状,该方法均能生成出物理真实且类人的交互动画,而此前的工作对于训练数据中并未见过的形状存在较大的泛化问题。
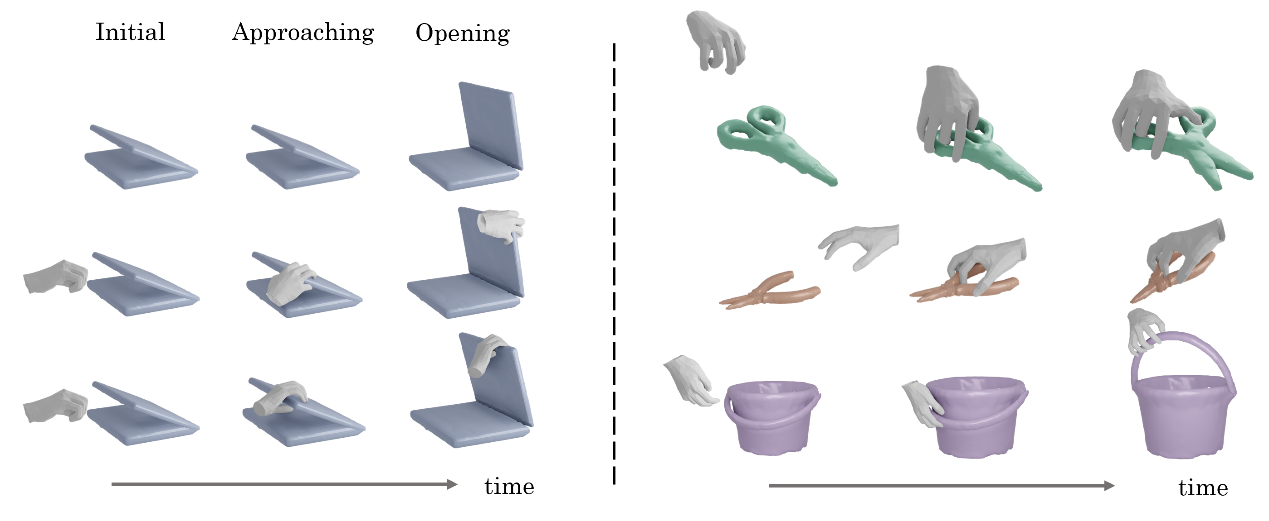
研究领域:数字人交互仿真
项目网站:https://cams-hoi.github.io/
研究论文:Juntian Zheng*, Lixing Fang*, Qingyuan Zheng*, Yun Liu, Li Yi. CAMS: CAnonicalized Manipulation Spaces for Category-Level Functional Hand-Object Manipulation Synthesis. CVPR 2023. 查看PDF
------------------------------------------------------------------------------------------------------------------------------
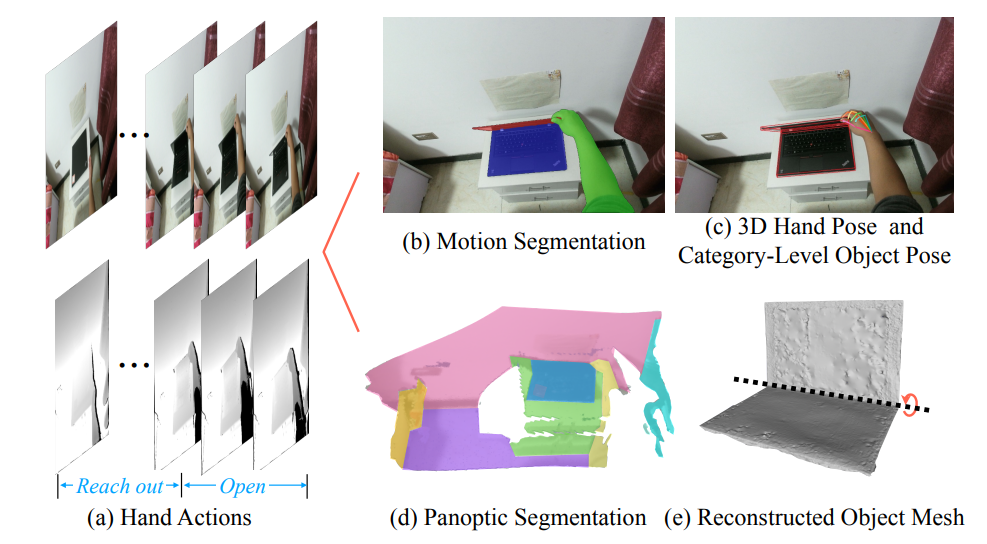
成果1:第一人称视角的类别级人-物交互的4D数据集(2022年度)
得益于大量数据集和基准任务的提出,如何在图片、视频和点云中感知物体和人类活动这一问题已经取得了显著的成果。但是,随着机器人行业的快速发展和元宇宙的兴起,仅对上述数据类型进行感知已经无法满足行业的需求。机器人和VR/AR设备可以产生大量的4D数据(第一人称下的彩色点云序列),AI系统需要从中理解语义信息、手和物体的位姿信息、物体的功能性以及人手动作的类别等,这都是非常具有挑战性的开放问题。弋力团队提出了第一个大规模第一人称类别级人-物体交互4D数据集HOI4D。 数据集包括了4个采集者采集的4000段点云视频(总计2.4M帧点云), 16个类别总计800个物体实例。
HOI4D数据集提供了用于全景分割、运动分割、3D手部位姿、类别级物体位姿和手部动作的逐帧注释,以及物体CAD模型和重建场景点云。该工作还建立了三个基准任务来促进4D类别级人-物体交互的发展,包括4D动态点云序列的语义分割、类别级物体位姿跟踪和第一人称的细粒度视频动作分割。此研究可以支持大量的新兴研究方向,如4D场景理解、类别级人-物体交互、动态场景重建等,对人-物体交互领域的发展具有重要推动作用。

弋力 成果收录于NeurIPS 2024
弋力 成果收录于ECCV 2024

弋力 成果收录于CVPR 2024
弋力 成果收录于CVPR 2024

弋力 成果收录于ICRA 2024

弋力 成果收录于ICLR 2024




30. 4DSegStreamer: Streaming 4D Panoptic Segmentation via Dual Threads, Ling Liu*, Jun Tian*, Li Yi†,ICCV 2025.
29. SyncDiff: Synchronized Motion Diffusion for Multi-Body Human-Object Interaction Synthesis, Wenkun He, Yun Liu, Ruitao Liu, Li Yi†,ICCV 2025.
28. SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation, Zekun Qi*, Wenyao Zhang *, Yufei Ding*, Runpei Dong, XinQiang Yu, Jingwen Li, Lingyun Xu, Baoyu Li, Xialin He, Guofan Fan, Jiazhao Zhang, Jiawei He, Jiayuan Gu, Xin Jin, Kaisheng Ma, Zhizheng Zhang†, He Wang†, Li Yi†,NeurIPS 2025 Spotlight.
27. ImOV3D: Learning Open-Vocabulary Point Clouds 3D Object Detection from Only 2D Images, Timing Yang*, Yuanliang Ju*, Li Yi†, https://yangtiming.github.io/ImOV3D_Page/, NeurIPS 2024.
26. QuasiSim: Quasi-Physical Simulators for Dexterous Manipulations Transfer, Xueyi Liu, Kangbo Lyu, Jieqiong Zhang, Tao Du, Li Yi†, https://meowuu7.github.io/QuasiSim/, ECCV 2024.
25. FreeMotion: MoCap-Free Human Motion Synthesis with Multimodal Large Language Models, Zhikai Zhang, Yitang Li, Haofeng Huang, Mingxian Lin, Li Yi†, https://zzk273.github.io/freemotion/, ECCV 2024.
24. ShapeLLM: Universal 3D Object Understanding for Embodied Interaction,Zekun Qi, Runpei Dong, Shaochen Zhang, Haoran Geng, Chunrui Han, Zheng Ge, Li Yi† and Kaisheng Ma†,https://qizekun.github.io/shapellm/, ECCV 2024
23. TACO: Benchmarking Generalizable Bimanual Tool-ACtion-Object Understanding, Yun Liu, Haolin Yang, Xu Si, Ling Liu, Zipeng Li, Yuxiang Zhang, Yebin Liu, Li Yi, https://arxiv.org/pdf/2401.08399, CVPR 2024.
22. Physic-aware Hand-Object Interaction Denoising, Haowen Luo, Yunze Liu, Li Yi, https://arxiv.org/pdf/2405.11481, CVPR 2024.
21. GenH2R: Learning Generalizable Human-to-Robot Handover via Scalable Simulation, Demonstration, and Imitation,Zifan Wang*, Junyu Chen*, Ziqing Chen, Pengwei Xie, Rui Chen, Li Yi†,https://GenH2R.github.io, CVPR 2024.
20. GenN2N: Generative NeRF2NeRF Translation, Xiangyue Liu, Han Xue, Kunming Luo, Ping Tan, Li Yi, https://xiangyueliu.github.io/GenN2N/, CVPR 2024.
19. Yun Liu*, Xiaomeng Xu*, Weihang Chen, Haocheng Yuan, He Wang, Jing Xu, Rui Chen, Li Yi, CrossVideo: Self-supervised Cross-modal Contrastive Learning for Point Cloud Video Understanding, ICRA 2024
18. Runpei Dong*, Cunrui Han*, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, Xiangwen Kong, Xiangyu Zhang, Kaisheng Ma, Li Yi, DreamLLM: Synergistic Multimodal Comprehension and Creation, ICLR 2024
17. Xueyi Liu, Li Yi, GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion. ICLR 2024
16. Junbo Zhang, Guofan Fan, Guanghan Wang, Zhengyuan Su, Kaisheng Ma, Li Yi, Language-Assisted 3D Feature Learning for Semantic Scene Understanding, Association for the Advancement of Artificial Intelligence (AAAI), 2023 查看PDF
15. Runpei Dong, Zekun Qi, Linfeng Zhang, Junbo Zhang, Jianjian Sun, Zheng Ge, Li Yi†, Kaisheng Ma†, Autoencoders as Cross-Modal Teachers: Can Pretrained 2D Image Transformers Help 3D Representation Learning?, International Conference on Learning Representation (ICLR), 2023 查看PDF
14. Xueyi Liu, Ji Zhang, Ruizhen Hu, Haibin Huang, He Wang, Li Yi, Self-Supervised Category-Level Articulated Object Pose Estimation with Part-Level SE(3) Equivariance, International Conference on Learning Representation (ICLR), 2023 查看PDF
13. Xuanyao Chen, Zhijian Liu, Haotian Tang, Li Yi, Hang Zhao, Song Han, SparseViT: Revisiting Activation Sparsity for, Conference on Computer Vision and Pattern Recognition (CVPR), 2023 查看PDF
12. Xiaomeng Xu, Yanchao Yang, Kaichun Mo, Boxiao Pan, Li Yi, Leonidas J. Guibas, JacobiNeRF: NeRF Shaping with Mutual Information Gradients, Conference on Computer Vision and Pattern Recognition (CVPR), 2023 查看PDF
11. Juntian Zheng, Lixing Fang, Qingyuan Zheng, Yun Liu, Li Yi, CAMS: CAnonicalized Manipulation Spaces for Category-Level Functional Hand-Object Manipulation Synthesis, Conference on Computer Vision and Pattern Recognition (CVPR), 2023 查看PDF
10. Zhuoyang Zhang, Yuhao Dong, Yunze Liu, Li Yi, Complete-to-Partial 4D Distillation for Self-Supervised Point Cloud Sequence Representation Learning, Conference on Computer Vision and Pattern Recognition (CVPR), 2023 查看PDF
9. Zekun Qi, Runpei Dong, Guofan Fan, Zheng Ge, Xiangyu Zhang, Kaisheng Ma, Li Yi, Contrast with Reconstruct: Contrastive 3D Representation Learning Guided by Generative Pretraining, International Conference on Machine Learning (ICML), 2023 查看PDF
8. Xueyi Liu, Bin Wang, He Wang, Li Yi, Few-Shot Physically-Aware Articulated Mesh Generation via Hierarchical Deformation, International Conference on Computer Vision (ICCV), 2023 查看PDF
7. Yunze Liu, Junyu Chen, Zekai Zhang, Li Yi, LeaF: Learning Frames for 4D Point Cloud Sequence Understanding, International Conference on Computer Vision (ICCV), 2023 查看PDF
6. Liuyu Bian, Pengyang Shi, Weihang Chen, Jing Xu, Li Yi†, Rui Chen†, TransTouch: Learning Transparent Objects Depth Sensing Through Sparse Touches, International Conference on Intelligent Robots and Systems (IROS), 2023 查看PDF
5. Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, Li Yi, HOI4D: A 4D Egocentric Dataset for Category-Level Human-Object Interaction, Conference on Computer Vision and Pattern Recognition (CVPR), 2022 查看PDF
4. Xueyi Liu, Xiaomeng Xu, Anyi Rao, Chuang Gan, Li Yi, AutoGPart: Intermediate Supervision Search for Generalizable 3D Part Segmentation, Conference on Computer Vision and Pattern Recognition (CVPR), 2022 查看PDF
3. Hong-Xing Yu, Jiajun Wu, Li Yi, Rotationally Equivariant 3D Object Detection, Conference on Computer Vision and Pattern Recognition (CVPR), 2022 查看PDF
2. Tianchen Zhao, Niansong Zhang, Xuefei Ning, He Wang, Li Yi, Yu Wang, CodedVTR: Codebook-Based Sparse Voxel Transformer in Geometric Regions, Conference on Computer Vision and Pattern Recognition (CVPR), 2022 查看PDF
1. Hao Wen, Yunze Liu, Jingwei Huang, Bo Duan, Li Yi, Point Primitive Transformer for Long-Term 4D Point Cloud Video Understanding, European Conference on Computer Vision (ECCV), 2022 查看PDF








